VALSE 2018年度进展报告 | 深度神经网络加速与压缩
点击上方蓝字关注我!

2018年4月下旬在大连举办的VALSE 2018大会上,中科院自动化研究所的老师介绍了深度神经网络加速和压缩最近一年的进展和趋势。
以下内容是在PPT的基础上进行的整理,并加入了个人理解部分,不完全代表讲者本身观点。
研究背景
如下图所示,是常用的几种卷积神经网络计算复杂度的情况。我们发现网络层数越来越多,计算复杂度也越来越大。
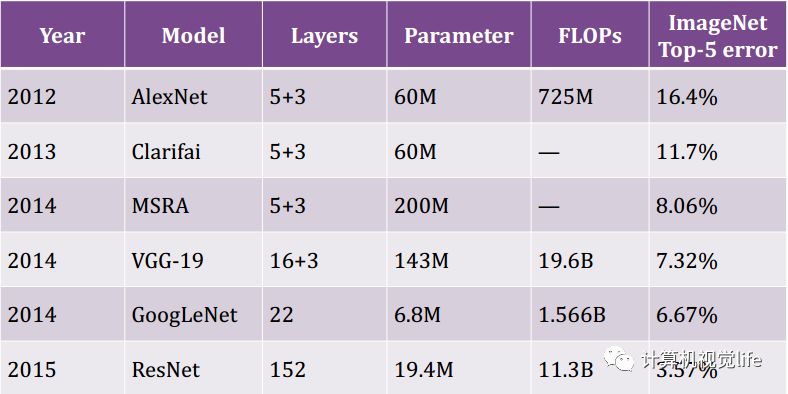
过去我们的深度神经网络大部分都是在GPU上或高性能的CPU上做计算,对加速压缩的需求没有那么强烈。但当深度神经网络在应用到具体场景时,有很多情况下必须在智能手机、穿戴设备等嵌入式设备上使用。这些嵌入式设备对模型体积、计算性能、功耗等方面都有比较严格的要求,这就限制了上述对计算性能要求较高的深度神经网络模型的应用。

基于此,深度神经网络加速与压缩的研究目的是:在保证现有模型的性能基本不变的前提下,采用一些方法能够有效的大幅减少计算量、降低模型的体积,那就再好不过了。
加速与压缩年度学术进展
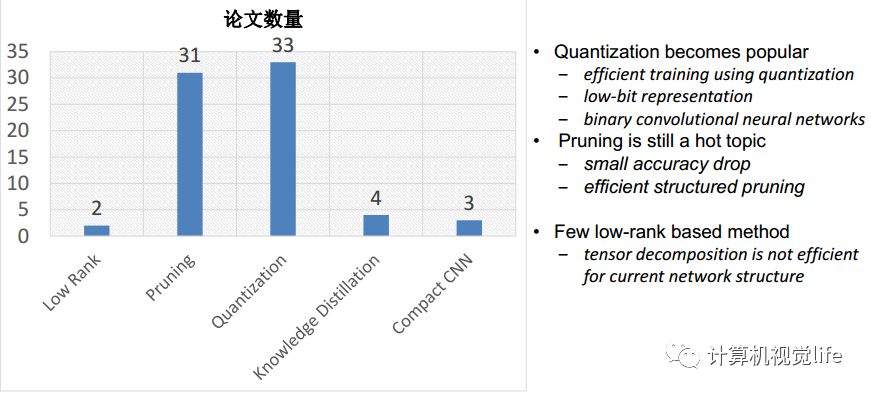
深度神经网络加速与压缩主要有以下几种方法:Low-Rank、Pruning、Quantization、Knowledge Distillation、Compact Network Design。如下图所示是最近一年几个的顶级会议收录的加速与压缩方面的论文情况。可以看到Pruning、Quantization是该领域研究的热点。
下面分别介绍。
卷积神经网络主要的计算量就在于卷积计算。卷积计算本质就是矩阵分析问题。利用SVD可以有效的减少低维矩阵的运算量。所以早期MSRA在TPAMI上发表了SVD进行网络加速的方法。而对于高维的情况,一般使用CP分解、Tucker分解、Tensor Train分解、Block Term分解方法。

不过,用矩阵分解进行模型压缩和加速的工作越来越难做了。原因是:矩阵分解是一种非常成熟的方法,方法直观显而易见,比较容易做,另外就是现在很多网络都是1x1的小的卷积,已经比较快了,用矩阵分解很难进行加速和压缩。

该方法就是把一些网络连接剪掉,剪掉后网络复杂度、模型大小就会降低很多。早期的工作有一种随机剪枝方法,对硬件非常不友好,而且不一定能够起到较好的网络压缩的效果。而最近大家采用比较多的是结构化的、滤波、梯度等prunning方法。

下面分别展开简单介绍一下。
ICML2017的一篇论文利用组稀疏的方法来对权重进行稀疏化,再加上一些exclusive Sparsity可以得到一个较好的剪枝结果。

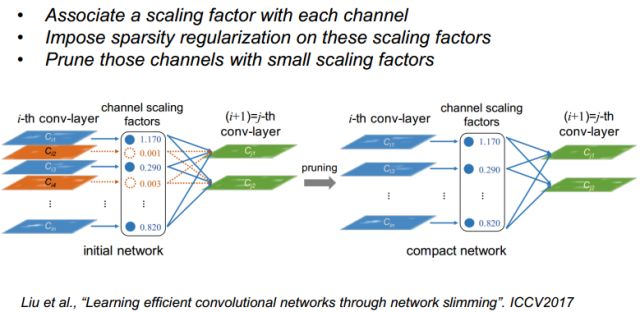
还有一种就是对feature map上做一些pruning的工作,ICCV2017的一个工作是给每个feature map加了尺度因子,根据尺度因子大小进行pruning,剪掉值比较小的从而对channel进行简化,实现网络的瘦身。
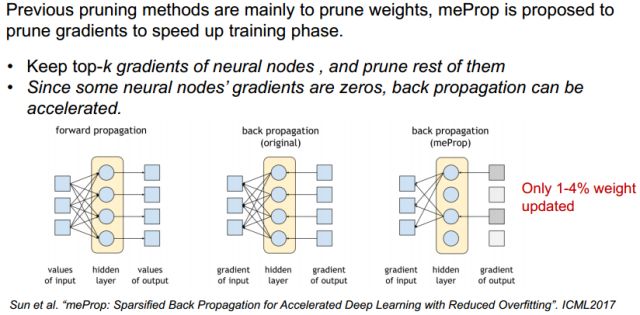
前面都是对inference进行的pruning,能否在training的时候引入pruning,加快training的过程?
ICML2017的一个工作是在training的BP过程中对梯度幅值进行了分析,如果幅值比较小,就去掉,简化了BP的传播,从而速度更快,结果显示仅仅更新1-4%的权值就可以达到接近原始的效果。
量化主要分为以下几种方法:

分别展开讲一下。
低比特量化函数通常是不连续的,这样求梯度会比较困难,AAAI2018的一个工作把低比特量化转化为ADMM可以优化的一个目标函数。

AAAI2018还有一个工作就是利用hashing求解量化的二值权重:

前面都是考虑对权重的量化,能否考虑将权重和activation一起量化?
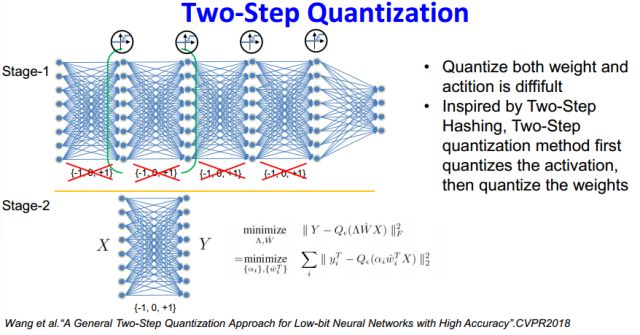
受到两步hashing的启发,CVPR2018的一个工作进行了两步量化工作,第一步先对activation进行量化,然后第二步再对权重进行量化。
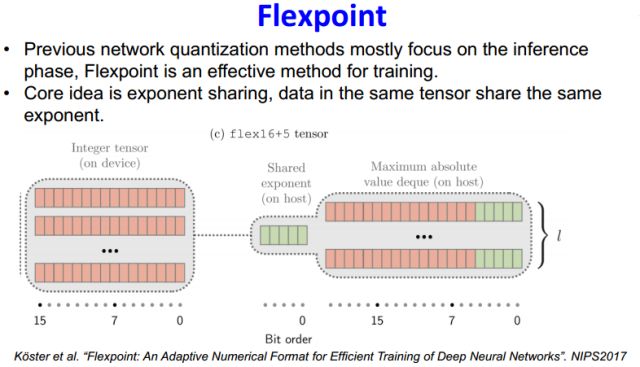
前面都是对inference过程的量化,同样training过程也可以量化,如下是NIPS2017 的一个工作Flexpoint,其核心思想是把指数项进行共享,把浮点问题转化为尾数的整数定点运算,从而加速训练过程。
很多时候训练深度神经网络会用到分布式计算来加速训练。但分布式计算时有个问题,每个分布式服务器节点要和中心服务器做一个大量的梯度信息的传输,这会受到带宽的限制。NIP2017的这个工作把传输的梯度展开为一个ternay梯度来解决。

Knowledge Distillation最早是Hinton大神做的一个工作,还有后来的FitNets。Knowledge Distillation存在的两个关键问题是:第一,如何定义知识?第二:怎样优化损失函数来度量teacher和student网络的相似度?

下面是Knowledge Distillation方面的几个最新的进展。

下图是是该领域几种方法的对比:

前面介绍的所有方法是针对原有的比较大型的网络的量化、剪枝等进行加速和压缩。那么能否从一开始就设计一个又小又快又好的网络呢?这就是紧致网络设计的目的。
这里主要介绍三个工作:

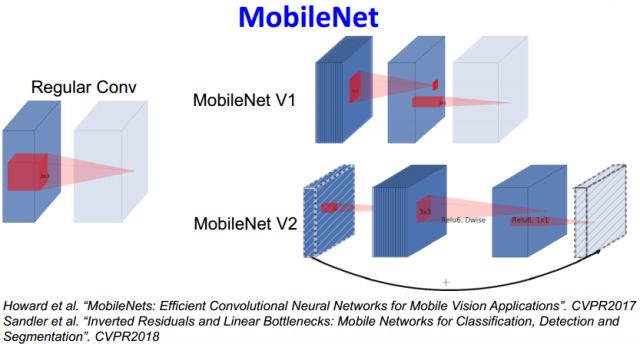
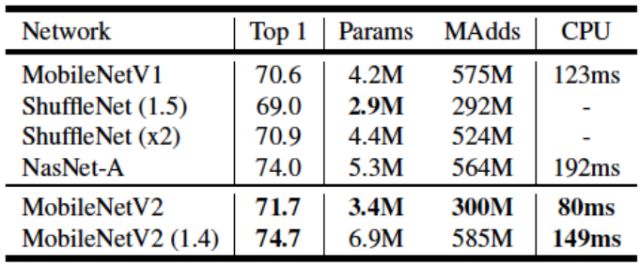
Google 在17年底和18年连续推出了的MobileNetV1和MobileNetV2。其核心如下图所示:
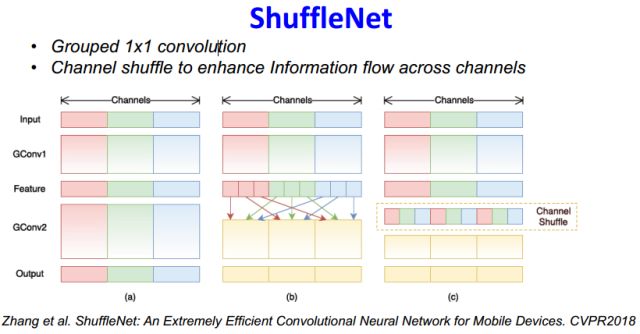
shuffleNet也是基于类似原理,把1x1卷积进行分组计算,但这会使得不同channel间信息交流比较少,因此加了shuffle随机扰乱的过程,增加channel间信息的交流。
上面几种方法的比较结果:
未来研究趋势
趋势1:Non-fine-tuning or Unsupervised Compression
目前大部分加速压缩方法都需要一个fine-tuning过程,还得有一定量的原始带标签的训练样本,这在很大程度上限制了使用场景。未来研究趋势是不需要fine-tuning或者不需要监督的方法。
趋势2:Self-adaptive Compression
目前加速和压缩过程中通常涉及到很多的经验参数。未来研究趋势就是减少经验参数的使用,自适应进行压缩加速,提高泛化能力。
趋势3: Network Acceleration for other tasks
目前大部分加速压缩方法还是集中在物体分类问题上,未来的研究趋势是逐渐扩展到其他领域(如物体分割)。
趋势4: Hardware-Software Co-design
加速和压缩算法与硬件设计关系非常紧密,未来软硬件的协同设计是一个趋势。
趋势5: Binarized Neural Networks
二值神经网络的研究越来越成熟,将来会成为一个更热门的研究方向。
温馨提示:PPT可以在官网下载,也可以在公众号菜单栏下回复:加速压缩,即可获取。
点击图片查看相关阅读


注:转载请联系simiter@126.com,注明来源,侵权必究。





