知识图谱推理的最新研究进展


文章作者:费斌杰 熵简科技 创始人兼CEO
内容来源:熵简科技
01
演绎推理与归纳推理
-
肯定前件论:如果今天是周末,那么我们不上班;今天是周六,所以推理得出我们不上班; -
否定后件论:如果今天是周末,那么我们不上班;今天我来上班了,所以推理得出今天不是周末; -
三段论:如果今天是周末,那么我们不上班;如果我们不上班,那么早上可以睡懒觉;所以推断出如果今天是周末,我们早上就可以睡懒觉; -
二难论:如果是周六,那么我打球;如果是周日,那么我看书;假设我不知道今天具体是周几,但是我知道今天肯定是周末,要么是周六要么是周日,那么可以推断出今天我要么打球要么看书; -
德摩根定律:p与q取否等价于非p或非q;p或q取否定等价于非p与非q;

图:常见演绎推理形式列举
与此相对,归纳推理是指基于已有的部分观察结果,从而推断出一般化结论的过程。归纳推理不能确保推理结果的完全准确,而演绎推理可以。
归纳推理有四种推理方向:
泛化归纳:把对个体的观察得出的结论推广到整体;
简单归纳:把对整体的统计结论应用于个体;
溯因归纳:根据观察的结果和现有知识来推断最有可能的原因;
类比归纳:根据对一个样本的观察来预测另一个相似样本的结果;
归纳推理的集大成者就是著名的贝叶斯推理,其核心思想是:不只通过观察最新一次的实验结果来定概率,而是把这作为一次证据 ( 似然概率 ),来修正历史的先验概率,从而得出一个新的后验概率,如此往复,不断逼近真实概率。
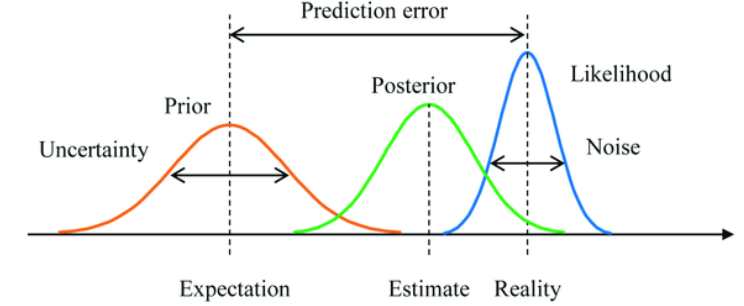
图:贝叶斯推理示意
常见的演绎推理方法有基于描述逻辑的推理、和基于逻辑编程的推理。常见的归纳推理方法有基于图结构的推理、基于规则学习的推理、基于表示学习的推理。下面我们分别展开讨论。
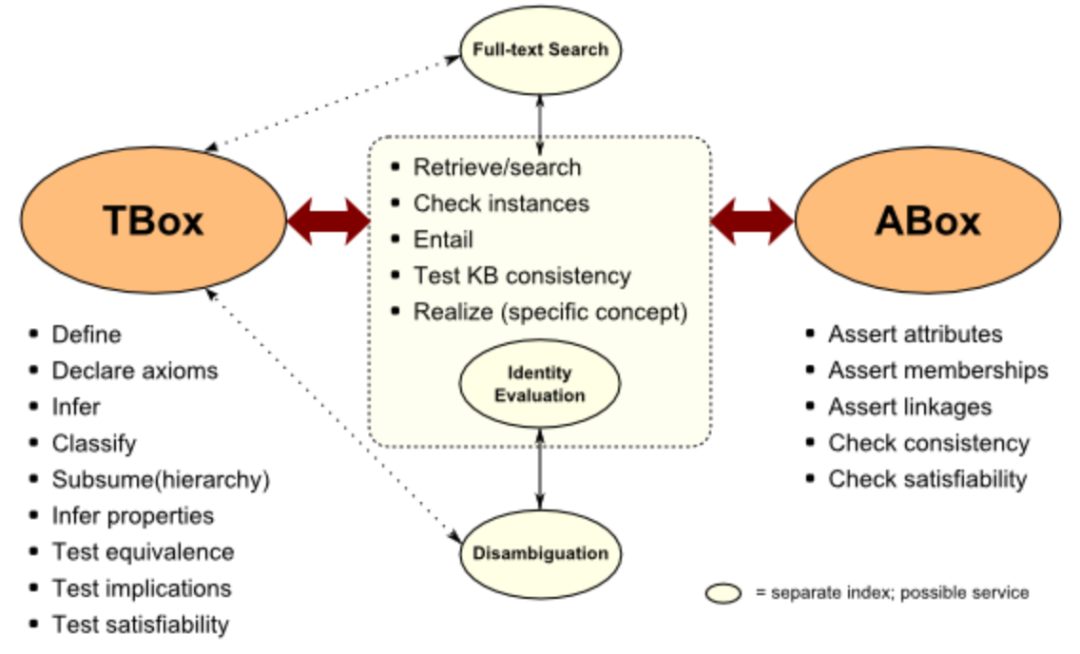
通过Tbox和Abox,我们可以把知识库中复杂的实体关系推理问题转化为一致性的校验问题,从而简化推理实现过程。
举个例子,“苹果 ∩ 绿色 = 酸涩”这属于概念断言,放在Tbox中;“我手里现在有10只苹果,其中3只是绿色的“,这属于实体断言,放在Abox中。基于Tbox和Abox,我们可以推理出我手中的苹果里有3只是酸涩的,7只是甘甜的,这属于推理系统。
基于描述逻辑的推理体系中,常见的是基于表运算 ( Tableaux ) 的推理,经常被用于检测描述逻辑知识库的一致性。
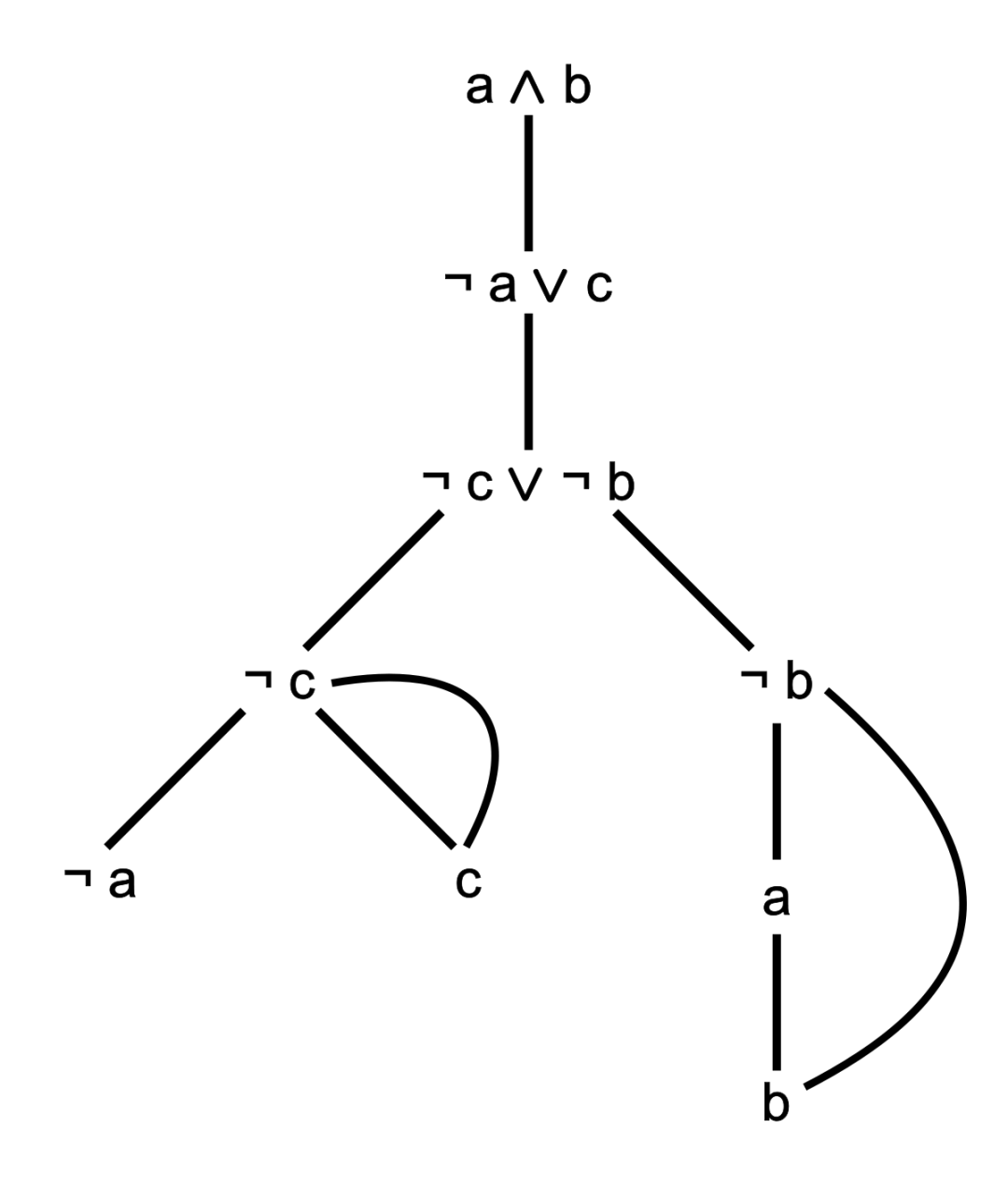
Tableaux算法的核心思想是如果我要证明一个推理是正确的,那我只要列出所有可能存在反例,并且一一驳斥就好了,即只要不存在反例那么推理就是正确的,所谓归结反驳。
Tableaux其实就是一棵公式树,它会根据前提 ( Premises ) 和否定结论 ( Negated Conclusion ) 来不断迭代创建新的分支,对公式进行逐级分解,当所有分支都关闭后,Tableaux算法就会被终止。
目前已经有不少公开的基于表计算的推理系统,如曼彻斯特大学研发的FaCT++、美国Franz公司研发的Racer、马里兰大学研发的Pellet、牛津大学研发的HermiT,其中HermiT实现了Hypertableaux的超表运算技术,进一步提高了Tableaux算法的运算效率。
基于图结构推理的典型算法是PRA ( Path Ranking Algorithm ),它利用了实体与实体之间的路径作为特征,从而对链接路径进行统计推理。
PRA算法的原理比较明了,假设一张图谱中有三类实体:员工实体、公司实体、行业实体。假设小明是熵简科技的员工,熵简科技是金融科技领域的公司,那么小明是金融科技领域的从业者。同时小红是启明星辰的员工,启明星辰是信息安全领域的公司,那么小红是信息安全领域的从业者。
通过统计可以发现,“供职于”、“是某某领域的公司”这两种关系组成的路径与“是某某领域的从业者”在图谱中经常出现,而且与员工实体、公司实体、行业实体具体是谁没有关系,因此能够得出一种重要的推理关系。
看似这是一个非常简单的直觉化的结论,但是常识恰恰是机器所不具备的能力。PRA算法能够通过对海量知识的学习,让机器从统计意义上掌握常识,从而进行有效的知识推理。
基于规则学习推理的代表算法是AMIE算法,其强调通过自动化的规则学习方法,快速有效的从大规模知识图谱中学习出置信度较高的规则,并且应用于推理任务。
这里的重点在于如何对机器学习出的规则进行有效性评估,有三类方法,分别是支持度评估、置信度评估、规则头覆盖度评估,这里以支持度为例进行说明。一个规则的支持度等于在整个知识图谱中满足规则主体和规则头的实例总个数。一个规则的支持度越高,说明在该知识图谱中存在很多符合这条规则的实例,因此从统计意义上来看,这更可能是一条准确的规则。
AMIE算法的全称是基于不完备知识库的关联规则挖掘算法 ( Association Rule Mining under Incomplete Evidence )。由于在大规模知识图谱中对所有可能的规则进行遍历及评估是不可行的方法,因此如何对空间进行有效的搜索成为了规则学习任务中的重中之重。
AMIE算法通过不断向规则中添加三类挖掘算子 ( Mining Operators ) 的方法来拓展规则主体部分,保留支持度高于阈值的候选闭式规则,这三类挖掘算子分别是悬挂边、实例边、闭合边。
悬挂边指的是边的一端是一个未出现过的变量、另一端是在规则中已出现过的变量或变量;
实例边指的是边的一端是规则中已经出现过的元素,另一端是一个实例化的实体;
闭合边指的是连接两个已经存在于规则中的元素,一旦完成闭合边的添加,规则的构建就算是完成了。
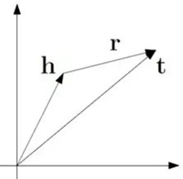
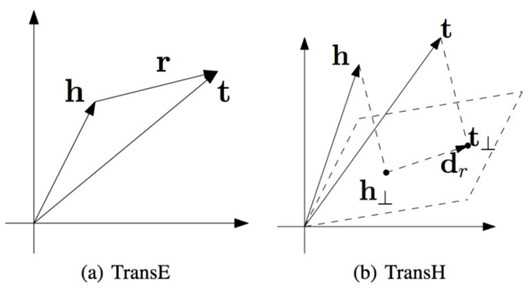
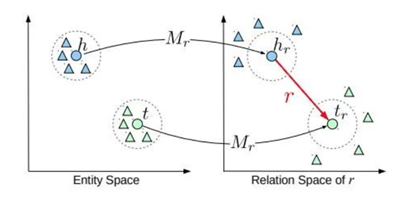
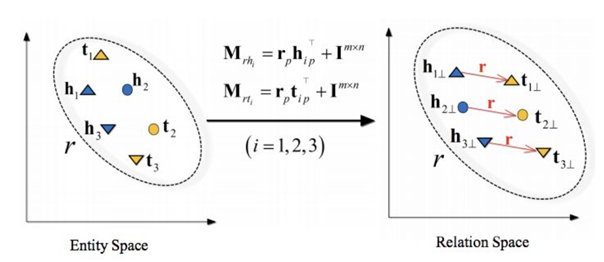
TransR有效增强了表示学习的表达能力,但它也有不足之处,其中最明显的问题在于TransR为每个关系引入了一个映射矩阵,使得其参数数量远大于TransE和TransH,因此难以应用于大规模知识图谱。
为解决这个问题,人们进一步提出了TransD算法。TransD的核心思想在于用一个实体相关的向量与一个关系相关的向量的外积来动态的求解出映射矩阵。通过动态计算映射矩阵,TransD不仅可以显著降低参数数量,而且增强了全局捕捉能力。
反过来看,TransE模型是TransR模型中的一个特例,当关系和实体的向量表示维度相等,且所有投影向量都设置为0时,TransR就退化为TransE。
知识推理是一门古老的学科,从亚里士多德在《前分析篇》中阐述的经典三段论开始 ( 亚里士多德是人;人都会死;所以亚里士多德会死 ),人们就对知识推理进行了理论探索与实践。
随着近年来技术的飞速发展,越来越多的知识图谱自动化构建方法被学界和业界提了出来,比如通过算法对海量文本进行三元组提取,使得大规模知识图谱的构建成为了可能。但这类知识图谱的信息准确度和冗余度都稍逊于通过专家知识进行人工搭建的知识图谱。
在这种自动化构建的大规模知识图谱上进行知识推理时,知识的不精确性以及巨大的数据规模对于演绎推理来说是巨大的挑战,而归纳推理则可以发挥更大的价值。
近年来,知识图谱领域学术界和产业界的互动越发紧密,随着开源工具Jena、JBoss的推出与普及,知识图谱推理将对现代企业知识图谱应用起到愈发重要的作用。
作者信息:
费斌杰,熵简科技创始人兼CEO,长期深耕金融资管数据科技一线,对数据中台、知识图谱的技术实践和产业应用有深入理解,曾就职于嘉实基金,毕业于清华大学五道口金融学院、清华大学工业工程系。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
社群推荐:

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个3连击呗!👇


