2019腾讯广告算法大赛-冠军之路
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:王贺
https://zhuanlan.zhihu.com/p/72762888
Top1 开源代码在此:
https://github.com/guoday/Tencent2019_Preliminary_Rank1st
写在前面
历时三个月腾讯广告算法大赛已经告一段落,在前两届成功经验的基础上,今年大赛在赛题专业性和赛事体验上都有了更大的提升,进而吸引了更多海内外优秀选手参加,最终报名人数高达10,571人。本届算法大赛选手的构成也更加多元化,其中进入复赛的TOP 20队伍就涵盖了清华大学、华南理工大学、浙江大学、东南大学、北京大学、西安电子科技大学、北京航空航天大学、厦门大学等16所顶尖院校的37名学生,此外还有14名来自海内外工业界的精英选手。
很幸运能从去年的11名一跃成为今年的冠军,这里是少不了团队的配合,感谢队友郭达雅和刘育源的带飞。
此次答辩上还见到了两位在数据挖掘领域享有盛誉的学术界权威——伊利诺伊大学芝加哥分校杰出教授俞士纶(Philip S. Yu)和亚利桑那州立大学计算机科学与工程教授刘欢(Huan Liu)进行现场分享,收获颇丰。



比赛虽然过一段了,可是我们的学习是不能停的,需要做的就是对比赛进行一个完整的总结,去学习更多优秀的方案。在这里我也将对自己所有的分享进行一个梳理,希望帮助大家能从中学习到不一样的东西。同时也帮助未参加本次大赛的同学们对本赛题有更多的理解,并学习到优秀的方案。
正文
1. 初次接触本赛题
本部分内容可以帮助大家对赛题有个基础的理解,并且能够完成基本的建模。不仅如此,文章中还介绍了三个重要的提取特征思路,并对其取名“三刀流”,这三种方法也是贯穿整个比赛的始终。
https://zhuanlan.zhihu.com/p/63718151


目前最优得分结果是规则+模型的分数
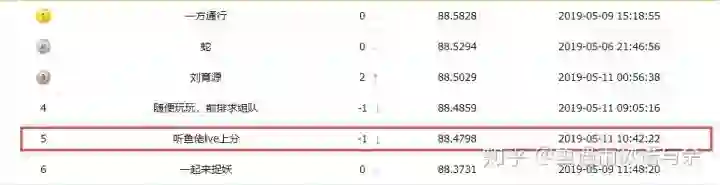
写在前面
这试腾讯的第三届广告算法大赛,也是我第二次参加,18年很意外的拿到第十一名,虽然距离决赛只差一步,不过结果还是很令我满意的,毕竟去年的我只是初打比赛不久的小白。作为过来人,我想在此分享下我的基本解题思路。让我们一起打比赛吧!!!
1.1 赛题分析
这次比赛完全不同于17和18年的CTR方面问题。本次竞赛将提供历史n天的曝光广告的数据(特定流量上采样), 包括对应每次曝光的流量特征(用户属性和广告位等时空信息)以及曝光广告的设置和竞争力分数;测试集是新的一批广告设置(有完全新的广告id, 也有老的广告id修改了设置), 要求预估这批广告的日曝光。
第一眼:看到这个赛题我想到了两点:1.这是一个回归问题;2.和时间有关,或许可以当成时间序列问题来解决。然后我就开始回想相关的比赛有哪些,常用的解决方法有哪些。
第二眼:看数据到数据时,其实并没有想到数据里面居然有很多需要进行清洗的。比赛前两天写好的baseline,然后一看到具体数据,完全懵了。如何构建训练样本都成了一个问题。主要从三个方面看数据:1.是否缺失 2.各类别分布 3.大概能构造什么特征,这也就完成了基本的工作。另外由于数据比较大,每次读取很麻烦,尝试h5格式,飞一般的感觉!!!(pandas.DataFrame.to_hdf - pandas 0.24.2 documentation)
第三眼:看评价指标,比较特别,SMAPE还好点,主要是单调相关指标,然后跟我来读下描述“由于竞价机制的特性,在广告其他特征不变的前提下,随着出价的提升,预估曝光值也 单调提升才符合业务直觉。”公式:
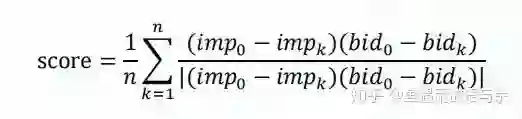
显而易见,预估曝光值和出价成正比时,这里才能得到高分。举个例子:有三个相同广告id的样本,其出价是{1,10,100},曝光量是{1,1.1,1.2},可以看出随着出价的提升,曝光值也在提升,符合单调性,故满分。想想看,我们是很容易得到60分的,然后仅使用一行代码就能得到79+。
有了初步的了解,我开始对问题进行建模,一起来构建baseline(当然,这里是没有代码的)
1.2 问题建模
我发现,即使对赛题有了一定理解,可是还不知道怎么进行问题建模,这个怎么没有给标签啊,该怎么构建标签呢?
这里,我给出三步介绍,从而有一个初步的思路
第一步:简化问题。当拿到数据知道如何建模,不要想的太复杂,先得到一个基础结果,然后再慢慢改进。目标是广告日曝光值,我们可以通过日志数据统计得到,groupby(['广告id',‘请求月’,'请求日'])进行组合统计出现频次即刻。
那么问题来了,相同广告的出价一直在变,要不要加上出价进行组合呢?官方解释出价会动态调整,看来是个不确定的值,所以我们先放一放,不考虑出价这个特征。
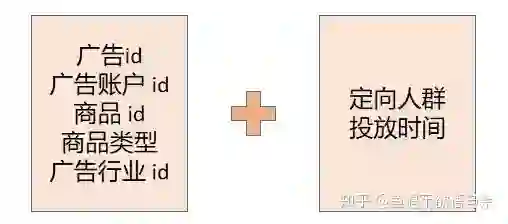
第二步:原始特征。看看有什么可以用的特征,主要是比较稳定,不会有太多问题的特征,所以我给出的原始训练特征有广告id,素材大小,广告行业id,商品类型,商品id,广告账户id,恰好测试集都包含这些特征,然后构造好的广告id和标签数据与广告静态数据经行合并。这样特征就对应上了。
第三步:交叉验证。特征构造好了,接下来就需要进行线下验证。这里给出两个验证方案,1.由于是时序问题,为了避免数据泄露,常选择训练集最后一天进行线下验证。2.K-folds交叉验证,这个线下应该会比方案1线下好些。
这样走下来,你就可以直接训练模型了,记住“先得到一个结果,然后再不断地调整优化”(这是吴恩达说的,可不是我说的)
1.3 探索性数据分析(EDA)
1.3.1 离群点处理
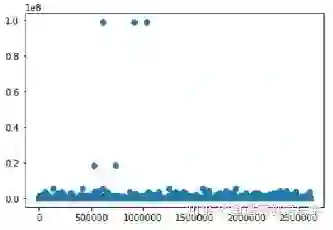
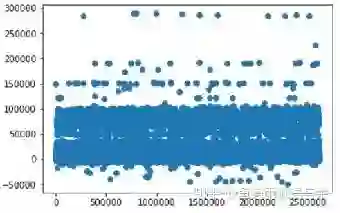
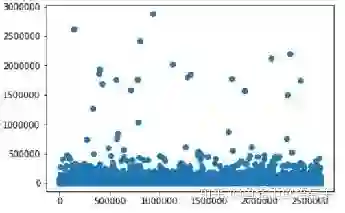
1.3.2 时间的重要性
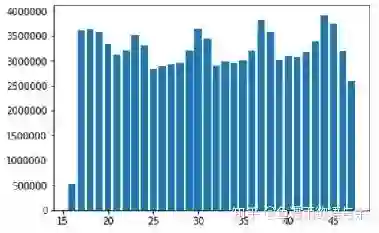
可以看出不同时间得总曝光量是不同的,所以我们可以选择保留请求时间特征。
1.4 特征工程
当然,原始特征远远不够的,我们还需要挖掘更多特征。接下来要使出我的“三刀流”特征构建大法。

第一刀:目标编码,一切问题都可以考虑根据目标变量进行有监督的构造特征。此题也不例外,目标变量为广告日曝光值,那么我们就可以构造与目标有关的特征。然而这会存在一个问题,特别容易过拟合。
记得OGeek比赛刚一开始,我的好友小幸运刷刷刷的就分享了一个baseline,比较简单,帮助很多人很快进入到比赛。但是也让很多人陷入到困惑,为什么线下非常好,线上却崩了。究其原因是进行目标编码的时候没有防过拟合处理,导致数据泄露。有效的办法是采用交叉验证的方式,比如我们将将样本划分为5份,对于其中每一份数据,我们都用另外4份数据来构造。简单来说未知的数据在已知的数据里面取特征。

https://zhuanlan.zhihu.com/p/46482521
第二刀:统计特征,一切皆可统计,类别特征可以计数统计,可以nunique统计,数值特征可以均值统计,最大最小,中位数等。官方解释把该问题抽象成一个符合正相关性的CTR预估问题,也就是说pctr越大,其曝光量就应该越大。既然广告曝光预测问题不好理解,我们可以将其转为CTR问题。这样就可以根据相关赛题,联想到很多特征。

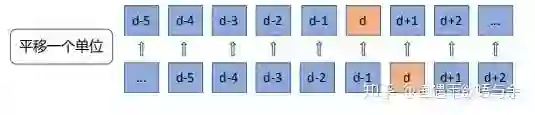
第三刀:历史平移,对于这种包含时间的时序问题,测试集的具体数据是不知道的,我们可以使用前n天来曝光量,或者是pctr作为测试集的特征。如下图,d-1天的信息作为d天的特征,这种相近日期的数据相关性是非常大的。在群里也能看到很多人直接用前一天的曝光量才填充,这种规则就能得到很高的分数。
1.5 模型选择
作为基础的模型,lightgbm和xgboost都非常合适。为什么选择这两个模型呢,主要因为树模型对特征处理的要求不高而且效果也相当不错,不管是类别特征,连续特征效果都很友好,同时多缺失值也可以训练,不需要填充。(有时缺失值也是有意义的,随意填充可能导致预测结果变差)
2. 用腾讯大赛来入门
如何进行一场数据挖掘算法竞赛
https://www.zhihu.com/lives/1101583435449151488
虽然都说本次比赛门槛比较高,但并不失为接触真是业务并入门算法大赛的好机会。比赛初期我也进行了我的第一次live分享,依“2019腾讯广告算法大赛”为例,介绍在进行算法中需要做那些准备。并从七部分进行分享
1. 为什么要参加数据挖掘竞赛?能带来什么?
2. 参加竞赛需要哪些基础知识和技能?
3. 如何选择适合自己的竞赛?
4. 竞赛中的几个主要模块
5. 在竞赛过程中最为重要的事情
6. 好的赛后总结比竞赛过程更重要
7. 竞赛案例分享(天池「全球城市计算AI挑战赛」)
从我的经历和经验总结,并结合实际的案例来理解并实践所讲内容。
3. 初赛前的尝试
没到最后一刻,我们都还有机会。
本部分写在初赛A榜即将结束前,分享了比赛中尤为重要的内容。也是从三点来介绍的,这也是在比赛中需要掌握的技能。并且分享了一些能够尝试的方法,以及我的基本建模方法,从中帮助选手进入复赛。
https://zhuanlan.zhihu.com/p/65418206
写在前面
初赛A榜即将结束,同时组队时间也快要结束,对于还未组队的小伙伴,我的建议是找些分数差不多的童鞋组队,自己的思维总是局限的,组队后不仅可以提分,还能交流学习。

3.1 正文
初赛最后阶段至关重要,我觉得有三件事情一定要做
1. 多关注群消息
2. 寻找合适队友
3. 最后尝试机会
3.1.1 多关注群消息
(字里行间都是戏)
qq群是大佬飙戏的地方,当然也会有很多有用的信息,这就需要我们多加留意。
模型+规则,能上天
可能很多人一开始只是使用模型去上分,却忽略的规则的重要性,我和队友对比过lgb和nn结果差异很大,可是融合并没有上分,这也说明了模型结果其实很差的。可是和规则融合却能从87+提升到88+。同时群里很多大佬给出了规则方法,以及如何进行模型与规则的融合。
规则方法:历史平均来填充旧广告id的曝光量,新广告id曝光量用广告size、商品id等特征对应历史平均来填充。调整单调性。
规则方法:前一天的曝光量来填充旧广告id的曝光量,新广告直接填充0。调整单调性。
模型+规则:直接加权融合,或者模型结果填充新广告id的曝光量,规则结果填充旧广告id的曝光量。
更细致的方法需要你来挖掘!!!
userdata用了能提分
这个用了确实上分了,而且是非常的高的,准确的说是用了用户id的信息,其它并没有用。所有用到userdata里面其它信息的同学请联系我哦!
3.1.2 寻找合适队友

最近在排行榜可以看到很多分数相同的队伍,这也说明大佬们已经确定自己的队伍了,作为初次参加比赛的童鞋们也该找自己的队伍了。正所谓“不是一个人的王者,而是团队的荣耀”,我钻石二求三排,那么来了两个青铜可以三排打排位吗?或者两个王者的三排打排位吗?显然不行,段位相差太多!(杠精请闪远,你是小姐姐我也没办法)所以你要在群里找和你分数差不多的童鞋组队。
那么队伍成员分数都很一般就没有翻盘机会了吗?并不一定,方法是寻找有差异的队友,比如你是树模型,你就可以找做规则的童鞋,或者是做nn的。毕竟lgb+规则能提升近1个点,也就是从86到87,87到88。
3.1.3 最后尝试机会
未到最后,每个人都是有机会进去复赛的,或许前排都过拟合A榜也说不定呢。
我的建模思路
我的是18w左右的训练集,广告id的选取来自广告操作表,然后再构造日曝光量。具体操作如下:
1.将广告操作表中update_time==0的出价、定向人群、投放时段信息与广告静态表merge。
2.对日志数据中的广告id构造日曝光量得到新的数据集data。
3.将data与广告静态表进行merge,并给缺失的投放时段填充-999,这里并未将投放时段展开。
4.data=data.loc[(data.投放时段!=-999)]
这样下来就会有和我一样的训练集了,当然可能不适用每个人,毕竟比起大多数人这个操作时非常粗糙的。
4. 初探初赛冠军
在本部分,讲到了我们团队在初赛中的方案,当然保留了部分trick。从初始建模、特征工程、模型选择、规则尝试四个方面进行分享。其中很多的点都在复赛有所保留,文章也是可以帮助大家学习基本分初赛方案。
https://zhuanlan.zhihu.com/p/66728742
写在前面
感谢队友带我carry,有幸拿到初赛的冠军,在这里我也将初赛思路做一下分享,一是帮助进行复赛的同学扩展些思路,二是帮助大家能从这次比赛中学习到不一样的东西。比赛的目的就是为了学习,很乐意与大家交流。

接下来将从初始建模、特征工程、模型选择、规则尝试四个方面进行分享。
4.1 正文
4.1.1 初始建模
这里主要是训练集的构建,我的构建方式一直比较简单,主要选择广告操作表中广告创建时间有出价,定向人群和投放时段的广告id,这是第一部分的广告id,第二部分是三月份出价唯一的广告id,然后将这两部分广告id结合起来作为最终训练集广告id,然后再构造每天的曝光量。最终25w训练样本。也是我得到最高单模分数(86.4)的建模方法。
4.1.2 特征工程
1. 数据预处理
首先删除了异常样本,包括出价异常,ecmp相关异常,pctr异常,这里值的是离群点。然后删除了重复样本,主键为请求id、请求时间和广告位id。
2. 特征提取
初赛:
虽然题目是预测广告日曝光量的,但是和转化率也有很大的关系,除了目标不同,特征很多都是可以按ctr问题来构造特征。
一个模型既有细粒度的特征,又有粗粒度的特征,细粒度的特征增强模型的刻画能力,粗粒度的特征保证模型的泛化能力。细粒度的特征对活跃用户比较好,可以更精细地刻画他的喜好,提供更个性化的商品排序;而粗粒度的特征是为了服务不活跃用户甚至是新用户,用大数据中总结出的一般规律来提供商品的排序。有了这样一个认识,我们就可以构造很多特征,粗细结合,整体局部。
构造的特征主要分为三个部分,五折交叉统计、历史平移和CountVectorizer。
使用全局统计用来得到整体情况,然后为了降低过拟合的风险,而是用五折交叉统计。
历史平移用来过去历史信息,比如历史曝光量,历史pctr等。
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。对于多值特征,最方便的展开方式就是使用CountVectorizer。从去年的腾讯比赛,以及很多比赛都会使用到这个操作,简单易用,效果显著。
复赛:
对于建模的思路不同,我们构造的特征也有很大的区别。
4.1.3 模型选择
初赛和复赛我们都使用了nn和lgb。
NN:
nn我们选择的是nffm,当然我们对其进行了改进。主要是对数值特征的输入进行修改。(具体方案复赛结束后分享)
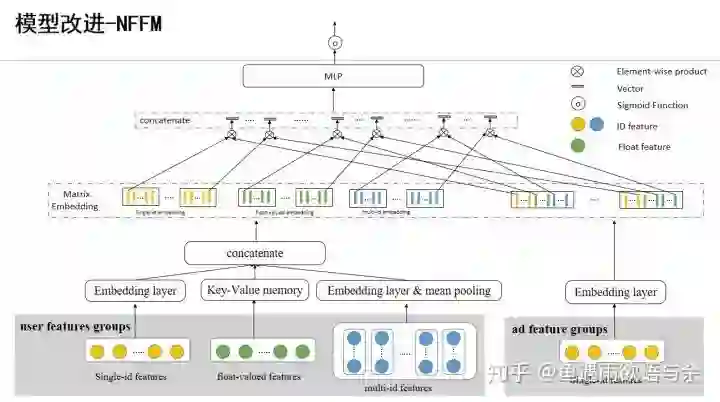
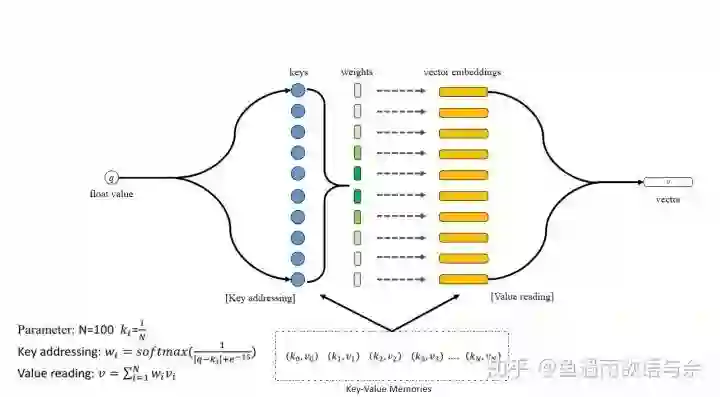
Lightgbm:
这个没什么好说的,使用起来方便,不需要对特征做过多的处理。
4.1.4 规则尝试
在规则方面我们考虑更多的是旧广告,新广告完全由模型来预测。
初赛基本:前一天的曝光量来填充旧广告id的曝光量,新广告直接填充0。调整单调性。
复赛基本:前一天的竞争胜率*当天请求集合数目,新广告直接填充0。调整单调性。
4.2 写在最后
复赛相对于初赛还是由很大的不同的,可以看作回归问题,这也就成了预测竞争广告能否被曝光的问题,最后相加起来构成日曝光量。即广告的竞争力越大,越容易被曝光,越来越像CTR问题了。当然,还是可以按照初赛的方法去做的,只从竞价广告队列中提取被曝光的广告,最终预测曝光量即可。如果只是初赛方案,模型只能到85+,所以在建模方法上还需要大家做更多的尝试,不同建模的gap感觉不是一两个强特能弥补的。
5. 初赛完整方案
本文将从初赛的赛题分析、赛题难点、探索性数据分析、数据预处理、特征工程、算法建模、模型融合等部分全面介绍初赛冠军方案。文中将具体部分结合代码进行讲解。可以带大家学习到初赛冠军的方案,并对应代码讲解。
写在前面
在本篇文章中,我将给出2019腾讯广告算法大赛的基本思路分享,将包括初赛方案分享和复赛方案分享,由于赛题的特殊性,初赛和复赛做法上的差异非常大,如果只从特征上来看,初赛和复赛的特征完全不一样。
幸运的是我们团队在初赛和复赛均是冠军,在后续文章中我也将详细解读赛题,并从赛题分析、数据探索性分析、特征工程、算法建模进行分析,同时我也将分享更多从赛题中映射出来的知识点和经验分享。(决赛后分享)
主要内容:
初赛:赛题分析、赛题难点、探索性数据分析、数据预处理、特征工程、算法建模、模型融合
5.1 正文
5.1.1 赛题分析
腾讯效果广告采用的是GSP(Generalized Second-Price)竞价机制,广告的实际曝光取决于广告的流量覆盖大小和在竞争广告中的相对竞争力水平。其中广告的流量覆盖取决于广告的人群定向(匹配对应特征的用户数量)、广告素材尺寸(匹配的广告位)以及投放时段、预算等设置项。而影响广告竞争力的主要有出价、广告质量等因素(如 pctr/pcvr 等), 以及对用户体验的控制策略。通常来说,基本竞争力可以用千次曝光收益 ecpm = 1000 * cpc_bid * pctr = 1000 * cpa_bid * pctr * pcvr (cpc, cpa 分别代表按点击付费模式和按转化付费模式)。综上,其中前者决定广告能参与竞争的次数以及竞争对象,后者决定在每次竞争中的胜出概率。二者最终决定广告每天的曝光量。本次竞赛将提供历史n天的曝光广告的数据(特定流量上采样),包括对应每次曝光的流量特征(用户属性和广告位等时空信息)以及曝光广告的设置和竞争力分数;测试集是新的一批广告设置(有完全新的广告id,也有老的广告id修改了设置),要求预估这批广告的日曝光 。( 出于业务数据安全保证的考虑,所有数据均为脱敏处理后的数据。)
可以看出,本次赛题的目标是通过对广告的历史信息预测未来某一天广告的日曝光量,我们可以将其看作是回归问题,更进一步可以看出时间序列回归问题。
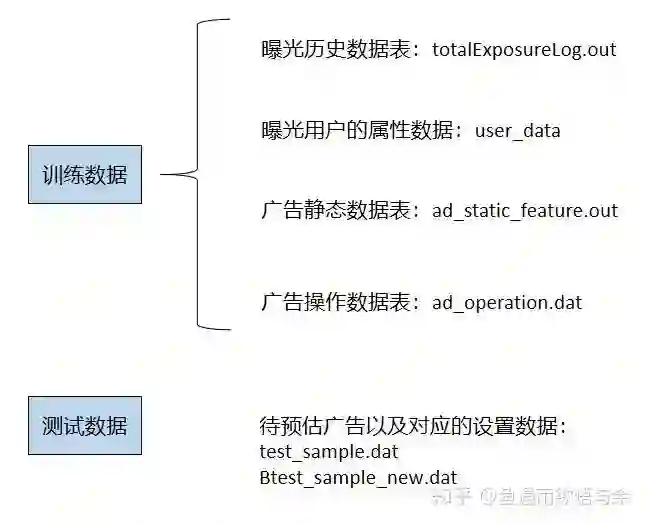
官方给出的文件有曝光历史数据表、曝光用户的属性数据、广告静态数据表、广告操作数据表和待预估广告数据表。
评价指标分别为smape和单调性得分,其中smape和常见的mae和mse有一定的区别,主要是来评估准确性的,即smape越小越好。主要是单调相关指标,由题目描述“由于竞价机制的特性,在广告其他特征不变的前提下,随着出价的提升,预估曝光值也单调提升才符合业务直觉。”
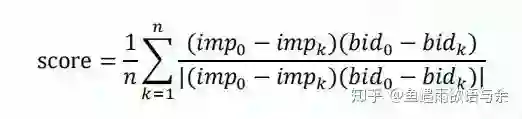
我们是很容易得到60分的,然后仅使用一行代码就能得到79+。代码如下:
test.set_index('sample_id')[['ad_id', 'bid']].groupby('ad_id')['bid'].apply(lambda row: pd.Series(dict(zip(row.index, row.rank()/6)))).round(4).to_csv('submission.csv', header=None)5.1.2 赛题难点
在这一小节我们对本次赛题中存在的难点进行分析和总结,我们将本次赛题的难点归结如下三点:
1)赛题并没有给出明确的训练集和标签,那么如何构建训练集和标签成为第一个需要翻越的障碍。
2)测试集是新的一批广告设置(有完全新的广告id,也有老的广告id修改了设置),面对新广告该如何预测。
从A榜到B榜,从初赛到复赛,新广告的占比越来越大,能够同时兼顾新旧广告成为取得胜利的关键。
初赛A 总广告:1954 旧广告: 1361 新广告:593 新广告占比:30.348%
初赛B 总广告:3750 旧广告: 1382 新广告:2368 新广告占比:63.147%
3)对于最后提交结果,如何保证出价单调性,而不是最终对结果进行修正。
如果只是在最后进行单调修正,比如,有三个相同广告id的样本,其出价是{1,10,100},曝光量是{1,1.1,1.2},可以看出随着出价的提升,曝光值也在提升,符合单调性,故满分。虽然单调性上满分,但这并不是实际业务想要的结果。我们目的是需要通过训练得到单调性。
5.1.3 探索性数据分析
由于训练集构建的方式不同,首先明确下,我个人在初赛的广告ID均是从广告操作表中提取的,即提取广告操作表中有初始出价的广告ID,并且在日志数据白表中出价唯一的广告ID,这里我们已初始B榜为准。下面将给出提取训练集代码。
首先对totalExposureLog数据进行基本的处理,为什么这样处理,将在数据预处理部分说明:
totalExposureLog = totalExposureLog.drop_duplicates(subset=['aid','uid','aid_location','request_time'], keep='last')
totalExposureLog = totalExposureLog.loc[(totalExposureLog.pctr<=1000)]
totalExposureLog = totalExposureLog.loc[(totalExposureLog.quality_ecpm>=0)]
totalExposureLog = totalExposureLog.loc[(totalExposureLog.totalEcpm<=120000)]
totalExposureLog = totalExposureLog.loc[(totalExposureLog.quality_ecpm<=80000)]
totalExposureLog = totalExposureLog.loc[(totalExposureLog.bid<=15000)]接下来构造训练集:
ad_static_feature = pd.read_table(path + 'testA/ad_static_feature.out',
names=['aid', 'create_time', 'account_id', 'goods_id', 'goods_type',
'industry_id', 'aid_size'])
ad_operation = pd.read_table(path + 'testA/ad_operation.dat', names=['aid', 'update_time', 'type', 'update_key', 'update_value'])
# 对广告操作表中有初始出价的广告id进行标记
tmp = ad_operation.loc[(ad_operation.update_time==0)&(ad_operation.update_key==2), ['aid','update_value']]
tmp.columns = ['aid','bid']
ad_static_feature = ad_static_feature.merge(tmp, on='aid', how='left')
data = data.merge(ad_static_feature, on='aid', how='left')
data['bid'] = data['bid'].fillna(-999)
# 对出价唯一的广告id进行标记
bid_nuni = totalExposureLog .groupby(['aid'])['bid'].agg({'nunique'}).reset_index()
bid_nuni.columns = ['aid','nuni']
bid_nuni = bid_nuni[bid_nuni['nuni']==1]
data = data.merge(bid_nuni, on='aid', how='left')
data['nuni'] = data['nuni'].fillna(-999)
# 同时满足两个条件
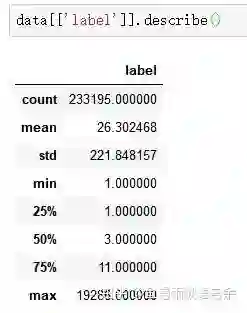
data = data.loc[(data.period!=-999)|(data.nuni!=-999)]那么最终会得到233195行训练集样本(代码是可以优化的)。训练集有了确定的数目后,我们就可以进行一些基本的数据分析。
训练集标签基本统计信息:
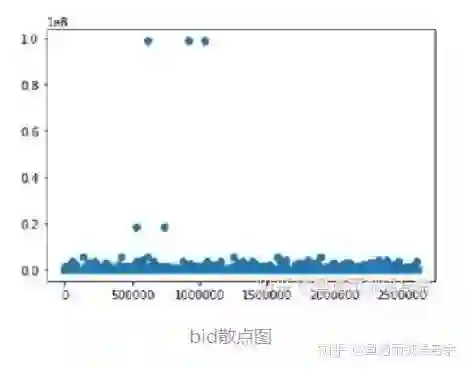
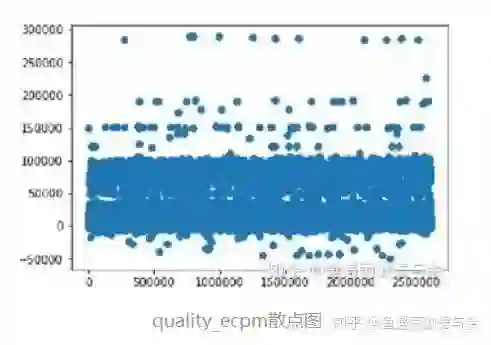
日志曝光数据基本可视化:
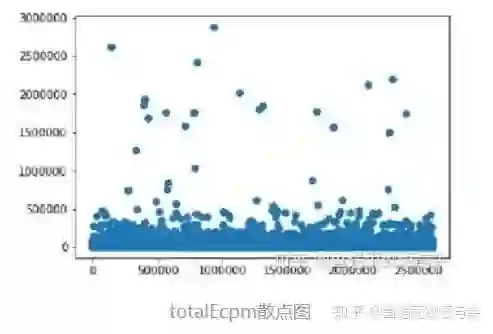
5.1.4 数据预处理
结合基本的数据分析,数据预处理部分主要剔除一些异常样本和噪音,这里对整体日志曝光数据进行了简单的清洗。
# 移除相同 样本
totalExposureLog = totalExposureLog.drop_duplicates(subset=['aid','uid','aid_location','request_time'], keep='last')
# 移除pctr高于密集区的样本
totalExposureLog = totalExposureLog.loc[(totalExposureLog.pctr<=1000)]
# 移除quality_ecpm高于密集区的样本
totalExposureLog = totalExposureLog.loc[(totalExposureLog.quality_ecpm>=0)&(totalExposureLog.quality_ecpm<=80000)]
# 移除totalEcpm高于密集区的样本
totalExposureLog = totalExposureLog.loc[(totalExposureLog.totalEcpm<=120000)]
# 移除bid高于密集区的样本
totalExposureLog = totalExposureLog.loc[(totalExposureLog.bid<=15000)]5.1.5 特征工程
基础特征
在初赛中,初始特征分为类别特征和数值特征,基本上我们都会使用的,只不过会重新构造一下。
# 类别特征
categorical_features = ['aid_size','goods_type','goods_id','industry_id','account_id','crowd', 'period','area', 'behavior']
# 数值特征
numerical_features = ['pctr','quality_ecpm','totalEcpm','ecmp']

对于基本类别特征,除了投放人群crowd和投放时段外period,其余的直接进行onehot。
下面将对投放人群和投放时段单独处理:
投放时段构造代码:
def get_fill_period(item):
if item != -999:
item = item.split(',')[3]
item = list(bin(int(item))[2:])
item.reverse()
item = "".join(item)
l = len(item)
item = '0'*(48-l) + item
else:
item = '2'*48
return item
# 投放时段分为七部分,正好一周,不过基本相同,所以默认选择的周四的投放时段
# 别问我为什么,修改这个bug后,反而掉分了
data['period'] = data['period'].apply(get_fill_period)
test['period'] = test['period'].apply(get_fill_period)
# 将48个时段全部展开,构造48个二值特征
binary_columns = []
for i in range(0,48):
data[str(i)+'_period'] = data['period'].apply(lambda x: int(x[i]))
test[str(i)+'_period'] = test['period'].apply(lambda x: int(x[i]))
binary_columns.append(str(i)+'_period')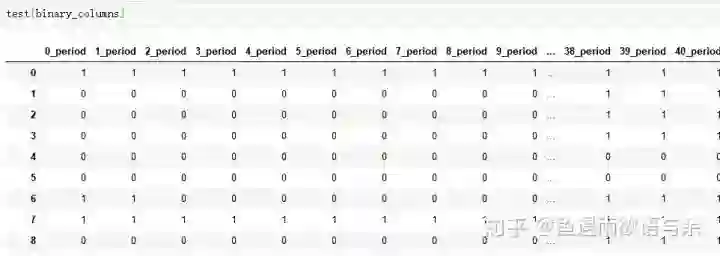
投放人群构造代码:
def get_open_crowd(df_):
df = df_.copy()
crowd_data = []
crowd_type = []
df['crowd_list'] = df['crowd'].apply(lambda x:str(x).split('|'))
for i in range(df.shape[0]):
line = df['crowd_list'][i:i+1][i]
crowd_dict = {'area':np.nan,'age':np.nan,'status':np.nan,'gender':np.nan,'behavior':np.nan,'connectionType':np.nan,\
'os':np.nan,'education':np.nan,'consuptionAbility':np.nan,'work':np.nan,'device':np.nan}
for each in line:
eachKey = each.split(':')[0]
if eachKey in crowd_dict:
crowd_dict[eachKey] = each.split(':')[1]
crowd_data.append(crowd_dict)
crowd_feature = pd.DataFrame(crowd_data)
return crowd_feature
def get_fill_crowd(df_):
df = df_.copy()
cols = df.columns
for f in cols:
li = df[f].unique().tolist()
all_values = ''
for i in li:
all_values = all_values + ',' + str(i)
all_values = all_values.split(',')
try:
all_values.remove('')
all_values.remove('nan')
except:
pass
all_values = list(set(all_values))
all_str = ''
for i in all_values:
all_str = all_str + ',' + i
df[f] = df[f].fillna(all_str[1:])
return df
tmp = pd.concat([data, test], axis=0, ignore_index=True)
# 分为两步
# 1.拆分定向人群
crowd_feature = get_open_crowd(tmp)
# 2.填充缺失属性
crowd_feature = get_fill_crowd(crowd_feature)两部分完成后,也就做完了基本的处理。
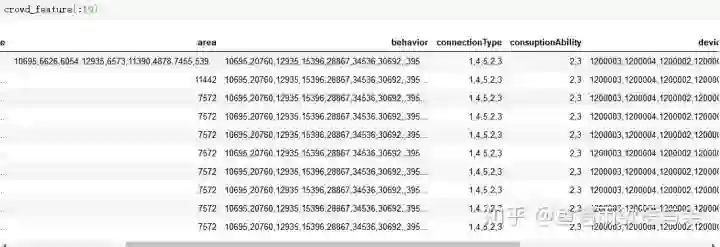
五折交叉统计
五折交叉统计特征在初赛和复赛都展现了一定的作用,这种构造特征的方式主要是为了防止过拟合,还是有必要学习下的。
特别地,我们进行了两部分的五折,日志数据五折和训练集五折,当然也可以只用训练数据。
每次日志数据的4折构造特征,然后给训练集中的一折。

五折交叉统计代码:
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
data['fold'] = None
for fold_,(trn_idx,val_idx) in enumerate(folds.split(data,data)):
data.loc[val_idx, 'fold'] = fold_
kfold_features = []
for feat in ['aid','goods_id','account_id','aid_size','industry_id','goods_type']:
nums_columns = ['pctr','quality_ecpm','totalEcpm','cpc','ecpm']
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
print(colname)
kfold_features.append(colname)
data[colname] = None
for fold_,(trn_idx,val_idx) in enumerate(folds.split(dataLog,dataLog)):
Log_trn = dataLog.iloc[trn_idx]
order_label = Log_trn.groupby([feat])[f].mean()
tmp = data.loc[data.fold==fold_,[feat]]
data.loc[data.fold==fold_, colname] = tmp[feat].map(order_label)
# fillna
median = Log_trn[f].median()
data.loc[data.fold==fold_, colname] = data.loc[data.fold==fold_, colname].fillna(median)
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
test[colname] = None
order_label = dataLog.groupby([feat])[f].mean()
test[colname] = test[feat].map(order_label)
# fillna
median = dataLog[f].median()
test[colname] = test[colname].fillna(median)历史平移
这部分特征也是关键中的关键,对于这种包含时间的时序问题,测试集的具体数据是不知道的,我们可以使用前n天来曝光量,或者是pctr作为测试集的特征。如下图,d-1天的信息作为d天的特征,这种相近日期的数据相关性是非常大的。我们知道,直接用前一天的曝光量才填充,这种规则就能得到很高的分数。
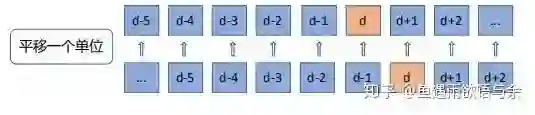
具体平移的特征初赛和复赛也是有很大的不同。对于初赛而言,我们选择了类别特征(aid,goods_id, account_id, aid_size, goods_type, industry_id)与数值特征(label, pctr, quality_ecpm, totalEcpm, ecpm)进行组合。从不同粒度来反映历史情况。代码如下:(具体代码将在Live课程介绍后给出)
def get_history_features(df_, mean_data, features, bf=0):
df = df_.copy()
dt = pd.DataFrame()
bf = str(bf)
cols = []
for f in features:
cols.append(f+'_'+bf)
for d in range(18,48):
# 历史平移
p = mean_data.loc[mean_data['rank']==(d-int(bf)) , ['aid'] + features]
p.columns = ['aid'] + cols
p = p.drop_duplicates(subset=['aid'], keep='last')
tmp = df.loc[df['rank']==(d+1),['index','aid']]
tmp = tmp.merge(p, on='aid', how='left')
# fillna
for f in cols:
median = p[f].median()
tmp[f] = tmp[f].fillna(median)
if dt.shape[0] == 0:
dt = tmp
else:
dt = pd.concat([dt, tmp], axis=0, ignore_index=True)
dt = dt[['index'] + cols]
return dt, cols
# 前一天
## aid
bf,cols = get_history_features(all_data, aid_data, aid_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features = history_features + cols
## goods_id
bf,cols = get_history_features(all_data, goods_id_data, goods_id_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features1 = history_features1 + cols
## account_id
bf,cols = get_history_features(all_data, account_id_data, account_id_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features1 = history_features1 + cols
## aid_size
bf,cols = get_history_features(all_data, aid_size_data, aid_size_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features1 = history_features1 + cols
## goods_type
bf,cols = get_history_features(all_data, goods_type_data, goods_type_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features1 = history_features1 + cols
## industry_id
bf,cols = get_history_features(all_data, industry_id_data, industry_id_columns, bf=0)
all_data = all_data.merge(bf, on='index', how='left')
history_features1 = history_features1 + colsword2vec
在初赛的时候一直都在说用户ID如何上分的,由于还在比赛中,并未做详细的介绍。在这一部分,我也将详细介绍用户ID的使用方法,这部分的内容在初赛B榜的时候,也是给我带来了0.5个百的提升。
具体做法,以用户ID所访问过的广告ID为一个句子,然后很多句子合并起来就是一个document,最后得到关于广告ID的embedding
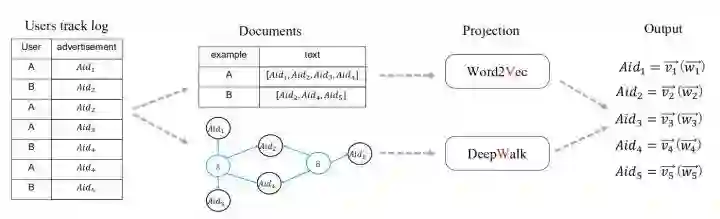
具体代码:
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
#word2vec
def w2v(log,pivot,f,flag,L):
print("w2v:",pivot,f)
log[f]=log[f].fillna(-1).astype(int)
sentence=[]
dic={}
day=0
log=log.sort_values(by='request_day')
log['day']=log['request_day']
for item in log[['day',pivot,f]].values:
if day!=item[0]:
for key in dic:
sentence.append(dic[key])
dic={}
day=item[0]
#print(day)
try:
dic[item[1]].append(str(int(item[2])))
except:
dic[item[1]]=[str(int(item[2]))]
for key in dic:
sentence.append(dic[key])
print(len(sentence))
print('training...')
random.shuffle(sentence)
model = Word2Vec(sentence, size=L, window=10, min_count=1, workers=10,iter=10)
print('outputing...')
values=set(log[f].values)
w2v=[]
for v in values:
try:
a=[int(v)]
a.extend(model[str(v)])
w2v.append(a)
except:
pass
out_df=pd.DataFrame(w2v)
names=[f]
for i in range(L):
names.append(pivot+'_embedding_'+f+'_'+str(L)+'_'+str(i))
out_df.columns = names
out_df.to_pickle('input/' +pivot+'_'+ f +'_'+flag +'_w2v_'+str(L)+'.pkl')
return out_df
dataLog = dataLog.loc[(dataLog.request_month==3)]
gc.collect()
# uid主键
w2v(dataLog, 'uid', 'aid', '3month', 64)
w2v(dataLog, 'uid', 'goods_id', '3month', 64)
w2v(dataLog, 'uid', 'account_id', '3month', 64)
%%time
def get_merge_w2v(temp_, file, flag):
temp = temp_.copy()
for pivot, f, L in [('uid','aid',64), ('uid','goods_id',64), ('uid','account_id',64)]:
df = pd.read_pickle('input/' +pivot+'_'+ f +'_'+flag +'_w2v_'+str(L)+'.pkl')
print(pivot, f, L)
if file == 'train':
items = []
for item in temp[f].values:
if random.random()<0.05:
items.append(-1111111111)
else:
items.append(item)
temp['tmp'] = items
df['tmp'] = df[f]
del df[f]
temp = pd.merge(temp, df, on='tmp', how='left')
elif file == 'test':
temp = pd.merge(temp, df, on=f , how='left')
try:
del temp['tmp']
except:
pass
gc.collect()
return temp
train = all_data[all_data.flag!=-1]
test = all_data[all_data.flag==-1]
init_features = test.columns
train = get_merge_w2v(train, 'train', '3month')
test = get_merge_w2v(test , 'test' , '3month')
w2v_features = [f for f in test.columns if f not in init_features]
all_data = pd.concat([train, test], axis=0, ignore_index=True)CountVectorizer
奇怪的是,我用CountVectorizer对广告ID所对应的广告位进行词频统计,在初赛线下能得到非常不错的提升,线上也有千分位的提升。可是在复赛线上并未提升。
aid_location = dataLog.loc[(dataLog.request_month==3)&(dataLog.request_day==19)]
aid_location['aid_location'] = aid_location['aid_location'].astype(str)
aid_location['aid_location'] = aid_location.groupby(['aid'])['aid_location'].transform(lambda x: " ".join(x))
aid_location = aid_location.drop_duplicates(subset=['aid'], keep='last')
# 多值特征
mutil_features = ['age', 'connectionType', 'consuptionAbility', 'device', 'education', 'gender', 'os', 'status', 'work', 'aid_location']
print('CountVectorizer...')
cv = CountVectorizer(token_pattern='[\u4e00-\u9fa5_a-zA-Z0-9]{1,}')
for feat in mutil_features:
print(feat)
cv.fit(df[feat])
train_x = sparse.hstack((train_x, cv.transform(train[feat])), 'csr')
test_x = sparse.hstack((test_x, cv.transform(test[feat])), 'csr')5.1.6 算法建模
NN部分
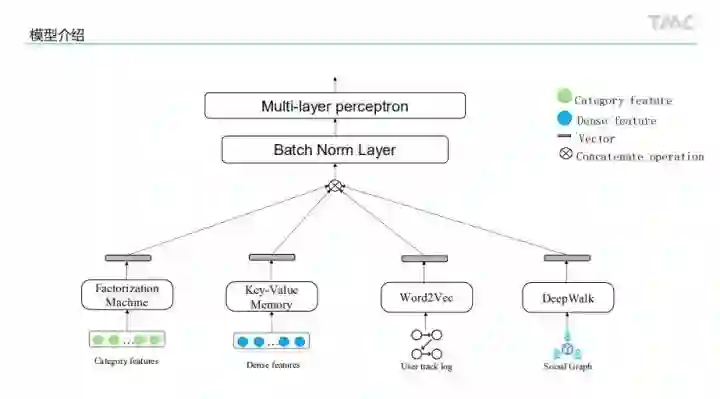
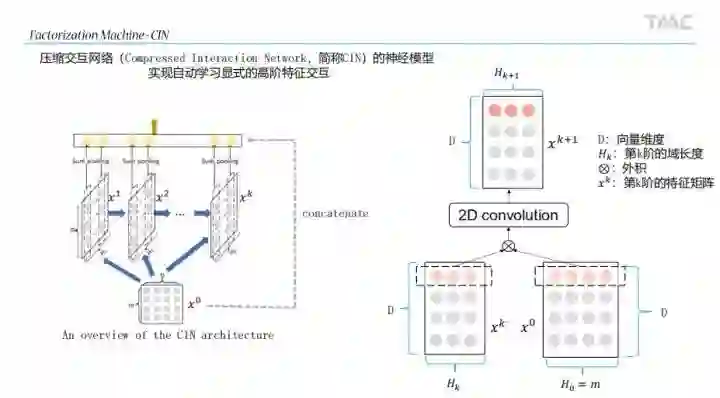
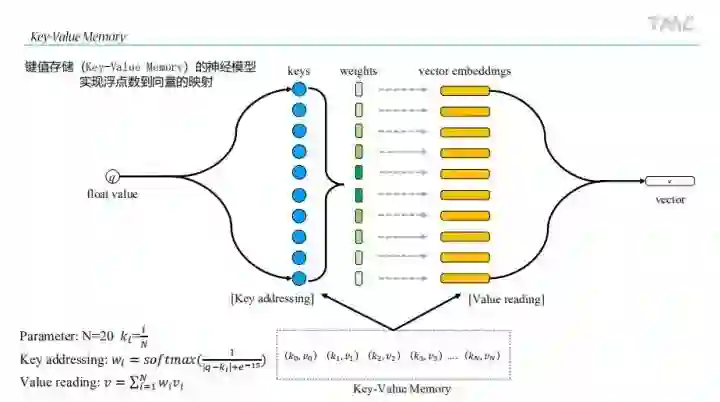
LightGBM部分
这里做法比较普通,直接五折交叉训练。下面给出具体代码:
lgb_params = {'num_leaves': 2**6-1,
'min_data_in_leaf': 25,
'objective':'regression_l1',
'max_depth': -1,
'learning_rate': 0.1,
'min_child_samples': 20,
'boosting': 'gbdt',
'feature_fraction': 0.8,
'bagging_fraction': 0.9,
'bagging_seed': 11,
'metric': 'mae',
'lambda_l1': 0.2}
def train_model(X, X_test, y, train_logbid, test_logbid, params, folds, model_type='lgb', label_type='bid'):
if label_type == 'bid':
y = np.log(y + 1) / train_logbid
elif label_type == 'nobid':
y = np.log(y + 1)
oof = np.zeros(X.shape[0])
predictions = np.zeros(X_test.shape[0])
scores = []
models = []
for fold_n, (trn_idx, val_idx) in enumerate(folds.split(X, y)):
print('Fold', fold_n, 'started at', time.ctime())
if model_type == 'lgb':
trn_data = lgb.Dataset(X[trn_idx], y[trn_idx])
val_data = lgb.Dataset(X[val_idx], y[val_idx])
clf = lgb.train(params,
trn_data,
num_boost_round=3000,
valid_sets=[trn_data,val_data],
valid_names=['train','valid'],
early_stopping_rounds=100,
verbose_eval=500,
)
oof[val_idx] = clf.predict(X[val_idx], num_iteration=clf.best_iteration)
tmp = clf.predict(X_test, num_iteration=clf.best_iteration)
if label_type == 'bid':
predictions += ((np.e**(tmp*test_logbid) - 1)) / folds.n_splits
elif label_type == 'nobid':
predictions += ((np.e**tmp - 1)) / folds.n_splits
if label_type == 'bid':
p = np.e**(oof[val_idx]*train_logbid[val_idx]) - 1
t = np.e**( y[val_idx]*train_logbid[val_idx]) - 1
elif label_type == 'nobid':
p = np.e**oof[val_idx] - 1
t = np.e**y[val_idx] - 1
s = abs(p- t) / ((p + t) * 2)
scores.append(s.mean())
models.append(clf)
if label_type == 'bid':
oof = np.e**(oof*train_logbid) - 1
elif label_type == 'nobid':
oof = np.e**oof - 1
print(np.mean(scores), np.std(scores), scores)
return oof, predictions, scores, models
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
oof, predictions, scores, models = train_model(train_x ,test_x, train_y, train_logbid, test_logbid, \
lgb_params, folds=folds, model_type='lgb', label_type='bid')
这里对训练目标进行了优化,保证训练出来的结果符合单调性。
5.1.7 模型融合
融合分为三个部分,分别是NN、lgb和规则。这里也有一个关键点,新旧广告得融合方式,不仅是模型和规则的融合,模型和模型之间的融合也应该考虑新旧广告。
写在最后
一年半的竞赛经历,很幸运拿到这次冠军。在这一年半,不仅坚持比赛,同时也坚持不断的分享。在我看来,分享是一个自我总结的一个过程。当然,这也是我与更多选手交流的一个平台,是一个相互学习提升的机会。愿我的分享能够帮助到你。
6. 初赛代码分享
https://github.com/guoday/Tencent2019_Preliminary_Rank1st
方案结合代码,这才是最“硬核”的,这部分为我们团队分享的初赛神经网路代码,在初赛nn的效果远好于LightGBM的效果。LightGBM部分代码在第五部分已经做了详细介绍。将第5、6两部分结合学习,帮助大家进一步深入探究初赛的问题解决方法。
7. 经验方法分享
如何进行一场数据挖掘算法竞赛 https://www.zhihu.com/lives/1126094213301006336
本次live,我对自身的经历与经验经行了总结,这些内容也都是我在腾讯赛中所用到了。关键是帮助大家进行解决问题的方法扩展和常用套路的学习,其中还介绍了复赛中的尝试。(福利:复赛冠军代码)
8. 复赛完整方案
链接将随后补充,敬请期待!
评委讲到“这是最接近腾讯真实业务的方案”
本文将介绍复赛冠军的完整方案。这里将给出完整的PPT内容,并对关键点进行详细的介绍,从特征工程到模型,再到最终的融合,一切都是那么的无懈可击。一起来看看被评委高度认可的方案是怎么做的。
写在最后
一年半的竞赛经历,很幸运拿到这次冠军。在这一年半,不仅坚持比赛,同时也坚持不断的分享。在我看来,分享是一个自我总结的一个过程。当然,这也是我与更多选手交流的一个平台,是一个相互学习提升的机会。愿我的分享能够帮助到你。
CVer-竞赛交流群
扫码添加CVer助手,可申请加入CVer-竞赛交流群。一定要备注:研究方向+地点+学校/公司+昵称(如竞赛交流+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!




