实操教程|这可能是关于Pytorch底层算子扩展最详细的总结了!(附代码详解)

极市导读
一般情况下,pytorch推荐使用python层的前端语言来构建新的算子。但是有时候出于一些其他方面的考虑,会需要增加底层算子。因此pytorch也提供了直接扩展底层C++算子的能力。本文主要讲解了三种方式:native_functions.yaml、C++ extension方式、 OP register 方式,附有详细代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1 、前言
一般情况下,pytorch推荐使用python层的前端语言来构建新的算子。因为pytorch在python层的api已经足够丰富,可以构造出很多自定义的算子。但是有时候出于一些其他方面的考虑,会需要增加底层算子。例如有时候对性能要求很高,python不满足需求,又或者是需要链接其他的动态库(blas,mkl等),因此pytorch也提供了直接扩展底层C++算子的能力。主要有三种方式,native_functions.yaml、C++ extension方式、 OP register 方式。
2、 native_functions.yaml方式
pytorch的原生算子很多都是使用这种方式组织的。在native_functions.yaml中有关于各个算子的说明,然后在同级目录下面有这些算子的实现。使用该方式添加新的算子,主要用在已经支持的硬件上面。例如pytorch本身已经支持了CPU和GPU,此时需要一些新的算子,该算子只需要在CPU或者GPU上面运行,那么这种方式就非常适合。只需要定义新算子的kernel实现,然后添加配置信息,就可以自动生成:torch.xxx()、torch.nn.functional.xxx()以及tensor.xxx()方法,而不用去关注算子与pytorch是如何衔接,以及如何把算子添加到tensor的属性中等其他细节。native_functions.yaml文件位于pytorch源码的pytorch/aten/src/Aten/native/native_functions.yaml,内容如下(截取absolute算子的配置信息),对于每个算子的描述,包括几个主要字段:func、variants、dispatch等。
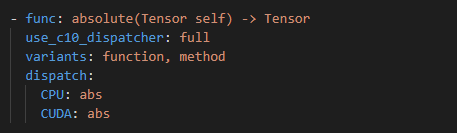
func 字段:表示算子的名称以及输入输出参数类型
variants 字段:表示需要自动生成的高级方法。function表示自动生成torch.absolute()方法,method表示生成 tensor的absolute ()方法,即可以定义一个tensor a,然后可以执行a.absolute()方法。
dispatch 字段:表示分发的设备类型对应的op方法。CPU指的是该算子支持CPU设备,对应的实现函数为abs函数,CUDA指的是当前算子支持GPU设备,对应的实现函数为cuda的abs函数。
下面以pytorch自带的leakly_relu算子来具体分析添加算子的流程。首先是需要在native_functions.yaml中添加算子的说明,包括反向传播函数。如下代码片段中的leaky_relu和leaky_relu_backward函数说明。这里的python_module:nn,表示将该方法自动生成到torch.nn.functional模块中,这样就可以通过torch.nn.functional.leaky_relu来调用这个算子。
- func: leaky_relu(Tensor self, Scalar negative_slope=0.01) -> Tensor
use_c10_dispatcher: full
python_module: nn
dispatch:
CPU: leaky_relu
CUDA: leaky_relu
QuantizedCPU: quantized_leaky_relu
- func: leaky_relu_backward(Tensor grad_output, Tensor self, Scalar negative_slope, bool self_is_result) -> Tensor
use_c10_dispatcher: full
python_module: nn
其次,需要在配置文件tools/autograd/derivatives.yaml中添加算子和反向算子的对应关系,如下代码段表示,即说明了leaky_relu的反向传播函数为leaky_relu_backward。
- name: leaky_relu(Tensor self, Scalar negative_slope=0.01) -> Tensor
self: leaky_relu_backward(grad, self, negative_slope, false)
完成了算子的说明之后,需要在aten/src/Aten/native/目录下面通过C++实现相关的算子流程。Pytorch原生的算子一般按照功能实现在一起。例如激活函数都放在Activation.h与Activation.cpp中。所以leaky_relu的实现就在aten/src/Aten/native/目录下的Activation.h与Activation.cpp文件中。如下代码段所示。不过这里定义的实现只是一个封装,没有真正的实现。leak_relu调用了leaky_relu_stub方法,leak_relu_backward调用了leak_relu_backward_stub方法。
//Activation.h头文件
using leaky_relu_fn = void (*)(TensorIterator&, Scalar);
using leaky_relu_backward_fn = void (*)(TensorIterator&, Scalar);
DECLARE_DISPATCH(leaky_relu_fn, leaky_relu_stub);
DECLARE_DISPATCH(leaky_relu_backward_fn, leaky_relu_backward_stub);
//Activation.cpp文件内容
DEFINE_DISPATCH(leaky_relu_stub);
DEFINE_DISPATCH(leaky_relu_backward_stub);
Tensor leaky_relu(
const Tensor& self,
Scalar negval) {
Tensor result;
auto iter = TensorIterator::unary_op(result, self);
leaky_relu_stub(iter.device_type(), iter, negval);
return iter.output();
}
Tensor leaky_relu_backward(
const Tensor& grad_output,
const Tensor& self_or_result,
Scalar negval,
bool is_result) {
Tensor result;
auto iter = TensorIterator::binary_op(result, self_or_result, grad_output);
leaky_relu_backward_stub(iter.device_type(), iter, negval);
return iter.output();
}
最终,CPU端的leaky_relu_stub和leak_relu_backward_stub两个函数的实现流程都在aten/src/Aten/native/cpu/Activation.cpp中。并且增加了两个DISPATH(函数分发的说明)。如下代码段所示:
REGISTER_DISPATCH(leaky_relu_stub, &leaky_relu_kernel);
REGISTER_DISPATCH(leaky_relu_backward_stub, &leaky_relu_backward_kernel);
static void leaky_relu_kernel(TensorIterator& iter, Scalar negval_) {
AT_DISPATCH_FLOATING_TYPES(iter.dtype(), "leaky_relu_cpu", [&] {
using Vec = Vec256<scalar_t>;
auto zero_vec = Vec((scalar_t)(0));
auto one_vec = Vec((scalar_t)(1));
scalar_t negval = negval_.to<scalar_t>();
Vec negval_v = Vec(negval);
cpu_kernel_vec(
iter,
[&](scalar_t a) -> scalar_t {
return a > scalar_t(0) ? a : a * negval;
},
[&](Vec a) -> Vec {
auto r = Vec::blendv(negval_v, one_vec, a > zero_vec);
return a * r;
});
});
}
static void leaky_relu_backward_kernel(TensorIterator& iter, Scalar negval_) {
AT_DISPATCH_FLOATING_TYPES(iter.dtype(), "leaky_relu_backward_cpu", [&] {
using Vec = Vec256<scalar_t>;
auto zero_vec = Vec((scalar_t)(0));
auto one_vec = Vec((scalar_t)(1));
scalar_t negval = negval_.to<scalar_t>();
Vec negval_v = Vec(negval);
cpu_kernel_vec(
iter,
[&](scalar_t a, scalar_t b) -> scalar_t {
return a > scalar_t(0) ? b : b * negval;
},
[&](Vec a, Vec b) -> Vec {
auto r = Vec::blendv(negval_v, one_vec, a > zero_vec);
return b * r;
});
});
}
同样的,GPU端的leaky_relu_stub和leak_relu_backward_stub两个函数的实现流程都在aten/src/Aten/native/cuda/Activation.cu中。并且增加了两个DISPATH(函数分发的说明)。如下代码段所示:
REGISTER_DISPATCH(leaky_relu_stub, &leaky_relu_kernel);
REGISTER_DISPATCH(leaky_relu_backward_stub, &leaky_relu_backward_kernel);
void leaky_relu_kernel(TensorIterator& iter, Scalar negval_) {
AT_DISPATCH_FLOATING_TYPES_AND2(at::ScalarType::Half, at::ScalarType::BFloat16, iter.dtype(), "leaky_relu_cuda", [&]() {
AT_SKIP_BFLOAT16_IF_NOT_ROCM(scalar_t, "leaky_relu_cuda", [&] {
auto negval = negval_.to<scalar_t>();
gpu_kernel(iter, [negval]GPU_LAMBDA(scalar_t a) -> scalar_t {
return a > scalar_t(0) ? a : a * negval;
});
});
});
}
void leaky_relu_backward_kernel(TensorIterator& iter, Scalar negval_) {
AT_DISPATCH_FLOATING_TYPES_AND2(at::ScalarType::Half, at::ScalarType::BFloat16, iter.dtype(), "leaky_relu_backward_cuda", [&]() {
AT_SKIP_BFLOAT16_IF_NOT_ROCM(scalar_t, "leaky_relu_backward_cuda", [&] {
auto negval = negval_.to<scalar_t>();
gpu_kernel(iter, [negval]GPU_LAMBDA(scalar_t a, scalar_t b) -> scalar_t {
return a > scalar_t(0) ? b : b * negval;
});
});
});
}
至此,就完成了整个leaky_relu算子的实现流程,总体流程还是比较简单清晰的,并且只需要考虑算子本身的具体实现,而不需要去考虑如何将算子添加到torch模块,添加到torch.nn.functional模块,如何与tensor耦合等业务逻辑。下面这个图更加清晰的展示了这种实现方式(为了节约图片高度,省略cuda的实现)。

下面以实现一个自定义的xxx算子为例,为了简单起见,只实现该算子的CPU前向算子。首先在native_functions.yaml文件中增加xxx算子的描述:
- func: xxx(Tensor self) -> Tensor
use_c10_dispatcher: full
python_module: nn
dispatch:
CPU: xxx
然后在同级目录下实现算子的表层实现文件,同样为了简单起见,直接实现在pytorch已有的Activation.h与Activation.cpp源文件中。如下所示:
//Activation.h文件
using xxx_fn = void (*)(TensorIterator&);
DECLARE_DISPATCH(xxx_fn, xxx_stub);
//Activation.cpp文件
DEFINE_DISPATCH(xxx_stub);
Tensor xxx(
const Tensor& self) {
Tensor result;
auto iter = TensorIterator::unary_op(result, self);
xxx_stub(iter.device_type(), iter);
return iter.output();
}
最后在cpu/Activation.cpp中实现真正的xxx_stub方法。为了简单,不做任何数值操作,只是调用printf打印相关信息。
REGISTER_DISPATCH(xxx_stub, &xxx_kernel);
static void xxx_kernel(TensorIterator& iter) {
AT_DISPATCH_FLOATING_TYPES(iter.dtype(), "xxx_cpu", [&] {
printf("xxx op forward!");
});
}
编译之后,对xxx算子进行测试,如下所示:
>>> import torch
>>> t = torch.ones(1,3,2,2)
>>> t = torch.xxx(t)
xxx op forward!
>>> t = t.xxx()
xxx op forward!
成功打印,说明xxx算子已经可以使用
3、C++ extention方式
虽然native_functions.yaml方式可以比较方便的增加或者修改算子,但是存在一个比较严重的问题。就是与pytorch的耦合度过高,由于在pytorch的源码中直接修改,那么每次增加或者修改算子都需要重新编译pytorch。为此,pytorch提供了另外一种更加简便的方式来扩展底层算子,就是 C++ extension方式。它与pytorch的相互解耦,分开编译,所以增加算子不需要修改pytorh的源码。它的原理其实就是通过pybind11,将C++编译为pytroch的一个模块,这样就可以在pytorch中通过这个新的模块来执行新的OP了。这里以一个小例子来说明如何通过C++extension增加一个算子。该例子出自官方文档:https://pytorch.org/tutorials/advanced/cpp_extension.html#writing-a-mixed-c-cuda-extension
算子名称为lltm,首先看一下目录结构:

在lltm.cpp中编写前向和反向函数的功能实现:
#include <vector>
std::vector<at::Tensor> lltm_forward(…) {
……
return {…};
}
std::vector<torch::Tensor> lltm_backward(…) {
……
return {…};
}
另外需要增加pybind11的绑定说明。因为pytorch的c++extension是通过pybind11绑定到python的。绑定说明如下:
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &lltm_forward, "LLTM forward");
m.def("backward", &lltm_backward, "LLTM backward");
}
最后编写setup.py,用于编译生成相关的模块
from setuptools import setup, Extension
from torch.utils import cpp_extension
setup(name='lltm_cpp',
ext_modules=[cpp_extension.CppExtension('lltm_cpp', ['lltm.cpp'])],
cmdclass={'build_ext': cpp_extension.BuildExtension})
完成上述代码的编写之后,执行:python setup.py install即可完成编译。生成pytorch中可用的lltm算子。下面对新增加的lltm算子进行测试,发现pytorch已经可以准确识别该算子了。
In [1]: import torch
In [2]: import lltm_cpp
In [3]: lltm_cpp.forward
Out[3]: <function lltm.PyCapsule.forward>
4、OP Register方式
虽然C++ extension方式能够比较方便的增加底层算子。但是也存在一点缺陷。首先它是作为一个额外的扩展模块接入pytorch,所以在调用这些方法的时候,都是需要直接导入方法名称。即无法通过torch.xxx或者tensor.xxx的方式进行调用,另外只能支持现有平台,无法扩展到新的硬件平台。所以Pytorch还提供了一种更加强大的算子扩展能力,就是OP Register(算子注册)方式。同样,该方式与pytorch源码解耦,增加和修改算子不需要重新编译pytorch源码。关于该部分的说明,pytroch的官方文档中并没有找到相关信息,但是在pytroch源码的aten/src/ATen/core/op_registration/README.md中有一些介绍。(备注:虽然该方法与pytorch本身解耦,如果需要增加新硬件平台对应的算子,那么需要首先在pytroch源码中增加对新硬件的支持,以及算子分发的DISPATH_KEY等相关信息,然后才能使用该方法注册基于该新硬件的算子)
用该方式注册一个新的算子,流程非常简单:先编写C++相关的算子实现,然后通过pytorch底层的注册接口(torch::RegisterOperators),将该算子注册即可。如下代码段所示。这里只注册了pytroch原生支持的CPU和CUDA硬件平台。
//my_kernel 定义(包括CPU和GPU版本)
my_namespace {
Tensor my_op_cpu(const Tensor& a, const Tensor& b) {...}
Tensor my_op_cuda(const Tensor& a, const Tensor& b) {...}
}
static auto registry = torch::RegisterOperators()
.op("my_namespace::my_op", torch::RegisterOperators::options()
.kernel<decltype(my_kernel_cpu), &my_kernel_cpu>(CPU()))
.op("my_namespace::my_op", torch::RegisterOperators::options()
.kernel<decltype(my_kernel_cuda), &my_kernel_cuda>(CUDA()));
如果需要增加新硬件平台的支持,那么首先需要在pytorch源码中的Backend、Device等模块中添加新硬件的支持。假设新硬件平台名为:VD(Virtual Device),那么注册基于VD的新算子就是:
static auto registry = torch::RegisterOperators()
.op("my_namespace::my_op", torch::RegisterOperators::options()
.kernel<decltype(my_kernel_cpu), &my_kernel_vd>(VD()))
公众号后台回复“94”获取最新CVPR22直播链接~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




