基于小样本学习的意图识别冷启动
作者丨黎槟华、耿瑞莹、李永彬、孙健
单位丨阿里巴巴智能服务事业部小蜜北京团队
本文授权转载自公众号:PaperWeekly
这是一个推荐、解读、讨论和报道人工智能前沿论文成果的学术平台,致力于让国内外优秀科研工作得到更为广泛的传播和认可。
随着深度学习和自然语言处理技术的发展,很多公司都在致力于发展人机对话系统,希望人和机器之间能够通过自然语言进行交互。笔者所在的阿里巴巴小蜜北京团队打造了一个智能对话开发平台——Dialog Studio,以赋能第三方开发者来开发各自业务场景中的任务型对话,而其中一个重要功能就是对意图进行分类。
大量平台用户在创建一个新对话任务时,并没有大量标注数据,每个意图往往只有几个或十几个样本,那如何使用现有的少量样本构建意图分类模型呢?面对这类冷启动问题,我们提出使用小样本学习(few-shot learning)来解决对话平台中的意图识别冷启动问题。

关于 few-shot learning 的系统知识和最新进展情况,请参考我们之前的综述,本文主要详细介绍我们的工作:首先总结前人工作提出了 Encoder-Induction-Relation 的 Few-shot Learning Framework,然后融合 capsule network 和 dynamic routing,提出了 Induction Network,在两个小样本文本分类数据集上,都做到了 state-of-the-art。
问题定义
人类非常擅长通过极少量的样本识别一类物体,比如小孩子只需要书中的一些图片就可以认识什么是“斑马”,什么是“犀牛”。在这种人类的快速学习能力的启发下,我们希望模型在大量类别中学会通过少量数据正确地分类后,对于新的类别,我们也只需要少量的样本就能快速学习,这就是 Few-shot learning 要解决的问题。
Few-shot learning 是 meta learning 在监督学习领域的一种应用场景,我们 training 阶段将数据集按类别分解为不同的 meta-task,去学习类别变化的情况下模型的泛化能力,在 testing 阶段,面对全新的类别以及每个类别仅有少量数据,不需要变动已有的模型,就可以完成分类。
形式化来说,few-shot 的训练集中包含了大量的类别,每个类别中有少量样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 C×K 个数据)构建一个 meta-task,作为模型的支撑集(Support set)输入;再从这 C 个类中抽取一批样本作为模型的预测对象(Query set 或者 Batch set)。即要求模型从 C×K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。
训练过程中,每轮(episode)都会采样得到不同 meta-task 的,即包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如,如何提取重要特征及比较样本相似等,忘掉 meta-task 中领域相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。详情见 Algorithm 1。

Few-shot Learning框架
Few shot learning 中较为热门的方法大多是 metric-based,即通过类别中少量样本计算得到该类别的表示,然后再用某种 metric 方法计算得到最终的分类结果。下面简单的介绍现有的相关方法。
如图 1 所示,孪生网络(Siamese Network)[1] 通过有监督的方式训练孪生网络来学习,然后重用网络所提取的特征进行 one/few-shot 学习。具体的网络是一个双路的神经网络,训练时,通过组合的方式构造不同的成对样本,输入网络进行训练,在最上层通过样本对的距离判断他们是否属于同一个类,并产生对应的概率分布。在预测阶段,孪生网络处理测试样本和支撑集之间每一个样本对,最终预测结果为支撑集上概率最高的类别。
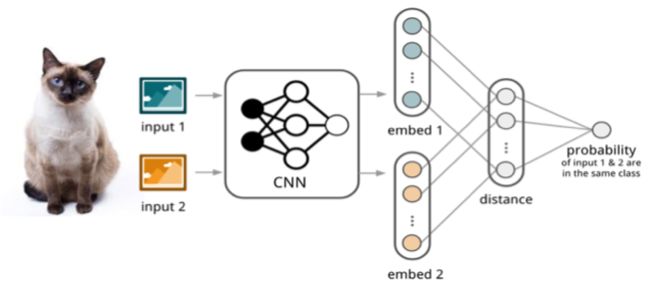
▲ 图1. Siamese Network
相比孪生网络,匹配网络(Match Network)[2] 如图 2 所示,它为 Support 集和 Batch 集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。该网络在不改变模型的前提下能对未知类别生成标签,同时提出了基于 memory 和 attention 的 matching nets,使得可以快速学习。
此外该文章还使整个任务遵循传统机器学习的一个原则,即训练和测试是要在同样条件下进行的,提出在训练的时候不断地让网络只看每一类的少量样本,这使得训练和测试的过程是一致的。这一点也使得后续文章都会基于这样的方式进行训练和测试。
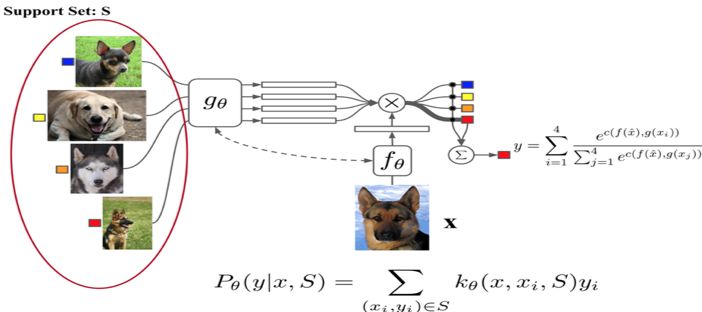
▲ 图2. Match Network
原型网络(Prototype Network)[3] 基于这样的想法:每个类别都存在一个原型表达,该类的原型是 support set 在 embedding 空间中的均值。然后,分类问题变成在 embedding 空间中的最近邻。
如图 3 所示,c1、c2、c3 分别是三个类别的均值中心(称 Prototype),将测试样本 x 进行 embedding 后,与这 3 个中心进行距离计算,从而获得 x 的类别。
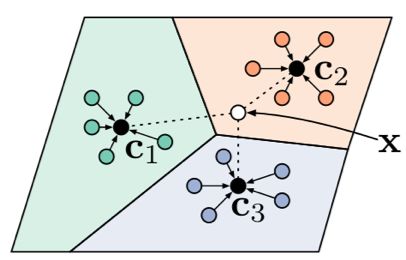
▲ 图3. Prototype Network
文章采用在 Bregman 散度下的指数族分布的混合密度估计,文章在训练时采用相对测试时更多的类别数,即训练时每个 episodes 采用 20 个类(20 way),而测试对在 5 个类(5 way)中进行,其效果相对训练时也采用 5 way 的提升了 2.5 个百分点。
前面介绍的几个网络结构在最终的距离度量上都使用了固定的度量方式,如 cosine,欧式距离等,这种模型结构下所有的学习过程都发生在样本的 embedding 阶段。
而 Relation Network [4] 认为度量方式也是网络中非常重要的一环,需要对其进行建模,所以该网络不满足单一且固定的距离度量方式,而是训练一个网络来学习(例如 CNN)距离的度量方式,在 loss 方面也有所改变,考虑到 relation network 更多的关注 relation score,更像一种回归,而非 0/1 分类,所以使用了 MSE 取代了 cross-entropy。
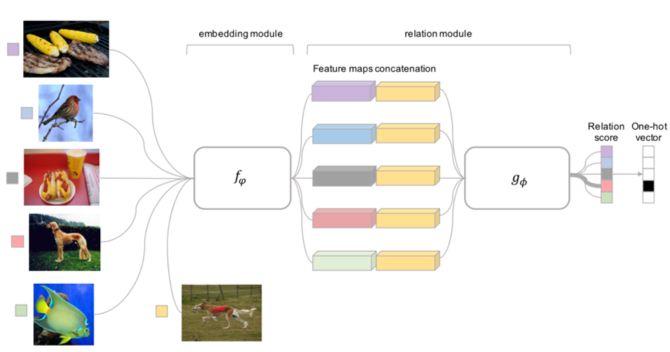
▲ 图4. Relation Networks
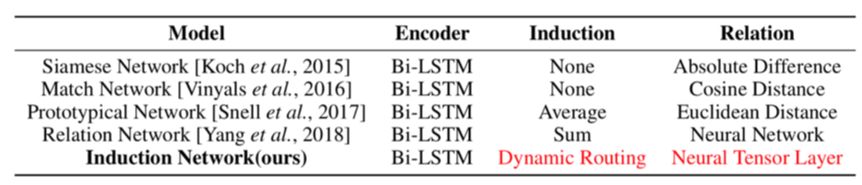
回顾上述方法,从表 1 中可以看出,现有的方法在表示新的类别时只是通过简单对样本向量加和(Relation Net)或求平均(Prototype Net),在这种情况下,由于自然语言的多样性,同一个类的不同表述只有一部分是和类别的内容相关,其他部分则随每个人的语言习惯而产生较大的变化,所以很多关键信息都会丢失在同一个类的不同表述产生的噪音之中。
比如,在运营商领域,同样是表述“换套餐”的意图,既可以说的简单明了:“我想换套餐”,也可以说的十分繁琐:“我想下个月换套餐,就是把原本不需要的套餐取消掉,换个便宜的…”。
如果只是对不同话术简单加和,那么和分类无关的信息就会产生累积,进而影响分类的效果。
▲ 表1. Metric Based方法对比
与大量样本的监督学习不同,噪音问题会在 few shot learning 中变得更为明显,因为在监督学习的大量样本下,某个类别的数据中关键信息和噪音的比例悬殊,模型容易区别哪些是噪声(例如:词或 n-gram),哪些是有效信息(例如:业务关键词或句式),相反 few shot learning 仅有少量样本,很难用简单的机制来捕获这样的信息,因此显式建模类别表示的步骤是非常有意义的,具体的实现细节在下文会详细描述。
所以更好的学习方法应该是建模归纳类别特征的能力:忽略掉和业务无关的细节,从样本级别多种多样的表达之中总结出类别的语义表示。因此,我们需要站在一个更高的视角,去重构支撑集中不同样本的层次化语义表示,动态的从样本信息中归纳出类别特征。
在本工作中,我们提出了 Induction Network,通过将动态路由算法与 meta learning 机制结合,显式建模了从少量样本中归纳出类别表示的能力。
首先,我们团队总结了 metric-based 方法的的共性,提出了 Encoder-Induction-Relation 的三级框架 [5],如图 5 所示,Encoder 模块用于获取每个样本的语义表示,可以使用典型的 CNN、LSTM、Transformer 等结构,Induction 模块用于从支撑集的样本语义中归纳出类别特征,Relation 模块用于度量 query 和类别之间的语义关系,进而完成分类。
如表 1 所示,之前的工作往往致力于学习不同的距离度量方式,而忽视了对样本表示到类别表示的建模。而在自然语言当中,由于每个人的语言习惯不同,同一个类别的不同表述往往有很多种,如果仅仅是简单加和或取平均来作为类别的表示,这些与分类无关的干扰信息就会累加,影响最终的效果,因此我们的工作显式的建模了从样本表示到类别表示这一能力。
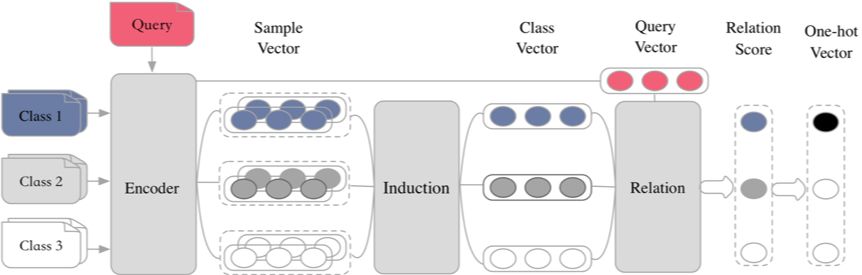
▲ 图5. Encoder-Induction-Relation三级框架
模型
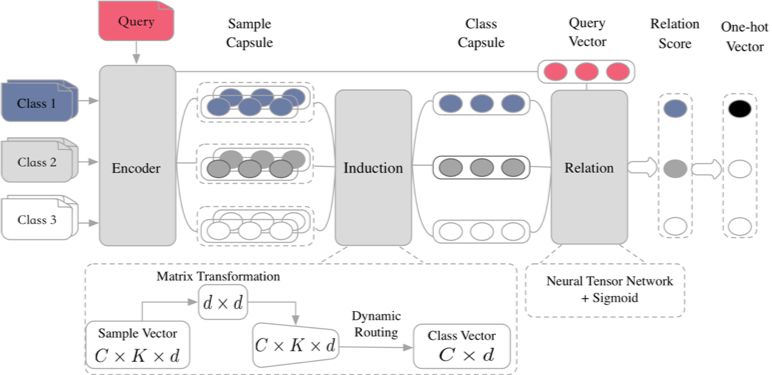
如图 6 所示,我们的模型基于 Encoder-Induction-Relation 的三级框架,其中 Encoder 模块使用基于自注意力的 Bi-LSTM,Induction 模块使用动态路由算法,Relation 模块使用神经张量网络。
Encoder模块
本工作共使用 bi-lstm self-attention 建模句子级别的语义,输入句子的词向量矩阵,经编码得到句子级的语义表示 e。
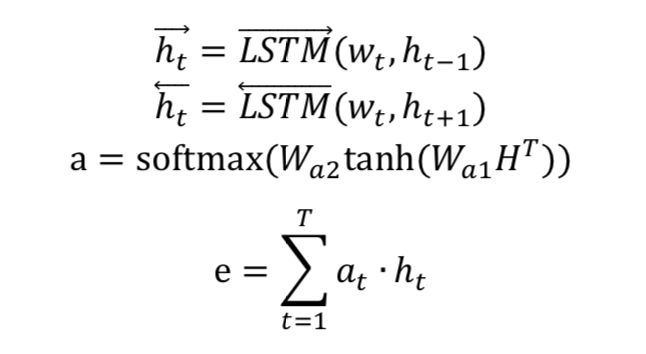
Induction模块
将支撑集中每个样本编码为样本向量以后,Induction 模块将其归纳为类向量。
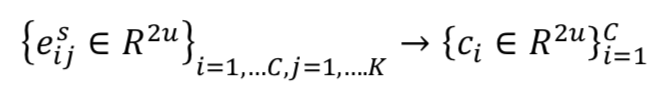
这一过程中我们将支撑集中的样本向量视为输入胶囊,经过一层 dynamic routing 变换后,输出胶囊视为每个类的语义特征表示。
首先,是对所有样本做一次矩阵转换,意味着将样本级的语义空间转换到类别级的语义空间,在此过程中我们对支撑集中所有的样本向量使用同一个转换矩阵,如此对于任意规模的支撑集都能进行处理,也就意味着我们的模型可以应对 any-way any-shot 的场景。
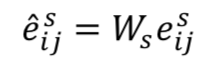
然后,通过 dynamic routing 的方式过滤无关信息,提取类别特征。在每次 dynamic routing 的迭代中,我们动态的调整上下两层之间的连接系数并确保其加和为 1:
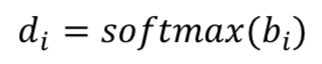
其中 bi 连接系数的逻辑值,在第一次迭代时初始化为 0。对于给定的样本预测向量,每个候选类向量是的加权求和:
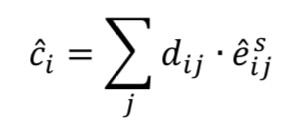
然后使用一个非线性的 squash 函数来保证每个类向量的模长不超过 1:
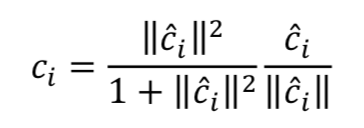
每次迭代的最后一步是通过“routing by agreement”的方式来调节连接强度,如果产生的类候选向量和某样本预测向量之间有较大的点乘结果,则增大他们之间的连接强度,否则减小之。
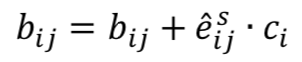
通过这种动态路由的方式建模样本向量到类别向量的映射过程,能够有效过滤与分类无关的干扰信息,得到类别特征,详情见 Algorithm 2。

Relation模块
我们通过 Induction 模块得到支撑集中每个类别的类向量表示,通过 Encoder 模块得到 Batch set 中每个 query 的向量,接下来要做到就是衡量二者之间的相关性。 Relation 模块是典型的 neural tensor layer,首先通过三维 tensor 建模每个类向量和 query 向量对之间的交互关系,然后使用全连接层得到关系打分。
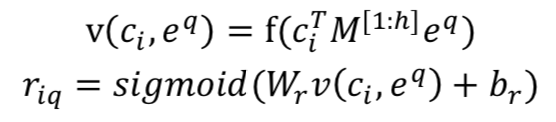
目标函数
我们使用最小平方损失来训练我们的模型,将关系打分回归至真实标签:匹配的类和 query 对之间的打分趋向于 1 而不匹配的打分趋向于 0。在每个 episode 中,给定支撑集 S 和 Query 集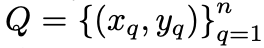
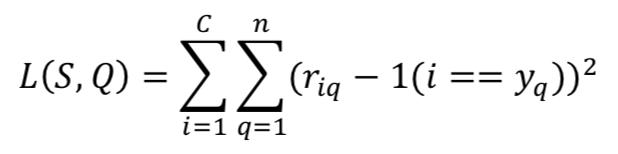
我们使用梯度下降法更新 Encoder、Induction 和 Relation 三个模块的参数。训练完成之后,我们的模型在识别全新的类别时不需要任何 finetune,因为在 meta 训练阶段已经赋予了模型足够的泛化能力,而且会随着模型的迭代不断累加。
实验
我们在两个 few-shot 文本分类的数据集上验证模型的效果,所有的实验使用 tensorflow 实现。
数据集
1. ARSC 数据集由 Yu 等人 [6] 在 NAACL 2018 提出,取自亚马逊多领域情感分类数据,该数据集包含 23 种亚马逊商品的评论数据,对于每一种商品,构建三个二分类任务,将其评论按分数分为 5、4、 2 三档,每一档视为一个二分类任务,则产生 23*3=69 个 task,然后取其中 12 个 task(4*3)作为测试集,其余 57 个 task 作为训练集。
2. ODIC 数据集来自阿里巴巴对话工厂平台的线上日志,用户会向平台提交多种不同的对话任务,和多种不同的意图,但是每种意图只有极少数的标注数据,这形成了一个典型的 few-shot learning 任务,该数据集包含 216 个意图,其中 159 个用于训练,57 个用于测试。
参数设置
预训练词向量使用 300 维 glove 词向量,LSTM 隐层维度设为 128,dynamic routing 的迭代器爱次数设为 3,Relation 模块的张量数 h=100。我们在 ARSC 数据集上构建 2-way 5-shot 的模型,在 ODIC 数据集上 C 和 K 在 [5,10] 中选取得到四组实验。
在每个 episode 中,除了为支撑集选取 K 个样本以外,我们还为采到的每个类再采 20 个样本作为 query set,也就是说在 5-way 5-shot 场景下每次迭代训练都会有 5*5+5*20=125 个样本参与训练。
实验结果
在 ARSC 和 ODIC 数据集上实验结果如表 2 和表 3 所示。

▲ 表2. ARSC数据集实验结果
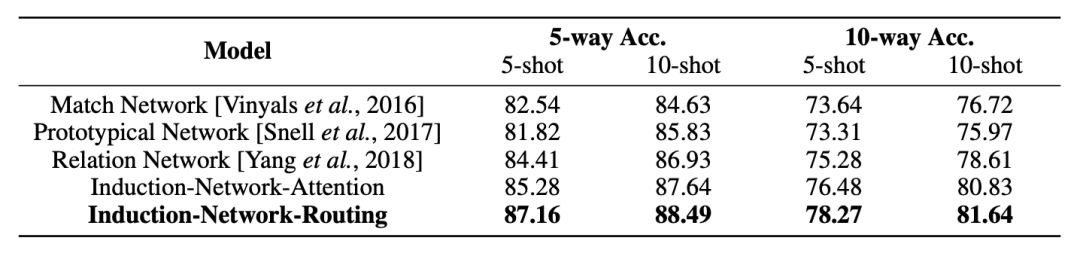
▲ 表3. ODIC数据集实验结果
如表 1 所示,我们将基于 metric 的方法都纳入 Encoder-Induction-Relation 框架中,可以发现之前的工作往往致力于学习不同的距离度量方式,而忽视了对样本表示到类别表示的建模。
而在自然语言当中,由于每个人的语言习惯不同,同一个类别的不同表述往往有很多种,如果仅仅是简单加和或取平均来作为类别的表示,这些与分类无关的干扰信息就会累加,影响最终的效果,因此我们的工作显式的建模了将样本表示归纳为类别表示的能力,并超过了之前的 state-of-the-art 的模型。
实验分析
我们进一步分析转置矩阵的影响和模型对 encoder 模块的影响。
转置矩阵的作用
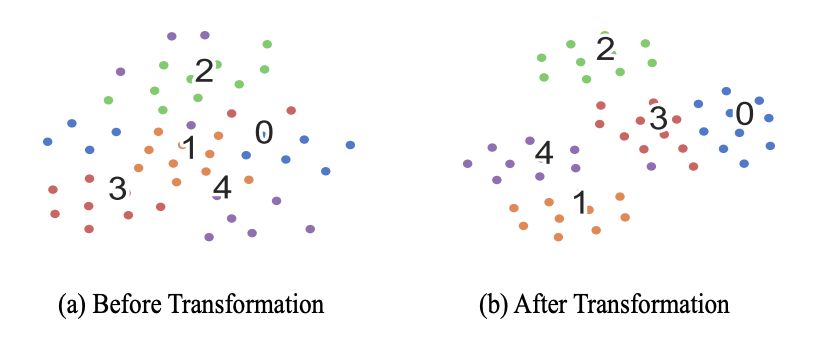
在 5-way 10-shot 场景下,我们用 t-sne 降维并可视化经过 transformation 转置矩阵前后支撑集样本的变化,如图所示,可以发现经过转置矩阵之后的支撑集样本向量可分性明显变好。这也证明了矩阵转置过程对于转换样本特征到类别特征的有效性。
Query可视化
我们发现 Induction Network 不仅能够生成质量更高的类向量,而且可以帮助 encoder 模块学习更好的样本语义表示。通过随机抽取 5 个测试集的类别,并将其中所有样本 Encoder 之后的向量可视化,我们发现 Induction Network 中学到的样本向量可分性明显高于 Relation Network,这说明我们的 Induction 模块和 Relation 模块通过反向传播给了 Encoder 模块更为有效的信息,使其学到了更易于分类的样本表示。

结论
在本工作中,我们提出了 Induction Network 来解决少样本文本分类的问题。我们的模型重构支撑集样本的层次化语义表示,动态归纳出类别的特征表示。我们将动态路由算法和 meta learning 的框架结合,模拟了类人的归纳能力。实验结果表明我们的模型在不同的少样本分类数据集上都超过了当前的 state-of-the-art 模型。
参考文献
[1] Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. "Siamese neural networks for one-shot image recognition." ICML Deep Learning Workshop. Vol. 2. 2015.
[2] Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638, 2016.
[3] Snell, Jake, Kevin Swersky, and Richard Zemel. "Prototypical networks for few-shot learning." Advances in Neural Information Processing Systems. 2017.
[4] Sung, Flood, et al. "Learning to compare: Relation network for few-shot learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[5] Geng R, Li B, Li Y, et al. Few-Shot Text Classification with Induction Network[J]. arXiv preprint arXiv:1902.10482, 2019.
[6] Yu, Mo, et al. "Diverse few-shot text classification with multiple metrics." arXiv preprint arXiv:1805.07513


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流


