演讲:杨强
可信联邦学习会是下一个技术趋势吗?杨强教授为我们展现未来全面的发展愿景。
![]()
3 月 23 日,机器之心 AI 科技年会在线上召开。在下午的人工智能论坛上, FATE 联邦学习开源社区技术指导委员会主席杨强教授做了主题为《可信联邦学习》的演讲。他带我们系统地回顾联邦学习的进展和挑战,并展望了该领域未来发展的一个重要阶段 —— 可信联邦学习。
https://www.bilibili.com/video/BV1GY4y1q7ek?spm_id_from=333.999.0.0
首先回顾一下整个 AI 发展的阶段。我们看到 AI 现在有很大的发展,但是在理想和现实之间有很大的鸿沟。AI 现在主要的成就在于中心化的数据,样本足够多,质量足够好,特征也足够多。这样的情况下可以做出非常好的模型,像现在的预训练模型。
但是,我们的真实世界数据是多元的,散落在各地,质量不同,属主不同,又带来不同的利益。数量的格式、质量、特征不同,随时间的变化大。理想化的 AI 没有考虑到的一个重要因素是,用户的隐私怎么解决,如何合规,监管和审计如何解决,等等。
所以我们看到现在很大的成就,像大模型,我们预计在未来它们的发展趋势应该是来自很多分布式的小模型。这些模型有很多都是自下而上自发的,并且它们的合作和共享都是通过联邦的形式进行的,即联邦学习(Federated Learning)。
接着来看隐私计算和联邦学习,这些概念对大家来说已经不陌生了。经过三四年的市场教育,大家已经清楚什么是隐私计算,什么是安全多方计算(MPC),什么是联邦学习。但是,在不同的场合也有很多疑问。那么,到底隐私计算是联邦学习的一部分还是联邦学习是隐私计算的一部分?安全多方计算是联邦学习的子集吗?它们之间的关系又是怎样的呢?
首先概念不要混淆。我们有两个层次的概念,第一个是作为目标来说,隐私计算、联邦学习和安全多方计算三者的目标是共同的。尤其对于人工智能、多方数据建模的要求来说,联邦学习是一个我们要去解决建立和使用模型的目标。但是,这些技术从不同领域又提供了很多工具包,就像我们造了很多不同的砖一样,包括安全多方计算、加密算法,硬件,分布式机器学习等。这些砖作为工具包服务于联邦学习和安全多方计算以及隐私计算的目标。这些工具包本身还不能为我们解决想要解决的任务,因为我们的任务和目标是盖一座大楼,中间要利用到这些砖,即工具包。所以有的时候,我们所说的隐私计算指的是目标;有的时候指的是这些工具包。对于安全多方计算和联邦学习也是如此。
所以,我们说哪一个是哪一个的子集,哪一个是为哪一个服务,就要清楚我们说的是目标的概念,还是工具包的概念。我们可以看下图(右)。隐私计算作为目标来说,不同的技术路线都在试图解决它。但是,每个技术路线都有自己的特点,并有自己的工具包。这样来说,我们就可以解决谁到底是为谁服务的。我们一定要分清目标和工具包,工具包是为目标服务的。
有的时候,我们说联邦学习的目标可以用安全多方计算工具来解决,有时候安全多方计算的目标可以用联邦学习和差分隐私来解决。这些并不矛盾。
![]()
现在,隐私计算的发展已经有 40 年的历史,也经历了很多阶段。我们在这里总结一下这些阶段,相关信息出自最近我与陈凯老师以及很多优秀博士生合作完成的书籍《隐私计算》。
首先是安全多方计算,是理论计算机方向为整个计算机行业做出的贡献,即利用利用隐藏部分信息来保护隐私,基于各方交换的部分数据来计算正确的结果。这样做的好处是能够满足保护隐私的法律法规,但计算速度非常得慢。之后,出现了利用混淆个体的方式保护隐私的差分隐私技术和利用硬件来保护隐私的集中加密计算技术,它们都有各自的特点和问题。联邦学习是随着 AI 的发展,利用分布式多方建模的手段对模型作为一个主体进行生产,使用和管理而产生的。联邦学习和前面这些发明都不矛盾,不是替代关系,它们是相辅相成的。
我今天特别要讲的主题是「可信联邦学习」,这里面有一个词叫做 NFL(No-free lunch, 没有免费的午餐)。另外一个叫知识产权保护,下面会特别讲到这些概念。
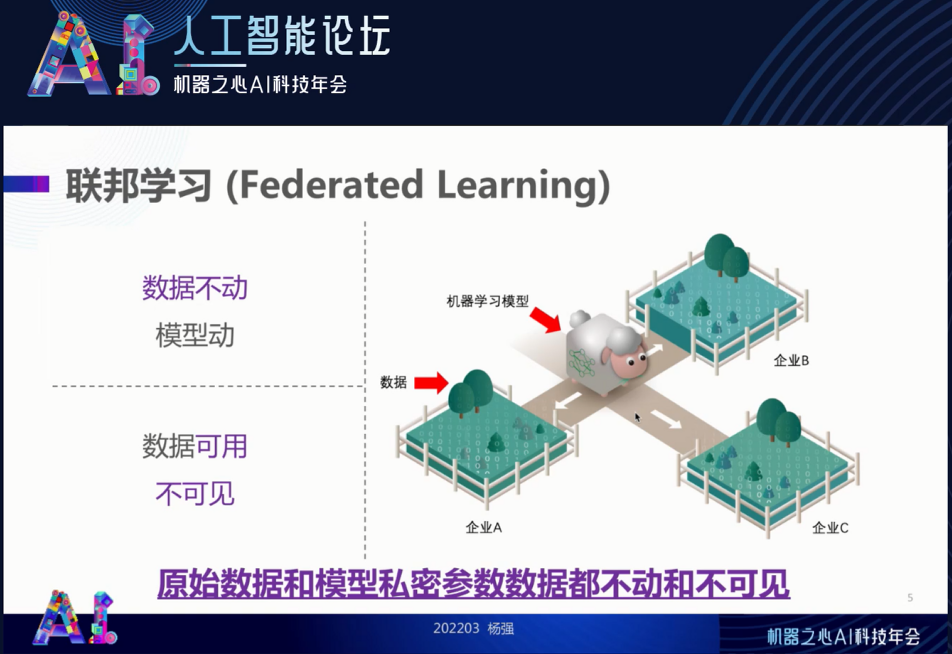
首先,我们简单地回顾一下联邦学习。我从一开始就说它的思想是「
数据不动模型动、数据可用不可见
」。有人认为这很好理解,但也有疑问:模型在不保护的前提下可以通过参数的传递泄露部分原始数据。我们说的数据不动模型动,意味着我们所设计的联邦学习算法,能保证原始数据和模型私密参数的数据都不能 “动”。如果模型参数泄露了原始数据,那这句话就成了空话。因此,联邦学习一定要严格地保证原始数据和重要模型参数真的原地不动,以保证联邦学习的安全。
![]()
下面再来说隐私保护、数据安全和模型效能到底是什么关系。所谓隐私,往往是对我们特别想要保护的部分数据而言,我们管这个数据叫 D(Data)。安全指的是整个系统的安全,也就是说,我们要保证所有数据 D 的安全。隐私往往特指要保证不泄露某些数据。所以,安全是指逻辑学里面的 “所有”(For all),而隐私是逻辑学里 “某些” 的概念。
同时,我们在说安全的时候,要绝对明确地定义出面对的 “威胁攻击” 的假设是什么,以及是怎么样的攻击。我们从教科书里面学到的是,这个攻击可以是半诚实的、恶意的、好奇的等。但是,我们一定要明确隐私计算和联邦学习系统所在的环境以及它可能受到的攻击到底是什么。
我在下图(右)列了两个极端,一个叫拜占庭式攻击,即某个参与者其实是坏人,或者部分时间是坏人,但混在参与者当中。还有一种攻击就像《三体》中水滴一样完全无法防御,这叫灾难式攻击(catastrophic threat),也叫极端性攻击。大部分情况下,我们面对的都是拜占庭式攻击。在这种攻击下,我们要确定自己的隐私保护到底是怎么样的。
所以,
隐私保护(P)可以用联邦学习框架、同态加密作为工具,也可以用安全屋、安全多方计算的某种计算模式作为工具包。如何保护取决于我们的任务到底是什么
。
![]()
总之,我们如果要给一个系统(如上图羊到多方吃草)定安全等级,绝对不能只看用的是联邦学习还是安全多方计算。我们一定要说自己保护的数据 D、威胁模型 T 和保护措施 P 到底是什么,在(D,P,T)三者都知道的情况下才可以定级。这个是真正的安全概念。
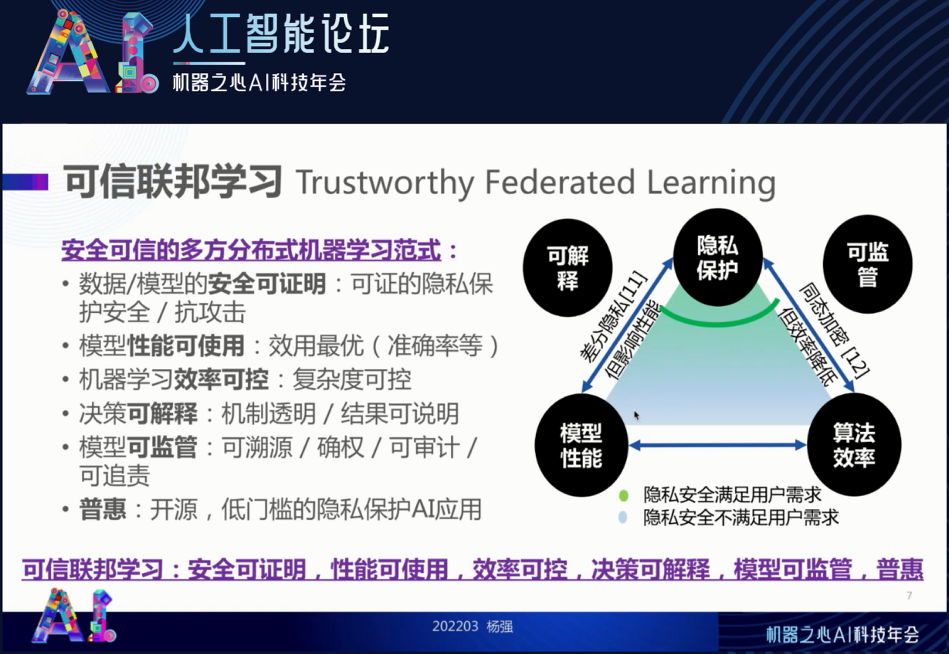
这就引出了我接下来要说的 “可信联邦学习”。我们刚才说的是安全、攻击和可能的威胁模式,但是不要忘记我们做所有这些事都是满足做到高效。一个叫做效用,如准确率、覆盖率等。还有一个是效率,即速度和计算复杂度。这两个我们都要一定保证,对于可信任的联邦学习而言,既要给出一个完整的安全证明,又要给出完整的性能和效率保证。
同时,由于我们有多方用户,有工程师,有终端用户,有监管,有社会大众。因此,这种模型的决策一定要机制透明、结果可解释,模型也要可监管可管理。也就是说,关于模型到底是谁的,我们可以溯源和确权。这个数据是谁的,我们可以审计。数据出了问题到底是谁的责任,我们可以追责。这就叫可监管。
另外,我们希望整个模型不是被少数垄断者所用,而希望大家都低成本地用起来这个技术,这就是 “普惠” 的概念。达到普惠的一种方式就是开源,以实现低门槛的隐私保护 AI 应用。
总结一下,我们所说的
可信联邦学习是指安全可证明、性能可使用、效率可控、决策可解释、模型可监管和普惠的
。下图三角形的节点都是我们所说的特性,它们之间其实是平衡的关系。可以看到从上到下绿色越来越浅,就是从隐私保护和模型性能的要求出发,在这个过程中划分边界。针对某个系统,这个边界到底应该划在哪呢?这是我下面要解决的问题,也即可信联邦学习如何落地。
![]()
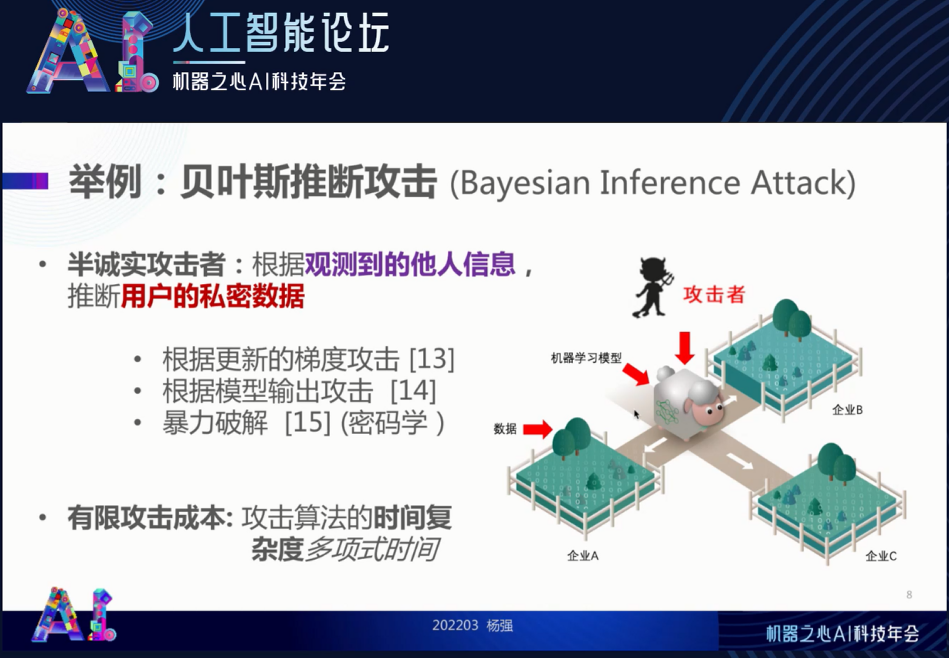
首先我们要清楚攻击的方式。在现实工作中,隐私有可能被泄露,有可能存在恶意的攻击者,也可能有好奇的人或参与者,如下图(右)所示。这个攻击者可以攻击我们的模型,对 “羊” 进行攻击,也可能是一个半诚实的攻击者,通过观测到了解羊和草料的信息,用以推断用户的隐私数据。我们称后面这种针对隐私的攻击为 “贝叶斯推断攻击”(Bayesian Inference Attack)。这种攻击覆盖很多的可能性,如通过梯度信息进行攻击的深度泄露型的攻击,就是观察合作者发过来的梯度并以此反猜用户的原始数据。此外还有通过输出的模型进行隐私攻击和以及暴力破解等(故意地猜密码)。
我们的目的是要
增加攻击者的成本,让攻击算法的复杂度足够的高
,使之在有效的时间内就没有办法进行完整的对其有益的攻击。这是我们安全保障所希望达到的目标。
![]()
那么,贝叶斯推断攻击下,是不是把安全指标推到最高就可以了呢?不要忘记,我们还有一个要求,就是在保证安全的同时,我们系统的效能也好!如果一个系统极为安全,但准确率极低,那这个系统是不能落地的。
所以,我们要在安全和效能之间划一个最佳的平衡点,最大化我们的效能和安全,使得这两者都可以得到兼顾
。
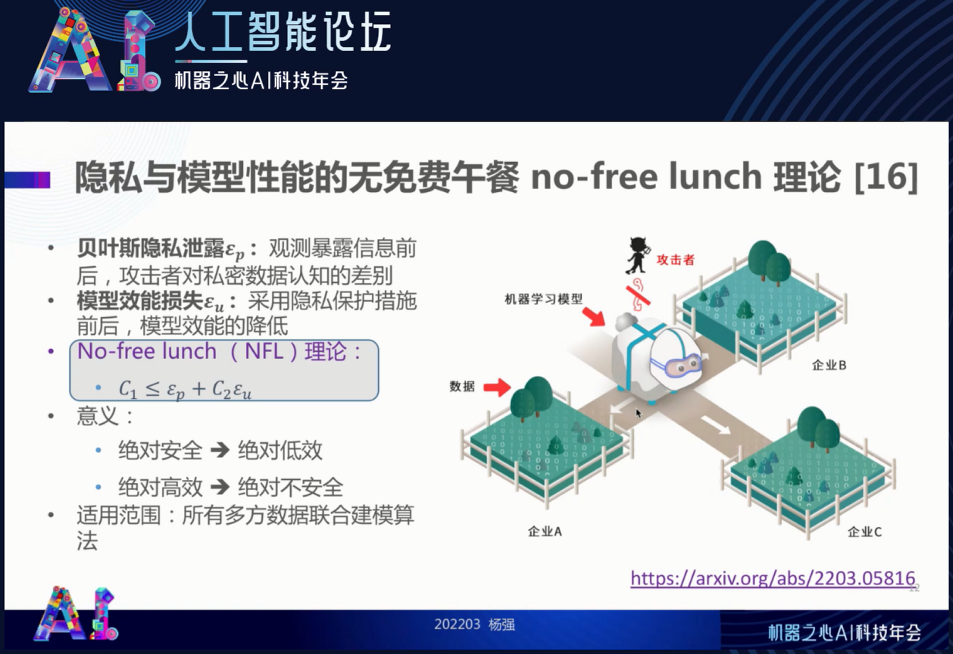
有没有可能我们在隐私计算当中,将安全和效能同时都最大化呢?下面引入可信隐私计算里面一个最新的重要成果,叫做
「No-free lunch(无免费午餐)定理」
,这个定理告诉我们信息的相互泄露和模型效能是互相制约的。了解了这个制约规律有助于我们设计即实用又安全的隐私计算和联邦学习系统。以下是我们小组最近做的一项重要理论工作。
简单而言,对于满足贝叶斯隐私的多方计算系统而言(即覆盖整个隐私计算),只要有多方的系统,安全和效能分别作为一个因子,两者的和是有上界的,它是一个正常数。我们想要安全大,效能就不可能这么大;要效能最大,信息泄露方面就得做出让步。因此,两者之间如何达到最好的平衡,就是要看我们系统设计的聪明程度了。但是,并不像有些人所说的那样,为了追求极度的安全而不管效能;我们也不可能像有些学术文章中假设的那样效能是极大的,而不去管安全。
这个定理的证明很费劲,我把文章的链接发给大家,而这里只做其结果的介绍。我们要假设有一种隐私泄露 ——
贝叶斯隐私泄露
,通过观察某些参与者互相之间交换的信息来反猜这个数据。就像下图中这只不幸的小羊,效能的损失我们也给出一个量,如果羊保护的太严密,它没有足够的草吃,会长不大。这两个损失,就是效能和安全的损失,可以用错误率表达,它们值的和是大于等于一个常数的。效能和安全的最佳平衡也要受到这个公式的制约。
![]()
我特别要解释一下隐私计算的 “无免费午餐定理” 的意义。
首先,它可以指导设计隐私保护多方计算的算法,满足用户「防止贝叶斯隐私泄露」的要求,同时使得性能损失最小。我们可以用来加噪声和差分隐私,传递部分参数数据,同态加密以保护这些参数数据或者部分参数数据,也可以用来保护安全多方计算的通用保护机制。
总之,如下图(右)所示,我们可以在安全与效能之间找到一个最佳的平衡点。相关文章已放在了 arXiv,感兴趣的读者可以下载阅读。
论文地址:https://arxiv.org/abs/2203.05816
![]()
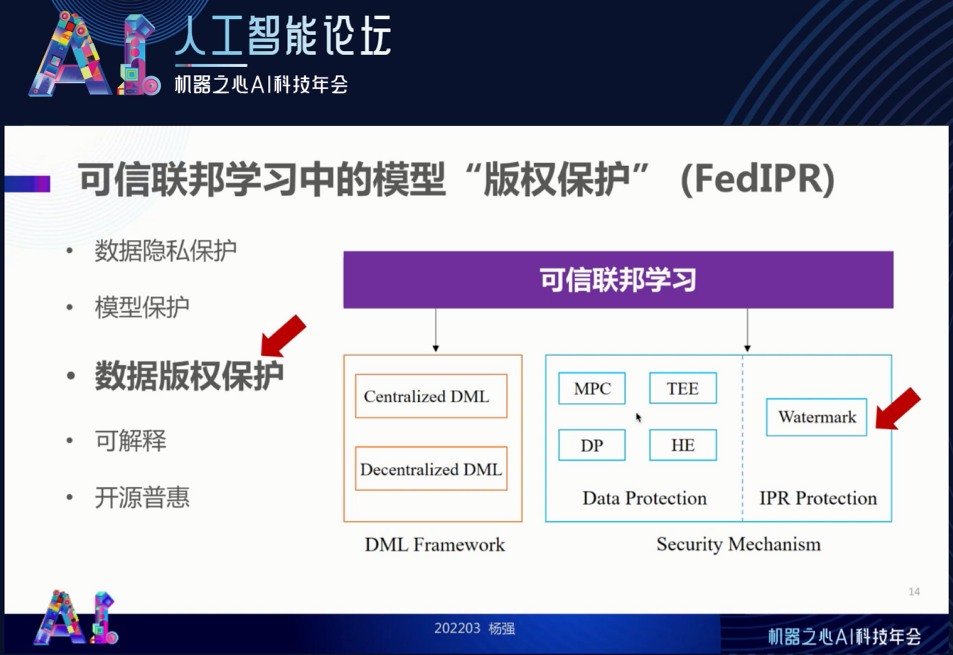
前面讲了安全以及如何利用安全与效能的「无免费午餐」定理来设计一个最佳的算法。接下来我们考虑可信联邦学习中的版权保护问题。
这里所说的版权不是指书和文章的版权,而是模型和数据的版权。我们将它叫做 FedIPR,“联邦知识产权”。
我们怎么样解决版权的计算、保护和管理呢?我们可以通过在模型里面加水印(Watermark)的方法解决。
![]()
首先来看如果不保护模型可能发生什么呢?模型有可能被盗窃、被贩卖,就像很久以前的盗版光碟一样。此外,由于联邦学习是多方参与的,也许有人会滥竽充数,也就是他其实没有贡献数据和模型,但却对一个更新后的模型加以使用。这种就叫滥竽充数。还有一种是剽窃,比如剽窃你的数据或参数来学习你花了很大精力才得到的结果。
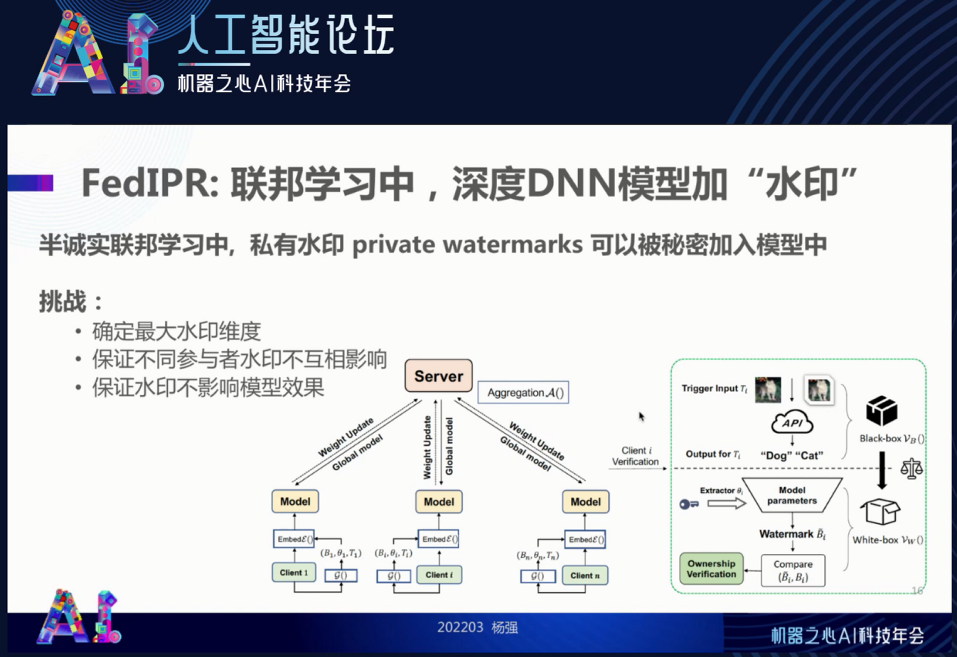
我们假设自己是在这种服务器方传递的过程中需要保护可信参与方里面的模型,该如何去做呢?水印的设计取决于一个概念:
私有水印
。每一个参与方都可以秘密地把自己特有的私有水印加入模型里面,所以在与服务器的交换中这个水印是被烙在通用模型里面的。要做到这一点,我们的水印等于是一个 “嵌入” (Embedding)。它的维度是越大越好,这样才能保证容量足够得大,参与方足够多,不同参与方的水印互相不影响,也不会影响模型的效果。但一个嵌入的维度也是有代价的,因此也要找一个最优嵌入维度。
![]()
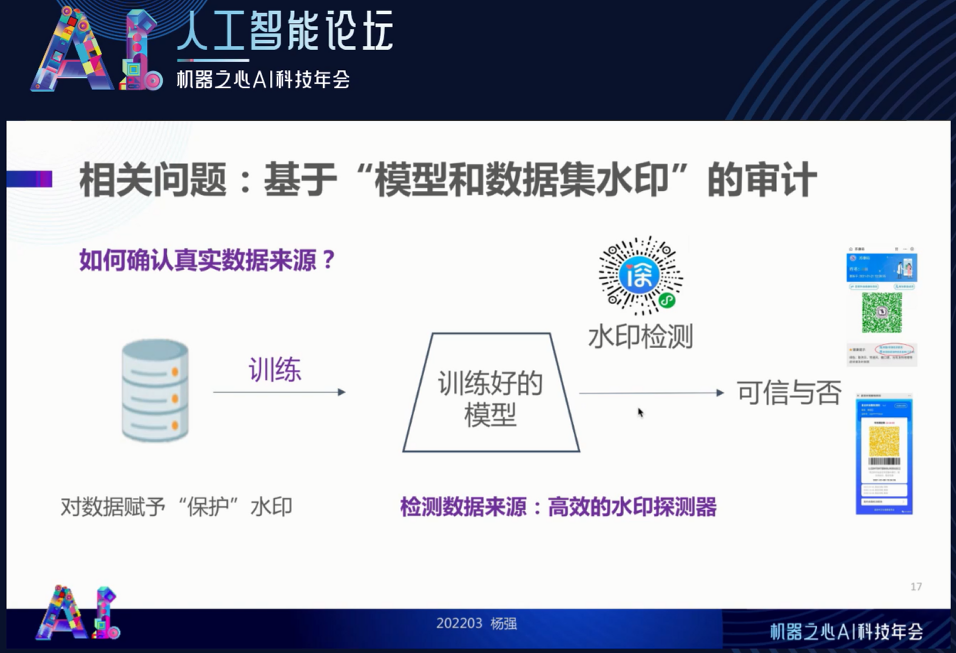
我们最近也做了一个工作,找到了最佳水印维度的方法。利用这一方法,我们训练一个模型(下图从左到右),然后用同样的方法确认这个模型的归属和来源,确定它是合法的。同时,我们可以提供一个水印检测,就像核酸检测一样,会产生像绿码一样的水印探测结果。同样的手段也可以用在对外来数据的确权管理上。
![]()
最后简单回顾一下联邦学习的发展,它在 2016 至 2018 年期间逐步完善,集中在横向联邦、多参与方和终端。然后,我们在 2018 年提出了纵向联邦、联邦迁移学习,异构数据和模型之间的联邦学习,并在激励机制、自动化联邦学习等领域不断地推进。可以说,现在联邦学习不管在学术上还是在实践上都有了长足的进展。
首先是
标准
。我们在去年 3 月份发布了联邦学习标准,之后又有多个国内和国际的标准发布,包括编写中的标准。这里特别提一下中国电信领衔制作的联邦学习安全标准 IEEE P2986。
同时,我们现在逐步完善了全球首个隐私计算和联邦学习开源社区 —— FATE。目前,该社区有 3000 多个个人参与者(工程师与开发者),以及 800 多家企业机构。我担任指导委员会主席,并有幸邀请到清华大学唐杰教授任指导委员会名誉主席。我们有非常专业的治理架构、技术指导委员会和专业委员会等,并且有大量的主流参与者、贡献者以及社区主要贡献方。这也是我们可信联邦学习的 “普惠” 维度的一个具体体现。
该平台作为一个基准服务了很多企业级联邦学习和工业级平台,并支持多个主流算法。在可信联邦学习这个维度上,我们希望利用 FATE 现有资源向前迅猛推进,带领整个全球的隐私计算向前发展。同时,我们也欢迎大家积极地参与进来。
![]()
我们在联邦学习领域取得的成就也是有目共睹的,在去年终于被纳入 Gartner 技术成熟度曲线,这是对我们的肯定。我们还有很多案例,比如利用可信联邦学习制作智能培训机器人和坐席助手机器人,真正实现语音对话以及图像功能,从而综合地对人产生协助,对业务做出贡献。
同时,“可解释性” 是可信联邦学习的一个重要部分。在这方面,我们正在撰写一本书并且马上就会出版。这本书叫做《可解释人工智能导论》,希望大家加以关注。
![]()
总的来说,可信联邦学习是联邦学习的又一个进步和一个新的发展阶段。应该说,可信联邦学习是对整个隐私计算的一个新观点。这个观点首先基于我们终于发现在整个隐私计算领域,效能和安全其实需要一个最优化平衡。在保证安全的前提下如何能够最大化效能,这个就是我们算法设计的核心。同时,我们要保证对威胁模型、保护模型、知识产权保护给出很好的定义,使得模型可解释,并且整体普惠。我们 FATE 开源社区在可信联邦学习上不断进取。
要达到可信联邦学习的目标,我们需要大家的共同努力,一起向前发展。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com