教你用逻辑回归和朴素贝叶斯算法识别虚假新闻,小技能大用途!

作者 | Christopher Pease
译者 | Shawn Lee
编辑 | Jane
出品 | AI科技大本营
【导读】识别虚假新闻可以说是 Facebook 等社交网络目前最重视的问题。本文,我们就将介绍如何利用两种机器学习的方法——逻辑回归和朴素贝叶斯分类器,来识别存在故意误导的新闻文章。
自然语言处理( NLP )属于计算机科学领域,它致力于处理和分析任何形式的自然人类语言(书面,口头或其他)。 简而言之,计算机只能理解 0 和 1 ,而人类则使用各种语言进行沟通,NLP 的目的便是在这两个“世界”间搭建沟通的桥梁,这样数据科学家和机器学习工程师能分析大量的人类沟通数据。
那 NLP 如何识别虚假新闻呢?实际上,NLP 会把文章分解成一个个小成分并筛选出其中的重要特征,而后我们搭建并训练模型去识别这其中不靠谱的内容来鉴别虚假新闻。
这次尝试不仅练习了自然语言处理的技能,也学习了一些有效构建强大分类模型的技术。
▌数据清洗
首先从 Kaggle 库中选取一个包含两万篇标记文章的数据集用于测试效果,结果显示,模型在预测标签时的准确度为93%。
在大部分以数据为主体的项目中,第一道工序便是数据清洗。在鉴别虚假新闻时,我们需要处理成千上万篇来自不同领域、有着不同清晰度的文章。 为了有效筛选需要的内容,我们使用正则表达式来提取分析中所需要的字符串类型。例如,这是一行使用 re python 模块的代码:
参阅链接:
https://docs.python.org/3/howto/regex.html#

这行代码会使用空格来替换所有不是字母或数字的字符。 第一个参数,“[^A-Za-z0-9']” ,表示除非符合括号内的指定集,其他内容将全部替换成第二个参数,也就是空格。 一旦我们删除了那些不需要的字符,我们就可以开始进行标记化和矢量化了!
Scikit-learn 是一个令人惊叹的 python 机器学习包,它能承担很多繁重的工作。 特别是 Count Vectorizer 这个函数,它能创建所有被分析文本的完整词汇表,并将每个单独的文档转换为表示每个单词总数的向量。 因为大多数文章并不会包含词汇表里的大部分单词,函数将返回一个稀疏矩阵形式的向量。 矢量化器则允许我们对各种预处理函数和首选的标记器进行集成。
参阅链接:
http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.te
xt.CountVectorizer.html
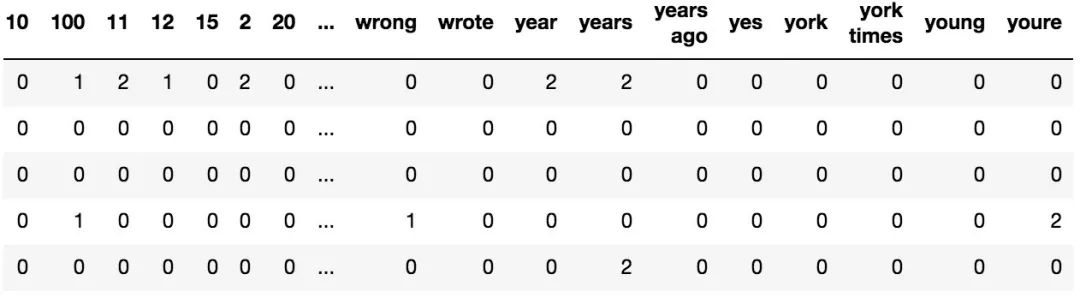
一个被矢量化的文章的示例,每行包含我们初始的1000个特征词的出现次数
在分析新闻的情况下,仅考虑单个单词的方法过于简单,因此我们会允许对双字符或两个单词短语进行向量化。 我们将特征的数量限制为1000,这样我们在通过特征判断真假时就只需考虑文档内最重要的那些特征。
▌特征工程
特征工程是不一个简单的技能,它更像是复杂的艺术形式。 它包含了考虑数据集和域的过程,选择对于模型最有用的特征,以及测试特征以优化选择。 Scikit-learn 的矢量化器提取了我们的1000个基础的 n 元语法( n-gram ) 特征,同时我们开始添加元特征来改进我们的分类。我们决定计算每个文档中的平均单词长度和出现数字的次数,以此提高我们模型的准确性。
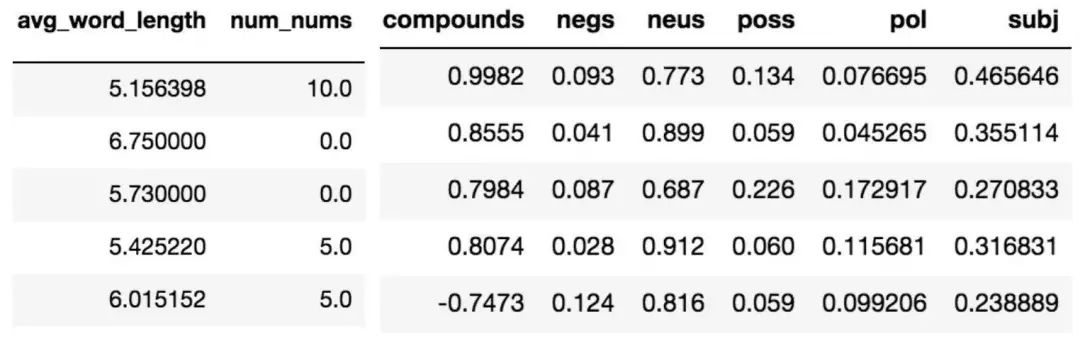
左:各类特征 右:情感得分
情感分析是 NLP 中的另一种分析工具,它可以量化文章中的情绪并评分。我们在这里使用了两个包,TextBlob 和 Natural Language Toolkit 的 Vader 。它们都是分析文中情绪的工具。 Vader 会针对文章的偏激性和中立性进行测量和评分,而 TextBlob 则会测量文章的偏激性和整体主观性。我们原本猜想这些情绪分布会根据文章的真实性和误导性有大幅变化,但在实际情况中我们发现这种差异并不明显。
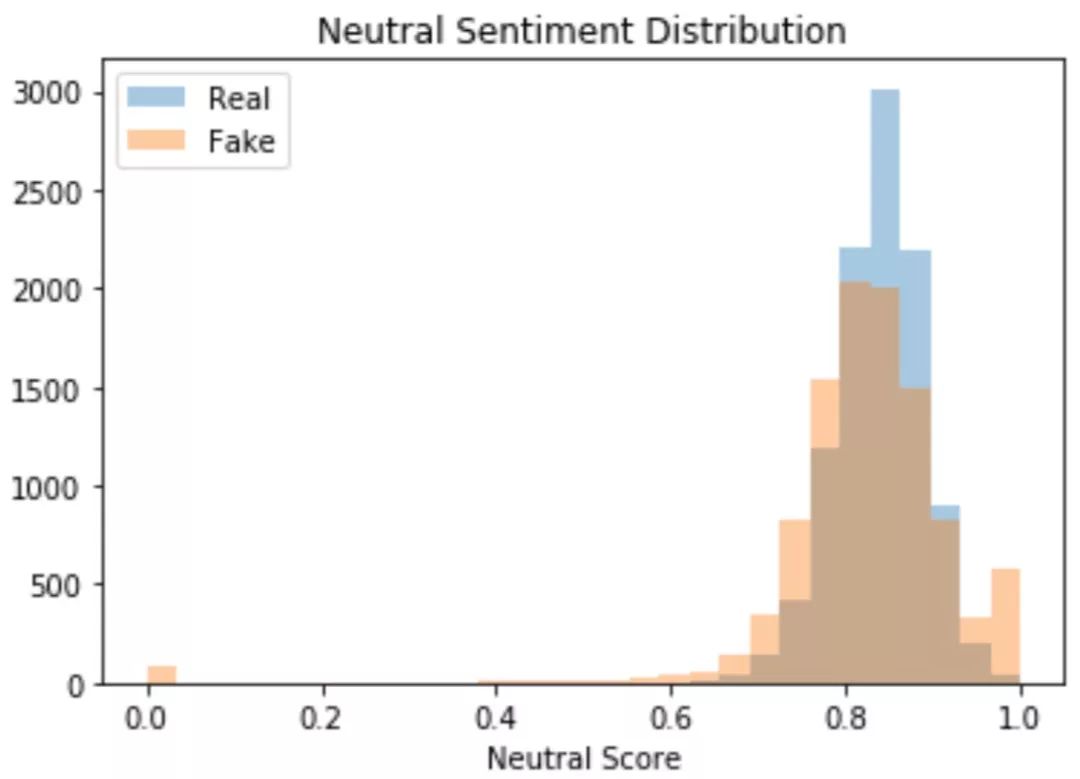
通过 Vader 得出的中性文章情绪的分布,0代表的是完全中立
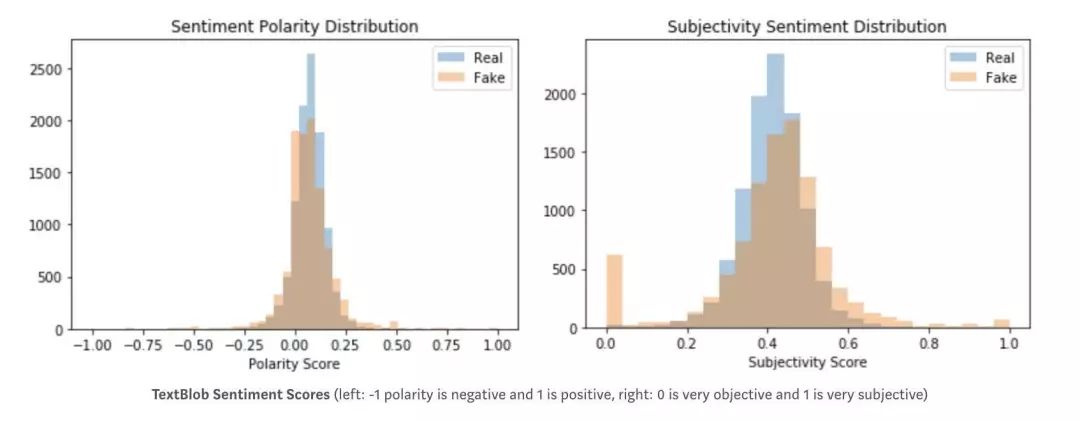
TextBlob 情感得分
(左:-1 代表极性为负,1 代表极性为正;右:0 代表非常客观,1 代表非常主观)
从上图可以看出,通过情感评分的方法不能体现出明显的差异。 然而,我们认为感情分数和分类器两者的综合使用可提高判断的准确率,因此我们决定将它保留在模型中。
▌逻辑回归
我们在这里考虑的系统是仅仅包含真和假两类。 通过给出的相关特征,我们对文章是虚假捏造的概率进行建模。 多项逻辑回归( LR )是这项工作的理想候选者,我们的模型通过使用对数变换(logit transformation)和最大似然估计(maximum likelihood estimation)来模拟预测变量的相关不可靠性的概率。
换句话说,LR 会直接计算后验 p(x|y) , 学习如何给输入的特征分配标签。 这是一个判别法的例子,虽然在技术层面上这并不是一个统计分类,但它可以对分类资格的条件概率进行赋值。SciKit-Learn 的逻辑回归模型提供了一种便利的方法来执行此操作。
参阅链接:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
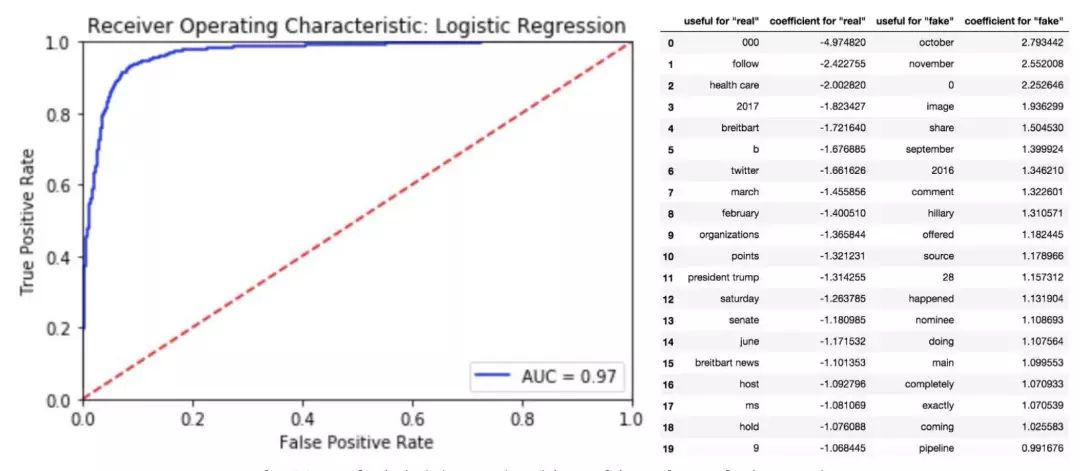
左:逻辑回归的 ROC 曲线;右:回归中排名前二十的特征
▌朴素贝叶斯分类器
我们的第二种方法是使用朴素贝叶斯算法( NB )算法,虽然它很简单,但是它十分适用于这个模型。通过假设特征之间的独立性,NB 从每个标签文章中学习联合概率 p(x,y) 的模型。基于贝叶斯规则计算得到的条件概率,模型会依据最大概率对文章进行标签分配并预测真伪。与前面提到的方法不同,这是一个生成分类器的例子。
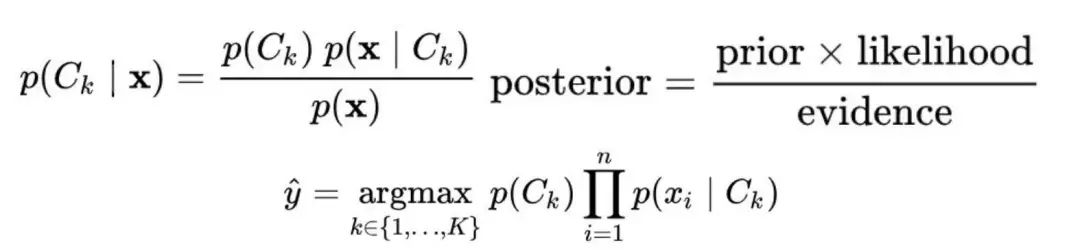
贝叶斯分类器,使用 MAP 决策规则
在这种情况下,我们考虑是一个多项事件模型,它能最准能确地表示我们的特征分布情况。 正如预期的那样,其结果与逻辑拟合所得出的结论十分接近
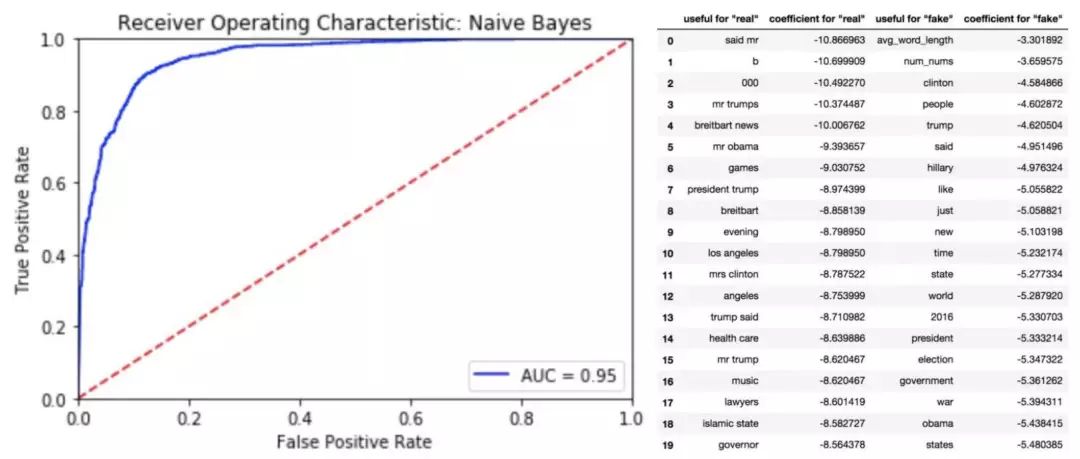
左:多项朴素贝叶斯的 ROC 曲线;右:朴素贝叶斯分类器中排名前20的特征
▌结论
机器学习可以有效地识别以虚假新闻形式存在的错误信息。 即便是没有标题来源等上下文信息,仅正文内容也足以用来进行分析和学习。 因此,这些策略可以很简单地应用于那些没有额外描述的文档。 虽然单独使用情绪评分法并不能准确地判别假新闻,但当它与其他功能一起使用时,则可以提高分类器的准确性。未来可以尝试将其与其他流行的模型进行比较,比如支持矢量机。
原文链接:
https://towardsdatascience.com/machine-learning-tackles-the-fake-news-problem-c3fa75549e52
--【完】--
AI科技大本营希望找到在汽车、金融、教育、医疗、安防、零售、家居、文娱、工业等 9 大行业的最佳 AI 应用案例,记录 AI 时代影响人类发展的变革性产品/解决方案。
如果您有优秀的 AI 产品/技术解决方案,欢迎【扫码提交】,参与评选。

点击「阅读原文」,查看案例分享者特别奖励




