用模型不确定性理解模型
随着深度神经网络功能越来越强大,它们的结构也越来越复杂。这些复杂结构也带来了新的问题,即模型的可解释性。
想创建稳定、不易受对抗样本攻击的模型,可解释性是很重要的。另外,为新的研究领域设计模型也是一项富有挑战的工作,如果能了解模型在做什么,可以对这一过程有所帮助。
过去几年,为了对模型的可解释性加以研究,研究者们提出了多种方法,包括:
LIME:通过局部线性近似值计算解释模型的预测
Activation Maximization:一种能了解那种输入模式可以生成最大的模型回应的方法
在低维解释空间中嵌入一个DNN图层
从认知心理学中借鉴方法
不确定性估计法——本文关注的重点
在我们开始研究如何用不确定性解决模型问题、解释模型之前,首先让我们了解一下为什么不确定性如此重要。
你为什么应该关注不确定性?
一个重要的例子就是高风险的应用,假设你正在创建一个模型,可以帮助医生判断病人的严重程度。在这种情况下,我们不应该仅仅关心模型的精确度,更要关注模型对其预测结果有多大程度的肯定。如果不确定性太高,医生需要谨慎决策。
自动驾驶汽车是另外一个有趣的例子。如果模型不确定是否有行人在马路上,我们可以利用这一信息让车子减速,或者发出警报让驾驶员手动操作。
不确定性还可以在缺乏数据样本的情况下帮助我们。如果模型不是在与样本相似的数据上训练的,它可能无法输出想要的结果。谷歌照片曾经将黑种人错误地认成了大猩猩,就是由于这个原因,种类单一的训练集可能导致令人尴尬的结果。
不确定性的最大用途,也是本文的主要目的,就是为模型排除错误。首先,让我们了解一下不确定性都有哪几种不同类型。
不确定性的种类
不确定性和模型都有多个种类,每一种都有不同的用处。
模型不确定性,又称认知不确定性(epistemic uncertainty):假设你有一个单一数据点,想知道哪种线性模型是最适合数据的。但是没有数据的话,我们根本无法判断,所以需要更多数据!
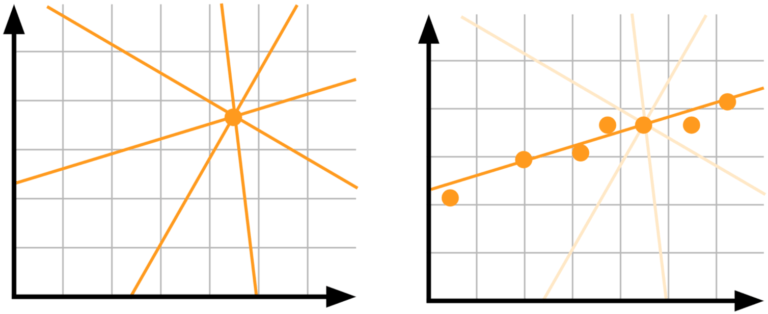
认知不确定性是由于模型的参数不确定。我们不知道模型的哪个权重能最好地表现数据,但是数据越多,不确定性越低。这种类型的不确定性在数据较少的高风险应用中很重要。

再比如,你想搭建一个模型,要在一系列动物图片中预测哪种动物会吃掉你。假设你在训练时给模型提供的都是狮子和长颈鹿的照片,现在模型看到了一张僵尸照片。由于之前它没有见过僵尸,所以这里的不确定性就非常高。如果在训练时能提供足够的僵尸照片,那么模型的不确定性会随之减少。
数据不确定性,也被称为“任意不确定性”:能够捕捉观察中的噪声。有时环境本身是随机的,收集更多数据并不会使不确定性降低,因为噪声来源于数据本身。
为了了解这一点,让我们回顾刚才的动物园模型。我们的模型能认出含有狮子的图像,它也许会判断你会被吃掉。但如果狮子此时此刻并不饿呢?这就是来源于数据的不确定性。另一个案例是两条看起来一模一样的蛇,一条有毒而另一条无毒。
数据不确定性可以分为两种类别:
同方差性不确定:对所有输入来说,不确定性都是相同的;
异方差性不确定:不确定性根据不同的输入有不同差别。例如,对于一个可以预测图像中物体深度的模型,一面墙就比一条渐渐消失的线不确定性要高。
测量不确定性:顾名思义,当测量方法充满噪音时,不确定性就会增加。在上述动物的案例中,如果某些图片拍摄的质量不好,就会损害模型的置信度。
噪声标签:在监督式学习下,我们用标签训练模型。如果标签太嘈杂,不确定性将会增加。
以上就是几种不确定性的类型,在这一系列的后续文章中,我们会详细解释。现在,让我们假设有一个黑箱模型,此时针对预测结果出现了不确定,我们应该如何用它为模型纠错呢?
这里我们以自己的模型为例,该模型是预测用户点击某个推荐内容的概率,我们称为CTR(Click Through Rate)。
利用不确定性进行debug
模型的嵌入向量表现出了很多分类特征,模型可能很难学习特殊值的泛化嵌入。一种常见的解决方法是用一种特殊的词汇表之外(OOV)的嵌入。
每篇推荐文章都有一个广告主(advertiser),所有珍贵的广告主都有同样的OOV嵌入,所以,从模型的角度,他们实际上是一个广告主。这个OOV广告主有很多不同的项目,每个都有不同的CTR。如果我们只有广告主作为CTR的预测器,那我们应该会得到OOV的高度不确定性。
为了验证模型的输出符合OOV的高度不确定性,我们用一个验证集,将所有广告主的嵌入转化为OOV。之后,我们开始观察转化前后,不确定性有什么变化。如此前预测的那样,不确定性在变化之后增加。模型应该能学习到,当给予了信息广告主,它应该减少不确定性。
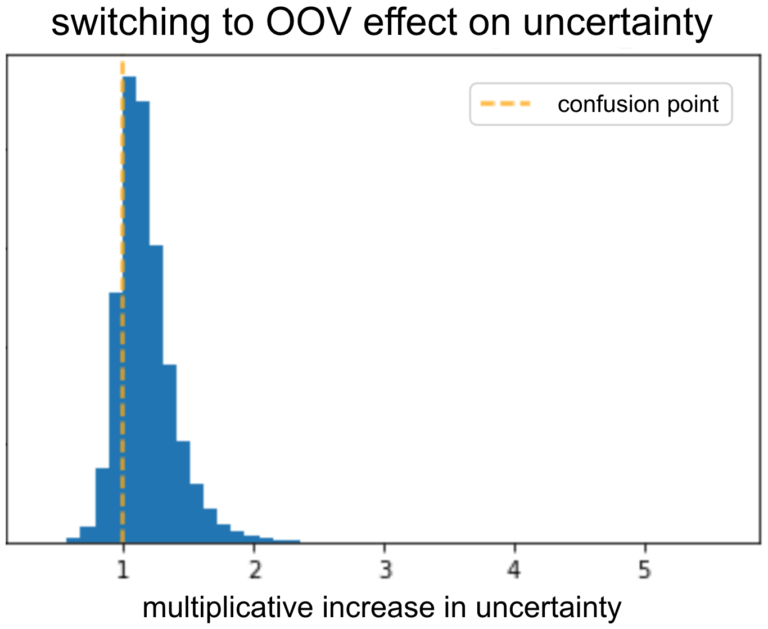
我们可以对不同特征重复这一过程,看它们的不确定性如何改变。
我们甚至可以做得更加精细:一些广告主在不同的项目之间的CTR不同,而其他的项目几乎有相同的CTR。我们希望模型能对前者有较高的不确定性。一种有效的分析是观察不确定性和CTR之间的相关性。如果呈负相关,那就意味着模型无法学习不确定性和每个广告主之间的关系。这一工具让我们了解了,如果在训练过程中或模型结构中有某一部分出了错,我们可以怎样解决它。
我们还可以进行相似的分析,看看如果不确定性与特殊项目连接,是否会减少更多。另外,我们希望模型对输出的结果更加确定,如果不确定,我们会尽力修复模型!
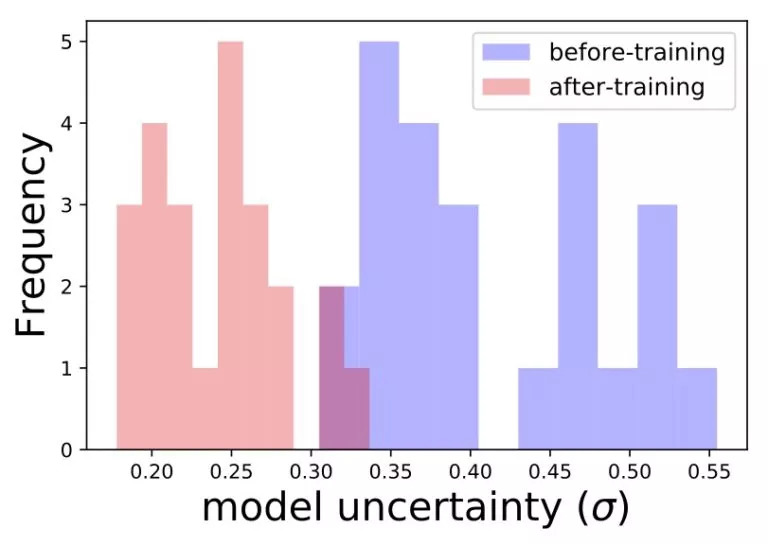
另一个例子是题目特征:含有不常见词语的标题通常具有高不确定性。这是由于模型不经常看到这类词语。我们可以在含有相似题目的验证集中对模型进行验证,估计模型对这些标题的不确定性是多少。然后重新用这些标题训练模型,看看不确定性是否会下降:
结语
在很多领域中,不确定性是很重要的问题,更重要的是根据不同应用确定不确定性的种类,然后据此解决模型的问题。这篇文章我们讨论了如何利用不确定性对模型进行debug,在下一篇文章中,我们会讲解如何用不同方法从模型中获得不确定性的估值。
原文地址:engineering.taboola.com/using-uncertainty-interpret-model/




