神经网络可解释性最新进展
【导读】近日,Google在distill发表文章“The Building Blocks of Interpretability” 探讨了特征可视化如何与其他神经网络的解释性技术结合起来,从而帮助人们理解神经网络如何做出决策。同时,Google还公布一套基于DeepDream打造的神经网络可视化库——Lucid,用于制作清晰的特征可视化图像。本文对文章细节进行整理和介绍,文末给出了相关博客、视频和GitHub链接。
2015年,谷歌曾尝试去弄清神经网络理解图像的方式,结果产生了迷幻图像(psychedelic images),后来,谷歌把其代码开源,称为“DeepDream”。它引领了一系列艺术运动,通过该代码可以产生很多神奇的艺术图像,但其对于弄清楚“神经网络理解图像的方式”的帮助似乎有限。但谷歌不愧是国际互联网巨头,并没有放弃DeepDream及其背后的研究,它试图解决深度学习领域让人诟病的难题:神经网络本身的运作方式是怎样的?
去年,谷歌在网络期刊 《Distill》上发表了相应的文章,介绍了这些技术是如何揭示单个神经元的工作原理的。向我们展示了神经网络的中间神经元是如何检测各种各样的物体的,如纽扣、布块、建筑物等,以及这些神经元如何在网络层层面构成更加复杂的网络结构。

虽然上述工作令人兴奋,但是谷歌忽略了讨论重要的一点:这些神经元如何组合成神经网络并进行工作呢?
2018年3月7日,谷歌发布了一篇最新的文章“The Building Blocks of Interpretability”, 探讨了特征可视化如何与其他神经网络的解释性技术结合起来,从而帮助人们理解神经网络如何做出决策。谷歌证明了文中介绍的技术可以让谷歌“站在神经网络的角度”,并理解神经网络做出的一些决定,以及它们如何影响最终的输出。例如,谷歌技术人员可以看到神经网络如何检测到一个“垂耳”,然后增大图像是“拉布拉多犬”或“比格犬”的概率。
谷歌探索了理解神经网络中哪些神经元处于激活状态的技术。一般情况下,如果我们询问哪些神经元被激活,通常会得到一些没用的答案,如“某一个神经元被触发了”,这个答案对专家来说帮助不大。谷歌提出的方法通过可视化每个神经元,使其变得更加有意义,如给出“垂耳检测器被激活”。

谷歌同样可以缩小和显示整幅图像,展示不同层如何对图像进行感知,这允许我们看到网络从检测简单的边,到细致的纹理、三维结构,再到高级结构(如耳朵、鼻子、头和腿)的过渡过程。

谷歌将这个过程与神经网络的最终决策联系起来,最终我们不仅可以看到神经网络检测到的“垂耳”,也可以看到如何增加图像被标注为“拉布拉多犬”的可能性。
在本文中,谷歌将现有的可解释性方法视为丰富用户界面的基础和可组合的模块,并发现,这些不同的技术现在汇聚在一个统一的语法中,在最终的界面中实现可以互补。而且,这个语法使得我们能够系统性地对可解释性界面空间进行探索,使我们可以评估它们是否与特定的目标相符合。谷歌在文中解释了网络是如何对其理解进行开发的,同时保持人类规模(Human-Scale)的大量信息。例如,我们将看到一个检测“拉布拉多犬”的网络是怎样一步步检测到它的“垂耳”,以及“垂耳”是如何影响分类的。
▌解密隐藏层
近期关于可解释性的大部分工作都涉及神经网络的输入和输出层。可以说,这是由于这些层具有明确的含义:在计算机视觉中,输入层代表输入图像中每个像素的红色,绿色和蓝色通道值,而输出层则是类标签以及每个标签相关的概率。
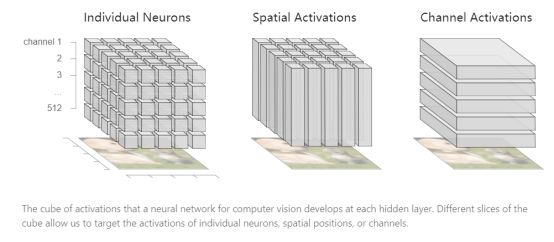
然而,神经网络的强大之处在于其中的隐藏层,在每一层,网络都会有新的输入。在计算机视觉中,神经网络在图像的每个位置运行相同的特征检测器。我们可以将每一层的表示看作一个三维立方体。立方体中的每个单位都是一个激活。x轴和y轴对应图像中的位置,z轴是正在运行的检测器。
但是这些激活理解起来是非常困难的,因为我们通常把它们当作抽象的向量来处理。
然而,通过功能可视化,我们可以将这个抽象向量转换成更有意义的“语义词典”。

为了制作一个“语义词典”,我们将每个神经元激活与该神经元的可视化进行配对,并根据激活的大小对它们进行排序。 激活与特征可视化的结合改变了我们与数学对象的关系。 激活现在映射到可视化图像中,而不是抽象的索引,如“垂耳”,“狗鼻子”或“毛皮”。
“语义词典”的强大之处除了它们能够摆脱无意义的索引之外,还有它们用典型的样本表达了神经网络的已学习抽象。通过图像分类,神经网络学习了一组视觉抽象,图像是对它们进行表示的最自然的方法。
语义词典为谷歌的可解释性技术奠定了基础,使其成为可组合的构建。
▌网络看到的是什么?
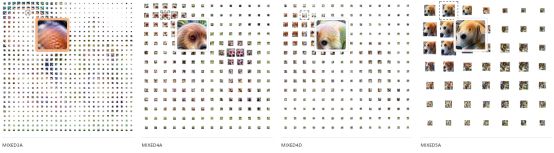
“语义词典”让我们对激活进行了详细的研究:每个单个神经元能够检测到什么? 建立这种表示,我们也可以考虑一个整体的激活向量。 我们可以代替将单个神经元可视化,而是可视化在给定空间位置处的神经元组合(具体来说,我们优化图像以最大化激活点与原始激活向量的点积)。

将这种技术应用于所有的激活向量,我们不仅可以看到网络在每个位置上检测到什么,还可以看到网络对整个输入图像的理解。
而且,通过跨层(例如“mixed3a”,“mixed4d”)的工作,我们可以观察到网络的理解是如何发展的:从检测先前层的边缘到后者中更复杂的形状和目标物体部分。

然而,这些可视化忽略了一个关键的信息:激活的大小。通过按激活向量的大小来缩放每个单元的面积,我们可以指出网络在该位置检测到的特征有多强:
▌如何组装概念?
特征可视化能帮助我们回答“网络看到的是什么?”问题,但是它没有回答网络如何组装这些单独的特征片段来实现后来的决策,或者为什么做出这些决策。
归因(Attribution)是一组通过解释神经元之间的关系来回答这些问题的技术。 有各种各样的归因方法,但到目前为止,似乎没有明确的答案。 事实上,我们有理由认为我们目前的所有答案都不完全正确。 我们认为有很多关于归因方法的重要研究,但就本文而言,确切归因方法并不重要。 我们使用一种相当简单的方法线性地近似关系,但可以很容易地用任何其他技术来替代。 未来对归因的改进,当然会相应地改善基于它们的界面。
具有显著图的空间归因:最常见的归因界面称为显著图(saliency map,是一种简单的热图,它突出显示输入图像中最能引起输出分类的像素。这种方法存在两个缺陷:首先,不清楚单个像素是否应该是归属的主要单位;其次,传统的显著图非常局限,一次只显示一个类的归因,并且不允许你对单个点进行更深入地探究。
通道归因(channel attribution):
显著性映射通过对隐藏层的空间位置应用归因来隐式切割激活立方体。 这结合了所有渠道,因此我们无法确定每个位置上的哪个特定检测器对最终输出分类贡献最大。
▌人类尺度
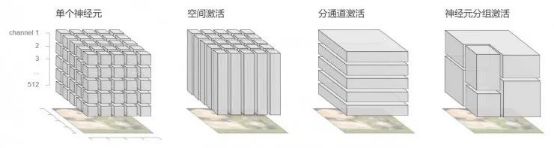
在前面的章节中,我们已经考虑了将激活立方体切片的三种方式:空间激活,通道和单个神经元。 其中每个都有重大缺点。 如果只使用空间激活或通道,将错过图像中非常重要的部分。 例如,“垂耳”探测器帮助我们将图像归类为拉布拉多犬,但是当它与这样做的位置相结合时,它更加有趣。 人们可以尝试深入到神经元的层面来描述整个图像,但数以万计的神经元信息太庞大。 即使是数百个通道,在被分成单独的神经元之前,也可能会让用户无法接受!
因此,需要将神经网络处理的信息进行精简,到“人类尺度”的范畴。
这是非常关键的步骤,因此需要找到更有意义的方式来将激活分解开来。很多时候,某些通道或者空间位置高度相关相互协作,可以视为一个单位;而其他通道或位置激活很少,从高层视角来看可以忽略不计。所以,如果找到合适的工具,我们应该可以更好地分解这些激活。
具体过程可参考链接:
https://distill.pub/2018/building-blocks/
▌可解释性界面
本文提供的界面思想结合了构建模块,例如特性可视化和属性。组合这些片段不是一个任意的过程,而是遵循一个基于界面目标的结构。例如,如果界面强调了网络识别的内容,优先考虑它的理解是如何发展的。为了评估这些目标,并理解权衡,我们需要有系统地考虑可能的替代方案。因此,可以将界面视为各个元素的联合。
具体过程可参考链接:
https://distill.pub/2018/building-blocks/
▌总结
我们相信与神经网络交互的空间很丰富。我们还有很多工作要做,以建立强大的、值得信赖的界面,提供可解释性。如果我们成功了,解释能力将成为一个有力的工具,使我们能够实现有意义的人类监督,并建立公平、安全、协调的人工智能系统。
相关链接:
“The Building Blocks of Interpretability”地址:
https://distill.pub/2018/building-blocks
YouTube地址:
https://www.youtube.com/watch?v=pVgC-7QTr40
DeepDream地址:
https://research.googleblog.com/2015/07/deepdream-code-example-for-visualizing.html
Lucid地址:
https://github.com/tensorflow/lucid
Distill地址:
distill.pub/2018/building-blocks/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



