计算机视觉近一年进展综述
·Introduction
Computer Vision typically refers to the scientific discipline of giving machines the ability of sight, or perhaps more colourfully, enabling machines to visually analyse their environments and the stimuli within them. This process typically involves the evaluation of an image, images or video. The British Machine Vision Association (BMVA) defines Computer Vision as “the automatic extraction, analysis and understanding of useful information from a single image or a sequence of images.”[1]
The term understanding provides an interesting counterpoint to an otherwise mechanical definition of vision, one which serves to demonstrate both the significance and complexity of the Computer Vision field. True understanding of our environment is not achieved through visual representations alone. Rather, visual cues travel through the optic nerve to the primary visual cortex and are interpreted by the brain, in a highly stylised sense. The interpretations drawn from this sensory information encompass the near-totality of our natural programming and subjective experiences, i.e. how evolution has wired us to survive and what we learn about the world throughout our lives.
In this respect, vision only relates to the transmission of images for interpretation; whilecomputing said images is more analogous to thought or cognition, drawing on a multitude of the brain’s faculties. Hence, many believe that Computer Vision, a true understanding of visual environments and their contexts, paves the way for future iterations of Strong Artificial Intelligence, due to its cross-domain mastery.
However, put down the pitchforks as we’re still very much in the embryonic stages of this fascinating field. This piece simply aims to shed some light on 2016’s biggest Computer Vision advancements. And hopefully ground some of these advancements in a healthy mix of expected near-term societal-interactions and, where applicable, tongue-in-cheek prognostications of the end of life as we know it.
While our work is always written to be as accessible as possible, sections within this particular piece may be oblique at times due to the subject matter. We do provide rudimentary definitions throughout, however, these only convey a facile understanding of key concepts. In keeping our focus on work produced in 2016, often omissions are made in the interest of brevity.
One such glaring omission relates to the functionality of Convolutional Neural Networks (hereafter CNNs or ConvNets), which are ubiquitous within the field of Computer Vision. The success of AlexNet [2] in 2012, a CNN architecture which blindsided ImageNet competitors, proved instigator of a de facto revolution within the field, with numerous researchers adopting neural network-based approaches as part of Computer Vision’s new period of ‘normal science’.[3]
Over four years later and CNN variants still make up the bulk of new neural network architectures for vision tasks, with researchers reconstructing them like legos; a working testament to the power of both open source information and Deep Learning. However, an explanation of CNNs could easily span several postings and is best left to those with a deeper expertise on the subject and an affinity for making the complex understandable.
For casual readers who wish to gain a quick grounding before proceeding we recommend the first two resources below. For those who wish to go further still, we have ordered the resources below to facilitate that:
What a Deep Neural Network thinks about your #selfie from Andrej Karpathy is one of our favourites for helping people understand the applications and functionalities behind CNNs.[4]
Quora: “what is a convolutional neural network?” - Has no shortage of great links and explanations. Particularly suited to those with no prior understanding.[5]
CS231n: Convolutional Neural Networks for Visual Recognition from Stanford University is an excellent resource for more depth.[6]
Deep Learning (Goodfellow, Bengio & Courville, 2016) provides detailed explanations of CNN features and functionality in Chapter 9. The textbook has been kindly made available for free in HTML format by the authors.[7]
For those wishing to understand more about Neural Networks and Deep Learning in general we suggest:
Neural Networks and Deep Learning (Nielsen, 2017) is a free online textbook which provides the reader with a really intuitive understanding of the complexities of Neural Networks and Deep Learning. Even just completing chapter one should greatly illuminate the subject matter of this piece for first-timers.[8]
As a whole this piece is disjointed and spasmodic, a reflection of the authors’ excitement and the spirit in which it was intended to be utilised, section by section. Information is partitioned using our own heuristics and judgements, a necessary compromise due to the cross-domain influence of much of the work presented.
We hope that readers benefit from our aggregation of the information here to further their own knowledge, regardless of previous experience.
From all our contributors,
The M Tank
Part One: Classification/Localisation, Object Detection, Object Tracking
Classification/Localisation
The task of classification, when it relates to images, generally refers to assigning a label to the whole image, e.g. ‘cat’. Assuming this, Localisation may then refer to finding where the object is in said image, usually denoted by the output of some form of bounding box around the object. Current classification/localisation techniques on ImageNet[9] have likely surpassed an ensemble of trained humans.[10] For this reason, we place greater emphasis on subsequent sections of the blog.
Figure 1: Computer Vision Tasks
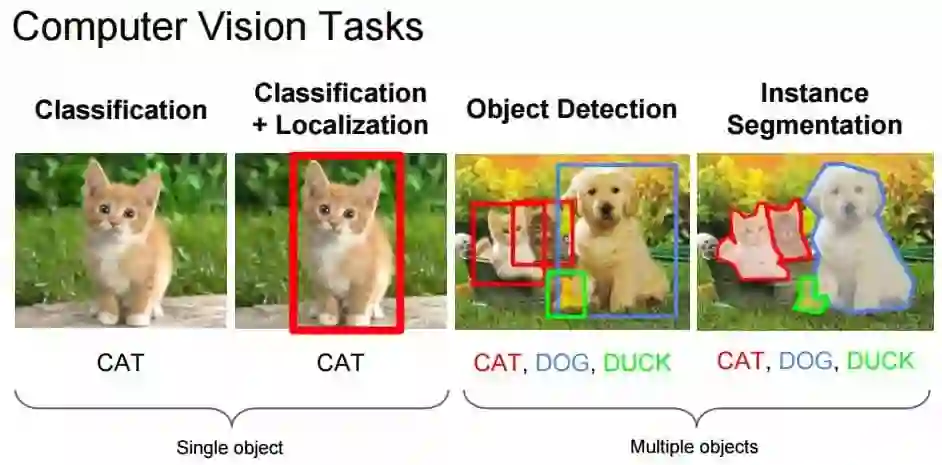
Source: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, Lecture 8 - Slide 8, Spatial Localization and Detection (01/02/2016). Available: http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
However, the introduction of larger datasets with an increased number of classes[11] will likely provide new metrics for progress in the near future. On that point, François Chollet, the creator of Keras,[12] has applied new techniques, including the popular architecture Xception, to an internal google dataset with over 350 million multi-label images containing 17,000 classes. [13],[14]
Figure 2: Classification/Localisation results from ILSVRC (2010-2016)
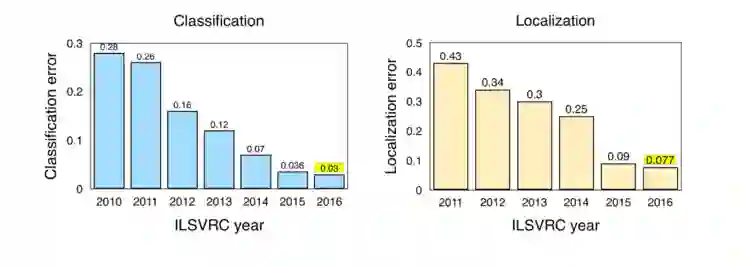
Note: ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The change in results from 2011-2012 resulting from the AlexNet submission. For a review of the challenge requirements relating to Classification and Localization see: http://www.image-net.org/challenges/LSVRC/2016/index#comp
Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2. Available:http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
Interesting takeaways from the ImageNet LSVRC (2016):
Scene Classification refers to the task of labelling an image with a certain scene class like ‘greenhouse’, ‘stadium’, ‘cathedral’, etc. ImageNet held a Scene Classification challenge last year with a subset of the Places2[15] dataset: 8 million images for training with 365 scene categories.
Hikvision[16] won with a 9% top-5 error with an ensemble of deep Inception-style networks, and not-so-deep residuals networks.
Trimps-Soushen won the ImageNet Classification task with 2.99% top-5 classification error and 7.71% localisation error. The team employed an ensemble for classification (averaging the results of Inception, Inception-Resnet, ResNet and Wide Residual Networks models[17]) and Faster R-CNN for localisation based on the labels.[18] The dataset was distributed across 1000 image classes with 1.2 million images provided as training data. The partitioned test data compiled a further 100 thousand unseen images.
ResNeXt by Facebook came a close second in top-5 classification error with 3.03% by using a new architecture that extends the original ResNet architecture.[19]
链接:
http://www.themtank.org/a-year-in-computer-vision
原文链接:
https://m.weibo.cn/1402400261/4177997059278344




