【AAAI2021】LRC-BERT:对比学习潜在语义知识蒸馏
高德智能技术中心研发团队在工作中设计了对比学习框架进行知识蒸馏,并在此基础上提出COS-NCE LOSS,该论文已被AI顶会AAAI2021接收。

而NLP领域近期最重要的进展当属预训练模型,Google发布的BERT预训练语言模型一经推出就霸占了NLP各大榜单,提升了诸多 NLP 任务的性能,在11种不同NLP测试中创出最佳成绩,预训练模型成为自然语言理解主要趋势之一。
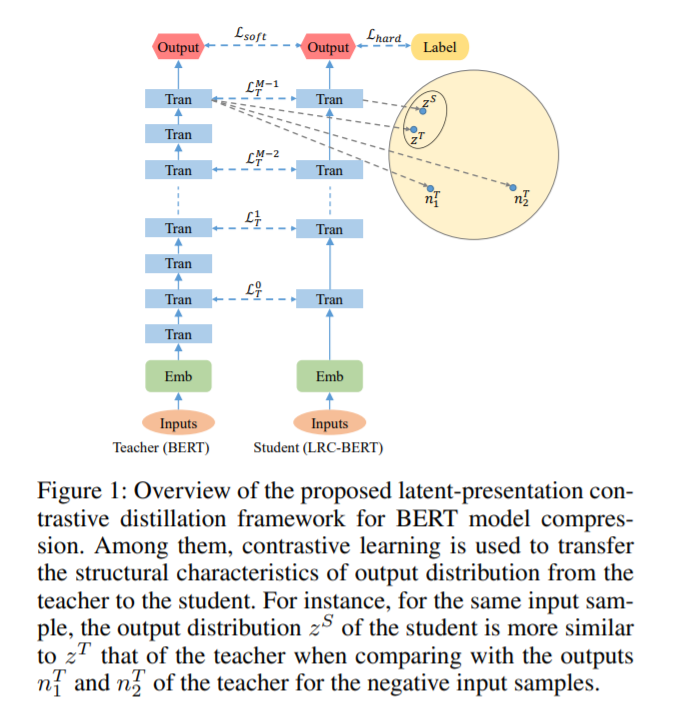
提出了对比学习框架进行知识蒸馏,在此基础上提出COS-NCE LOSS可以有效的捕捉潜在语义信息。
梯度扰动技术首次引入到知识蒸馏中,在实验中验证其能够提升模型的鲁棒性。
提出使用两阶段模型训练方法更加高效的提取中间层潜在语义信息。
本文在General Language Understanding Evaluation (GLUE)评测集合取得了蒸馏模型的SOTA效果。
https://www.zhuanzhi.ai/paper/9f999c711b0341b5df16076ce71f02ac
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LRC” 可以获取《【AAAI2021】LRC-BERT:对比学习潜在语义知识蒸馏》专知下载链接索引



登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
5+阅读 · 2019年5月20日




相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年5月20日