Dynamic Zoom-in Network 论文笔记
Dynamic Zoom-in Network for Fast Object Detection in Large Images CVPR 2018 论文 论文链接 https://arxiv.org/abs/1711.05187
1.摘要
作者提出了一个用于检测高分辨率图像中不同尺度目标的方法,减少计算量的同时,保证了检测的准确率。整体是一个从粗糙到精细(coarse-to-fine)的检测流程。先使用 R-net 检测下采样的图像,再使用 Q-net 通过强化学习选择能提高准确率的区域进行放大检测。最后实验表明,相比于直接检测高分辨率图像,作者的方法在自己的数据集上减少了 50% 的像处理,同时保证准确率不降低。
2.Dynamic zoom-in network
受 GPU 等硬件的限制,通常不能直接处理高分辨率图像。常见的处理方法有: (1)将图像划分为子图,分别检测,整合结果,检测结果较准确,但计算量较大; (2)下采样图像,检测速度较快,但检测小目标的准确率较低。 作者提出的方法,减少处理时间的同时保证了检测准确率,看一下他是怎么做的。
检测框架分为两个子网络,R-net 和 Q-net。不过,严格的说应该有四个网络,两个检测网络,一个状态生成网络,一个动作预测网络。大体流程如下:
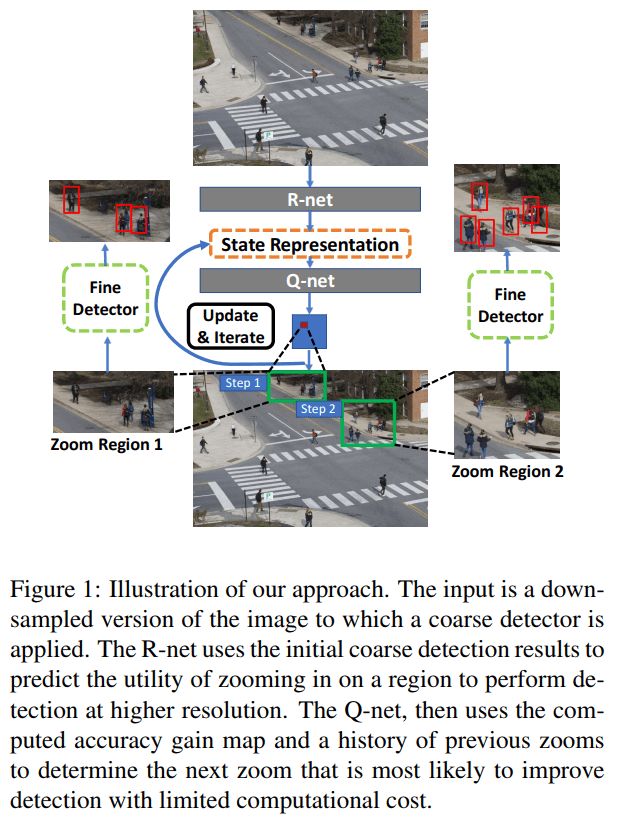
输入一幅下采样的图像,先粗糙(coarse)检测,然后 R-net 输出一个得分图,尺寸与输入图像相同。对于那些使用精细检测能提高 AP 的区域,得分较高;粗糙检测可以直接得到较好结果的区域,得分较低。
将得分图输入到 Q-net,通过强化学习,选择一个最优的放大检测区域,然后进行精细(fine)检测,同时将得分图上对应处理过的区域置0。迭代此过程,直到整个得分图的值都很小为止。
2.1 问题表示
Action (x,y,h,w) 表示放大区域动作。
State 表示当前检测状态,由两部分组成: (1)待分析区域的 accuracy gain; (2)已经在高分辨图像中分析过的区域历史记录。 作者使用 AG map 表示上述部分。AG map 与 R-net 的输入图像大小一致。AG map 中每个像素值表示如果放大区域包含该像素值,那么有多大的可能性提升检测准确率。 因此可以根据 AG map 上像素值大小确定最优 action。当选择一个 action 后,被选择区域的 AG 值会降低,因此 AG map 可以动态的记录 action 历史。
Cost-aware reward function 表示某 state s 下某 action a 的 reward 函数,在 DQN 中使用。
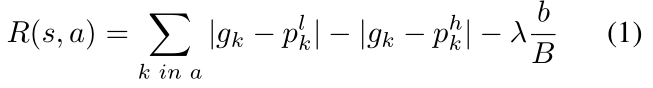
前两项衡量了检测准确率提升得分(accuracy improvement),最后一项衡量了放大指定区域的计算开销(cost increment)。
k in a 表示 action a 包含的所有 proposals k。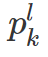
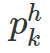
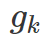
b 表示被选择区域的像素个数,B 表示整个图像像素个数。
R(s,a) 的作用:训练时,Q-net 使用 R(s,a) 计算即时奖励,并通过 Q-learning 学习长时(long-term)奖励。
2.2 Zoom-in accuracy gain regression network
R-net 依据粗糙检测器来预测放大指定区域的准确率收益。R-net由一对粗糙和精细检测器训练而来,因此可以由两者之间的相关性学习到合适的准确率收益。
使用两个预训练的检测器和一组训练图片,并分别获得两组检测结果: (1)低分辨率检测:使用下采样的图像,检测结果包括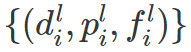
(2)高分辨率检测:使用高分辨率图像,检测结果包括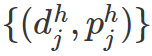
d 是 bounding box,p 是目标概率,f 是检测结果对应的特征向量。
作者提出了一个 match layer 来匹配有关系的低分辨率和高分辨率检测结果: 如果高分辨率 bbox 预测结果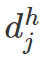
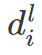
通过 match layer 得到一组关系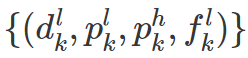
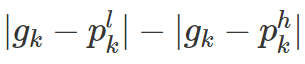
当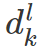
总结一下,就是得分小于0,低分辨率检测效果好,得分接近于0,那么高分辨率低分辨率效果相似,得分大于0,高分辨率检测效果好。
作者提出了一个 Correlation Regression(CR) Layer 来估计 proposal k 的放大准确率收益,优化目标为:
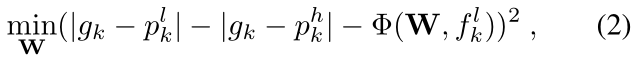
其中 Φ 表示要学习的回归函数,本文用两个 FC 层表示,FC1 有4096个单元,FC2 只有1个输出单元。
用 CR 层预测每个 proposals 的放大收益,并假设某个 proposal 中的每个像素对 accuracy gain 有相同贡献,那么 AG map 可以定义为:
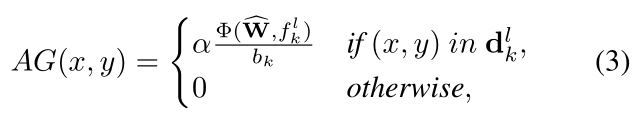
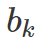
2.3 Zoom-in Q function learning network
Q-net 部分使用强化学习的方法,输入 state(AG map),输出一个最优动放大动作。
强化学习使用的是 Nature 版的 DQN 算法,与最初版的 DQN 相比,使用了一个参数延迟于 Q 网络 C 步的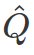
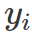
Nature DQN 算法流程如下:

本文作者没有对算法做改动。上述算法对应到论文中: Q-net 输入网络的 state 为 AG map,输出 n 个不同的动作,通过作者的描述和 Figure 2 可以看出,这些动作(放大区域)是预先设定好大小的。
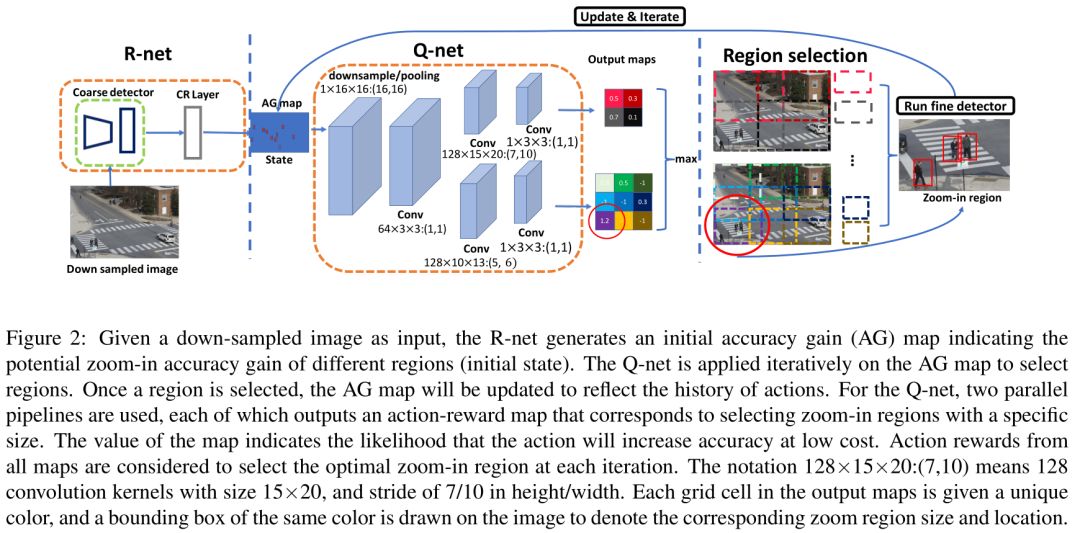
以 Figure 2 为例,输出两种大小的放大动作,分别将将原图划分2x2个和3x3个区域,一共13个动作,每个动作有一个得分,选择得分最高的区域进行放大检测。
reward 函数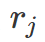
Window selection refinement
Q-net 输出动作后,由于动作(选择区域)是固定的,为了提高 reward,可以对选择的区域位置进行微调。微调策略如下:
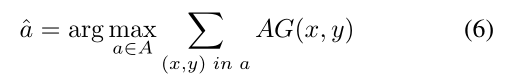
其中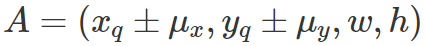
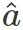
3.实验细节
由于 COCO 等常规数据集图像尺寸较小,因此作者使用了自己处理的数据集,用于行人检测: (1)CPD数据集,原始分辨率640x480,低分辨率400x300,高分辨率800x600; (2)WP数据集,低分辨率长边1000像素,高分辨率长边2000像素。
3.1 Baseline 方法
Fine-detection-all 使用精细检测器检测高分辨率图像。结果准确率高,但计算量大。
Coarse-detection-all 使用粗糙检测器检测下采样的图像。
GS+Rnet 使用贪婪搜索策略(greedy search,GS)代替 Q-net,每次搜索 AG map 上奖励最高的区域放大检测,不考虑 long-term reward。
ER+Qnet R-net 训练时,不考虑精细和粗糙检测器的关系,使用粗糙检测器结果的交叉熵作为区域得分,具体计算如下:
相当于只考虑低分辨率检测结果,物体概率高熵低则不放大,物体概率低熵高则就放大。
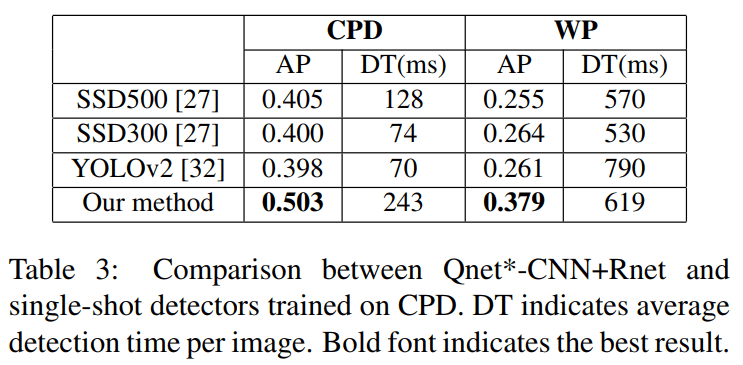
SSD and YOLO2 两个single-stage检测器。
3.2 变体方法
作者对上述方法进行改动,提出了一些变体方法:
Qnet-CNN 即上述使用 CNN 的 Q-net,如 Figure 2 所示。不包括窗口微调。
Qnet* 即 Qnet-CNN+窗口微调。
Qnet-FC 使用两个全连接层代替 Q-net 中的 CNN。
Rnet* 用“不包含放大开销的 reward 函数”训练的 R-net,即 reward 函数中 λ=0。
3.3 评测指标
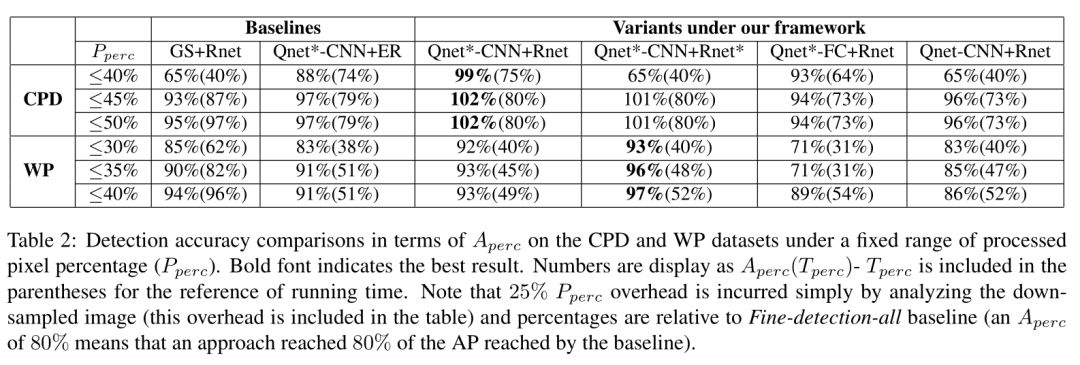
实验的评测标准以 Fine-detection-all 为基准,评测标准如下,其中后两项用于衡量计算耗时: Aperc 带评测检测器 AP 占 Fine-detection-all 结果百分比; Pperc 处理像素百分比; Tperc 检测用时百分比。
4. 实验结果
region refinement 效果

可以看出,由于微调前 Q-net 输出的放大区域是固定的,可能出现区域只包含目标某一部分的情况。微调后这种情况得到改善。
Q-net*-CNN 效果

通过第一列可以看出,贪婪搜索每次只考虑当前最大 reward,导致出现很多重复的选择区域。 Q-net 考虑的是 long-term reward,每次选择的不一定是最优区域,但是整体考虑,Q-net 搜索次数少,几乎没有重复选择的区域。
R-net 效果

Figure 5 对比了 R-net 和 ER 的区别。
其中 C 和 F 分别表示粗糙和精细检测器预测红框是行人的概率,红色值表示 R-net 预测的 accuracy gain,蓝色的值表示使用交叉熵损失。
Baseline 评估结果
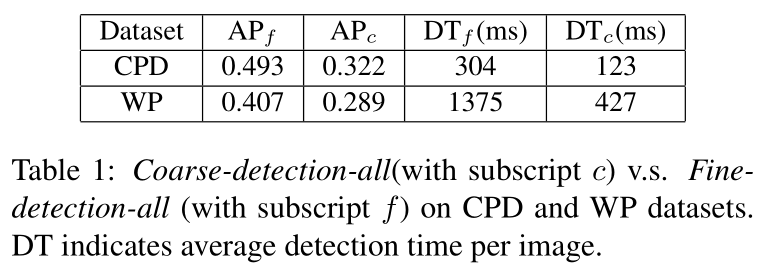
c,f 分别表示 coarse-detection-all 和 fine-detection-all 两种检测结果。
作者提出的方法及其变体
与 single-stage 检测器对比
参考资料
[1] Human-level control through deep reinforcement learning https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf [2] DQN从入门到放弃6 DQN的各种改进 https://zhuanlan.zhihu.com/p/21547911



