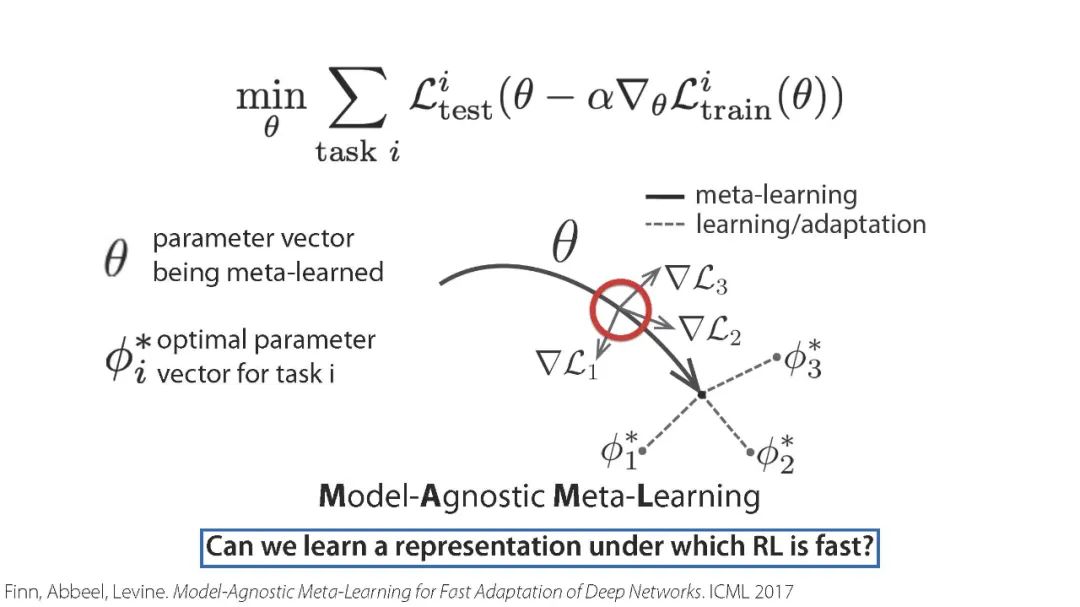
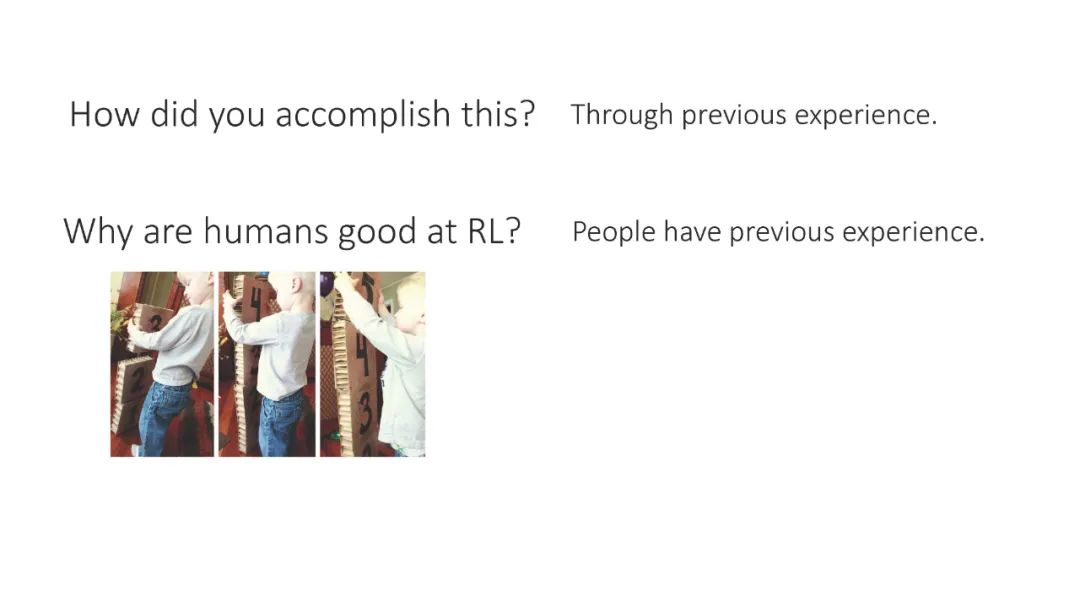
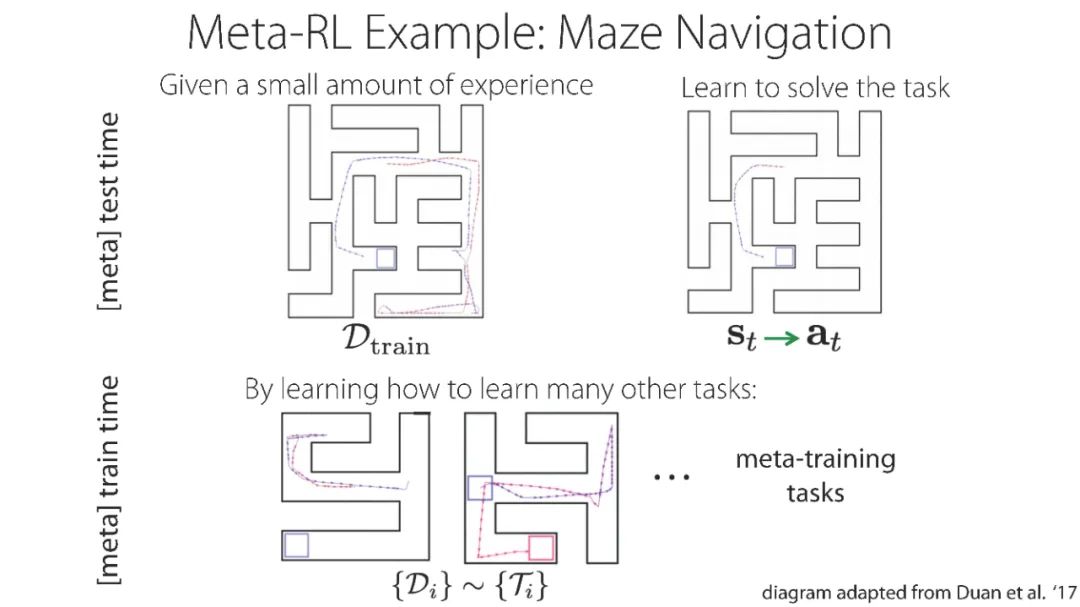
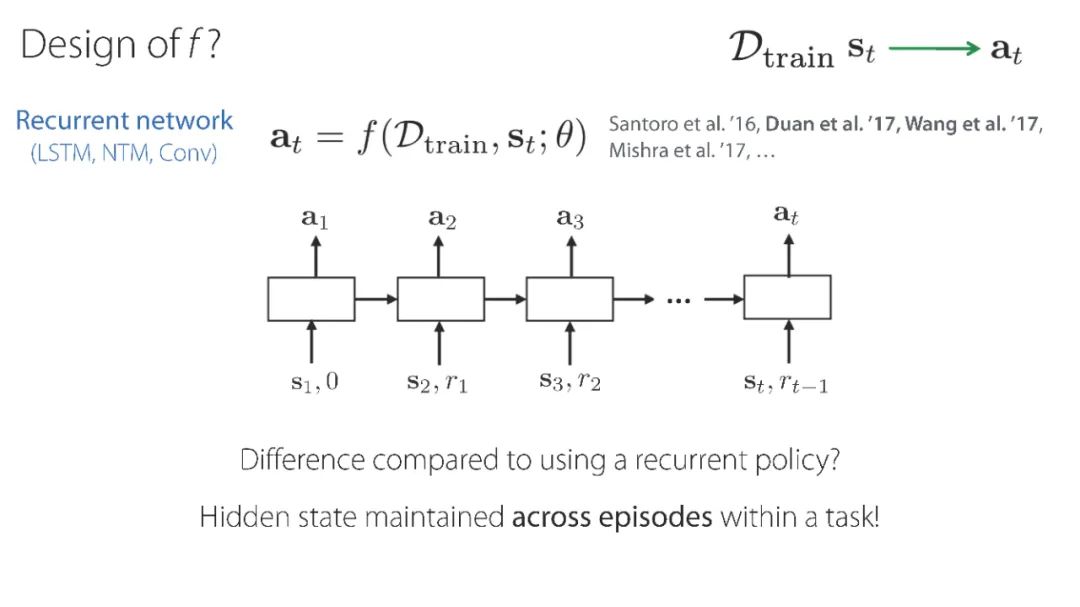
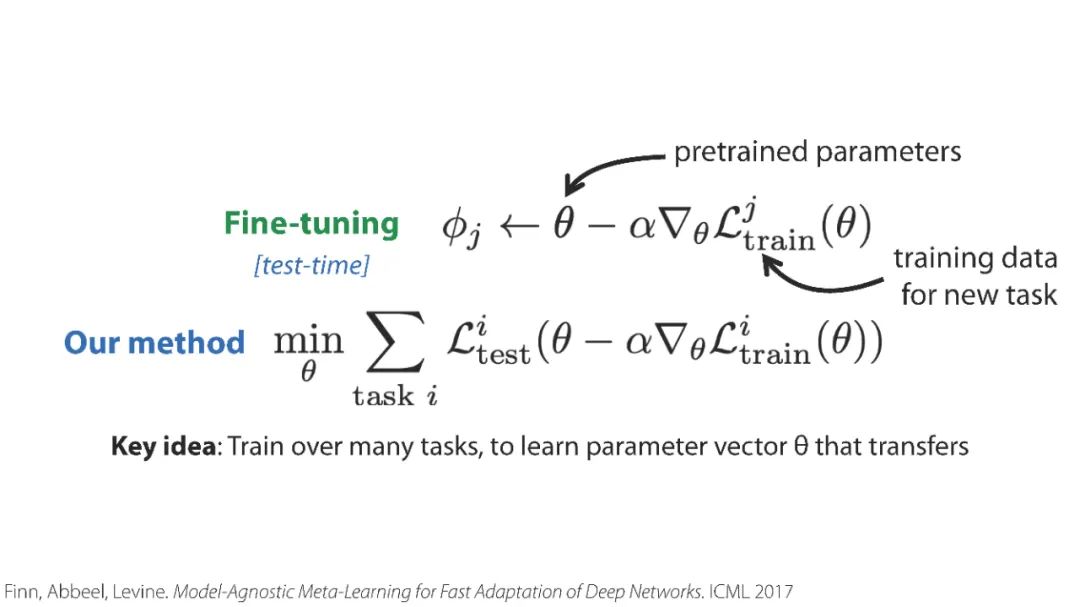
「元强化学习」报告,斯坦福Chelsea Finn讲解,52页ppt,Meta Reinforcement Learning

元强化学习算法可以利用以前的经验来学习如何学习,从而使机器人更快地获得新技能。然而,目前关于元强化学习的研究大多集中在非常狭窄的任务分布上。例如,一个常用的元强化学习基准将模拟机器人的不同跑步速度作为不同的任务。当策略在如此狭窄的任务分布上进行元训练时,它们不可能推广到更快地获得全新的任务。因此,如果这些方法的目标是能够更快地获得全新的行为,我们就必须在任务分布上评估它们,任务分布必须足够广泛,以使新行为普遍化。
https://www.youtube.com/watch?v=c0vSwglRY4w&feature=youtu.be









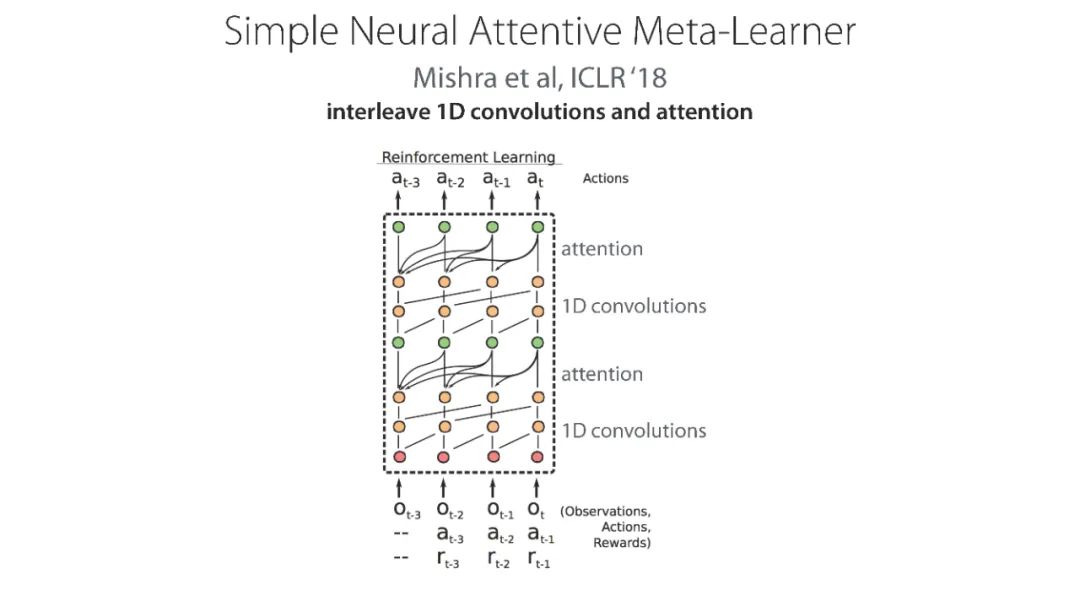

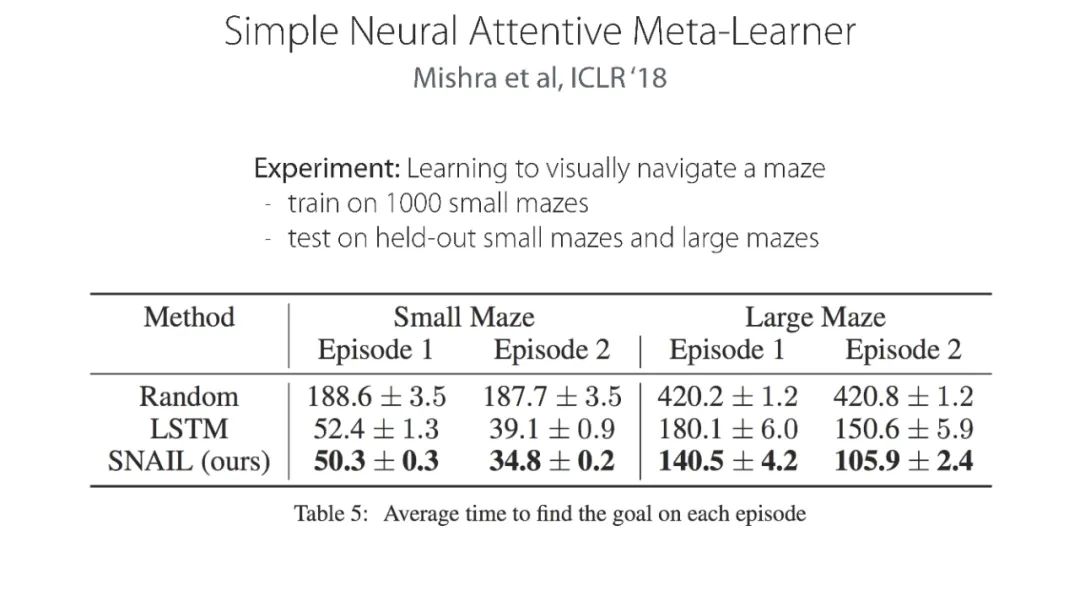
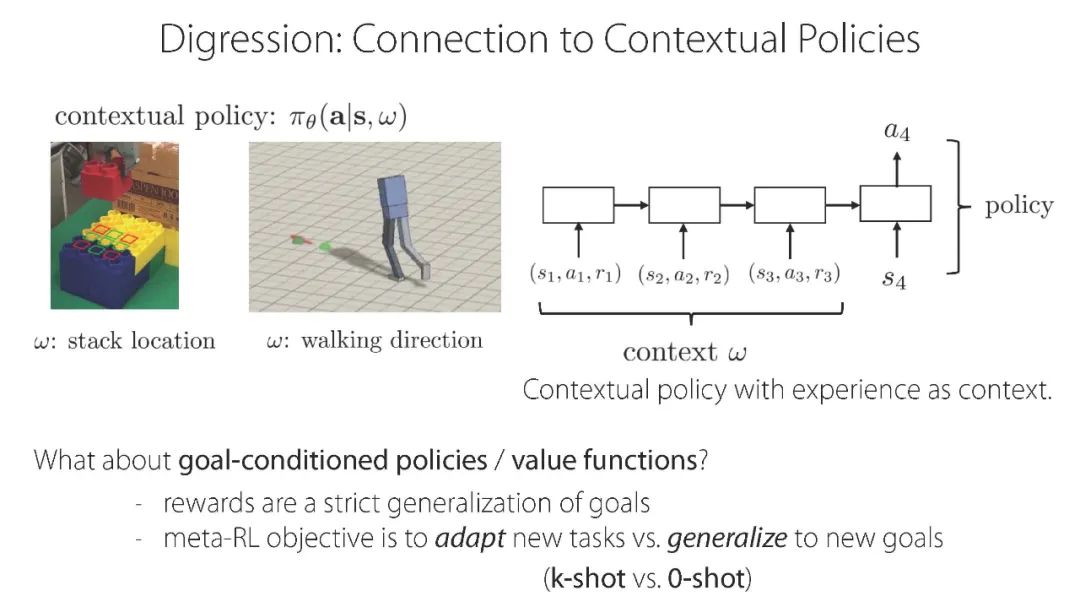
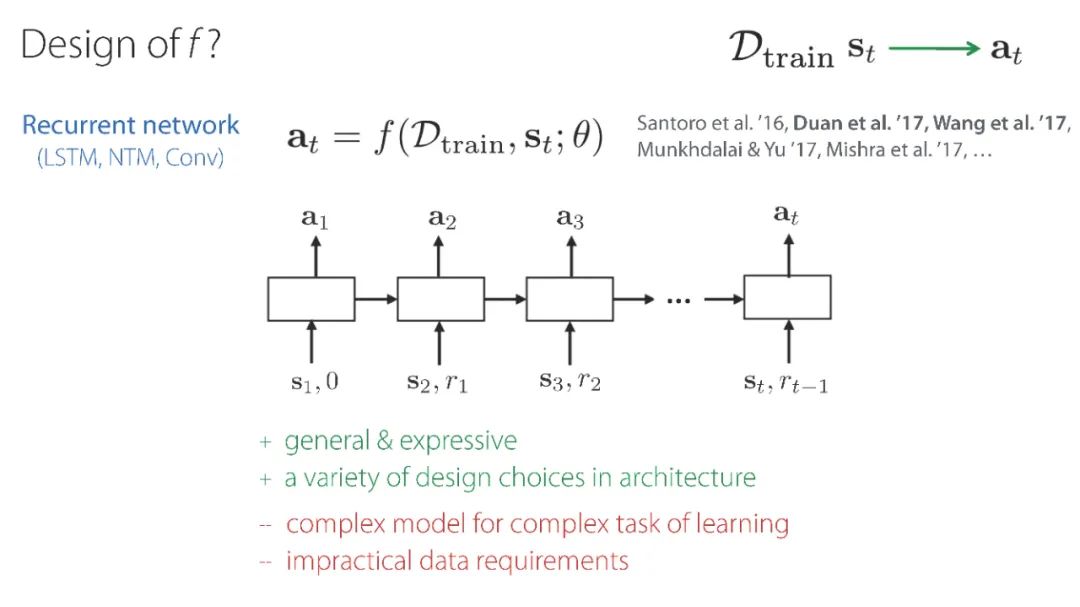
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MRL” 可以获取《「元强化学习」报告,斯坦福Chelsea Finn讲解,52页ppt,Meta Reinforcement Learning》专知下载链接索引



登录查看更多
相关内容
Arxiv
17+阅读 · 2019年9月9日




相关VIP内容
相关资讯
相关论文
Arxiv
17+阅读 · 2019年9月9日