ICCV 2019 开幕,中国论文数量首超美国,以色列成奖项大赢家!

AI 科技评论在首尔!
作者 | 丛末、杨晓凡、Camel
编辑 | 唐里
10 月 27 日至 11 月 2 日,两年一届的 ICCV 2019 来到韩国首尔,选址 COEX 会展中心举行。严谨且严肃的国际顶级学术会议与充满着热情与活力的首尔将在这个枫叶开得正红的季节碰撞出怎样的火花呢?AI 科技评论在现场带大家一起看!
29 日,经过 2 天 Workshop 和 Tutorial 的前期预热和酝酿,ICCV 2019 开幕式在笼罩着一片温煦秋阳的清晨如期而至。


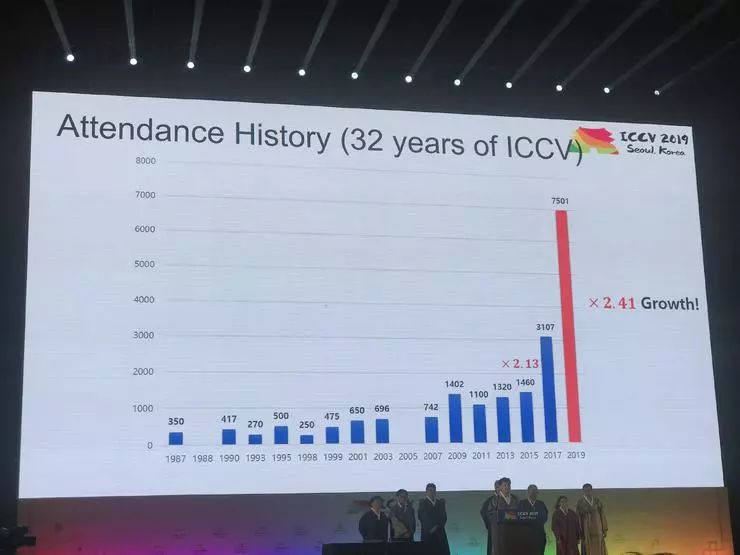

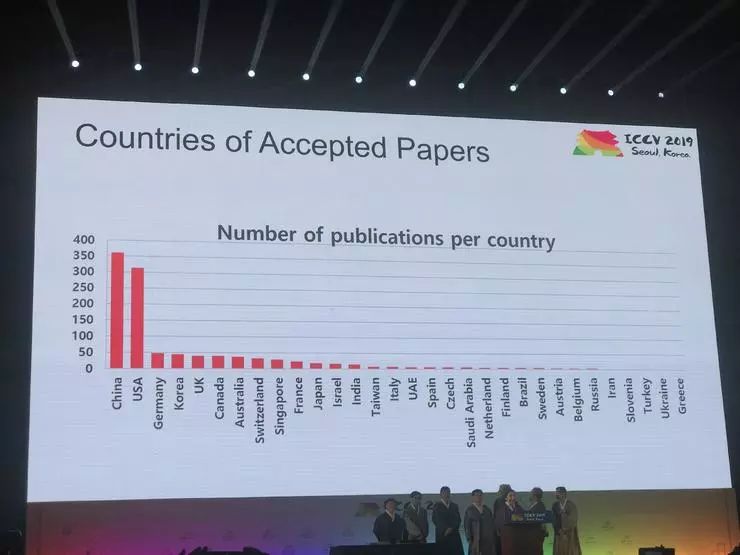
论文数据一览:中国论文数量超美国

从论文主题来看,最热门的关键词如图所示,排在前几位的依次是 Learning、Image、Network、Deep、3D、Object 等,这也反映了该领域内研究人员们对于各个细分课题的关注程度。

各奖项揭晓:以色列成奖项大赢家



2、最佳学生论文奖
最佳学生论文的第一作者 Timothy Duff 来自佐治亚理工学院。
![]()
论文地址:https://arxiv.org/abs/1903.10008

3、最佳论文荣誉提名奖
共有两篇论文被荣誉提名,如下:
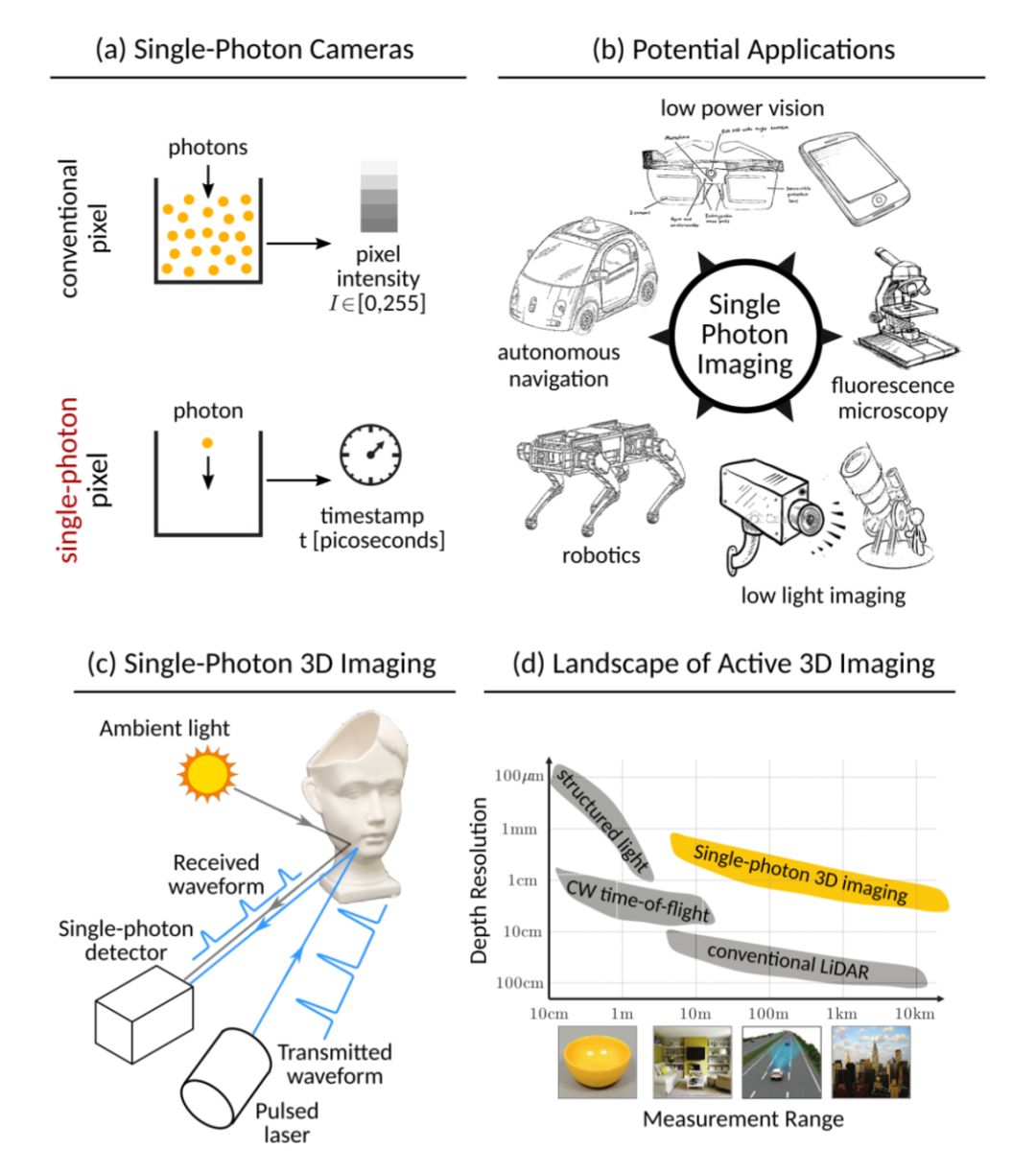
1)非同步单光子3D成像
这项工作来自于威斯康星大学麦迪逊分校,第一作者Anant Gupta。
![]()

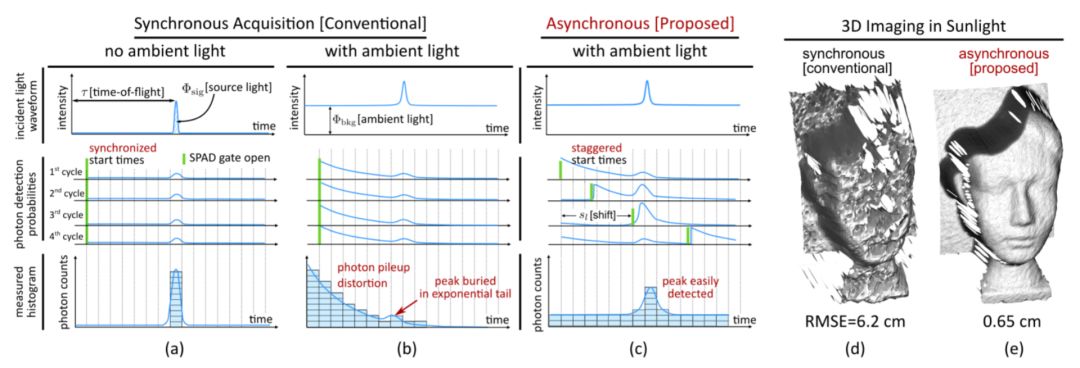
2)从交互性的场景生成中指定物体属性和关系
这项工作来自于
以色列特拉维夫大学
,第一作者Oron Ashual。
![]()
论文地址:https://arxiv.org/abs/1909.05379
作者提出了一种从场景图(scene graph)输入生成图像的方法。这个方法会分别生成一个布局嵌入和一个外观嵌入。


论文标题:Larger Norm More Transferable: An Adaptive Feature Norm Approach for Unsupervised Domain Adaptation
作者:Ruijia Xu, Guanbin Li, Jihan Yang, Liang Lin
单位:Sun Yat-sen University(中山大学)、DarkMatter AI Research
链接:https://arxiv.org/abs/1811.07456
论文标题:Deep Hough Voting for 3D Object Detection in Point Clouds
作者:Charles R. Qi, Or Litany, Kaiming He(何恺明), Leonidas J. Guibas
单位:Facebook AI Research,Stanford University
链接:https://arxiv.org/abs/1904.09664
论文标题:Unsupervised Deep Learning for Structured Shape Matching
作者:Jean-Michel Roufosse, Abhishek Sharma, Maks Ovsjanikov
单位:LIX, Ecole Polytechnique(巴黎综合理工大学)
链接:https://arxiv.org/abs/1812.03794
论文标题:Gated2Depth: Real-time Dense Lidar from Gated Images
作者:Tobias Gruber, Frank Julca-Aguilar, Mario Bijelic, Werner Ritter, Klaus Dietmayer, Felix Heide
单位:Daimler AG(戴姆勒), Algolux, Ulm University(德国乌尔姆大学), Princeton University
链接:https://arxiv.org/abs/1902.04997
论文标题:Local Aggregation for Unsupervised Learning of Visual Embeddings
作者:Chengxu Zhuang, Alex Lin Zhai, Daniel Yamins
单位:Stanford University
链接:https://arxiv.org/abs/1903.12355
论文标题:Habitat: A Platform for Embodied AI Research
作者:Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra
单位:Facebook AI Research, Facebook Reality Labs, Georgia Institute of Technology, Simon Fraser University, Intel Labs, UC Berkeley
链接:https://arxiv.org/abs/1904.01201
论文标题:Robust Change Captioning
作者:Dong Huk Park, Trevor Darrell, Anna Rohrbach
单位:University of California, Berkeley
链接:https://arxiv.org/abs/1901.02527
二、PAMI TC Awards
这几项重磅奖项揭晓后,PAMI 服务主席 Bryan Morse 上台颁布四大 PAMI TC 奖项,包括 Helmholtz 奖、Everingham 奖、Azriel Rosenfeld 终身成就奖以及杰出研究者奖。
1、Helmholtz Prize
1)Building Rome in a Day(华盛顿大学)


2、Everingham Prize


3、Azriel Rosenfeld 终身成就奖




AI 科技评论总结






