近20年3867篇AI论文大调研:有缺陷的指标被滥用,好的指标被忽视

编辑 | 陈彩娴

 图1:Papers with Code每年发表论文数量,y轴对数缩放。
图1:Papers with Code每年发表论文数量,y轴对数缩放。
 图2:每个AI子流程的基准数据集数量,x轴按对数比例缩放。
图2:每个AI子流程的基准数据集数量,x轴按对数比例缩放。
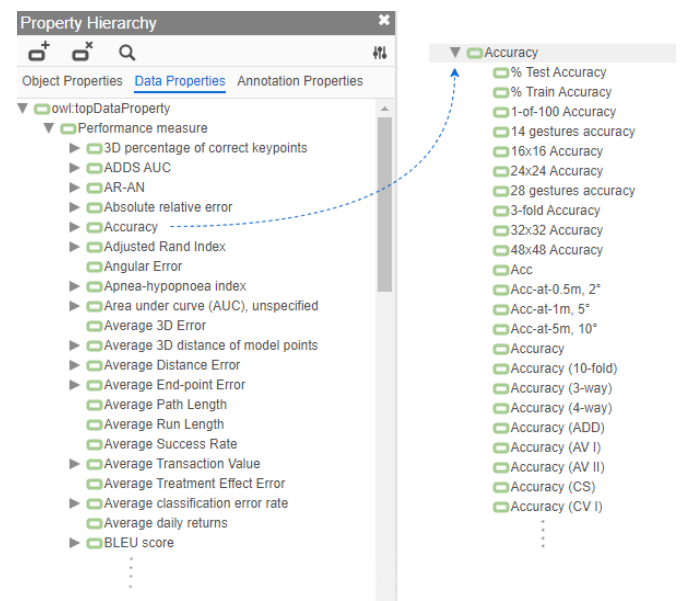 图3:指标层次结构。图左显示了top-level指标列表部分;图右显示了“准确率”的子指标列表部分。
图3:指标层次结构。图左显示了top-level指标列表部分;图右显示了“准确率”的子指标列表部分。

2
最常用的指标近乎过度使用


 图6:仅将top-level指标视为不同指标(蓝色条)时,以及将子指标视为不同指标(灰色条)时,不同指标数的基准数据集的计数。
图6:仅将top-level指标视为不同指标(蓝色条)时,以及将子指标视为不同指标(灰色条)时,不同指标数的基准数据集的计数。
 BLEU分数用于各种NLP基准测试任务,例如机器翻译、问答、摘要和文本生成。ROUGE指标主要用于文本生成、视频说明和摘要任务,而METEOR主要用于图像和视频说明、文本生成和问答任务。
BLEU分数用于各种NLP基准测试任务,例如机器翻译、问答、摘要和文本生成。ROUGE指标主要用于文本生成、视频说明和摘要任务,而METEOR主要用于图像和视频说明、文本生成和问答任务。
3
某些指标被过度简化
4
最常用的指标存在缺陷
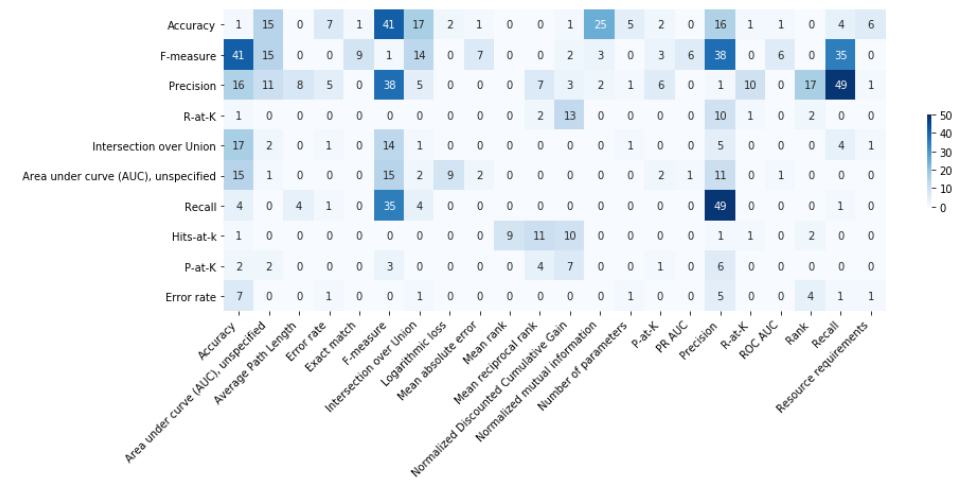 图7:10个最常用的top-level分类指标的共现矩阵。
图7:10个最常用的top-level分类指标的共现矩阵。
 图8:10个最常用的NLP指标的共现矩阵。
图8:10个最常用的NLP指标的共现矩阵。

登录查看更多
相关内容

Arxiv
0+阅读 · 2020年10月15日
Arxiv
0+阅读 · 2020年10月14日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年10月15日
Arxiv
0+阅读 · 2020年10月14日