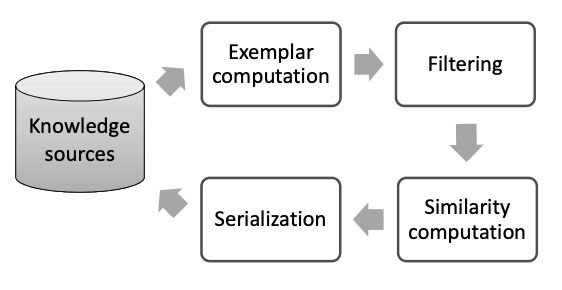
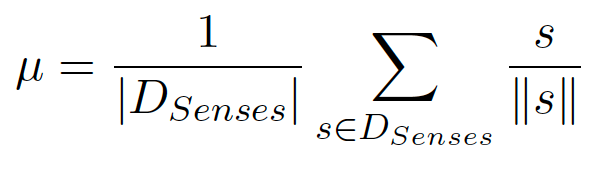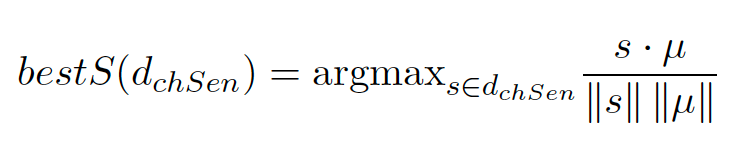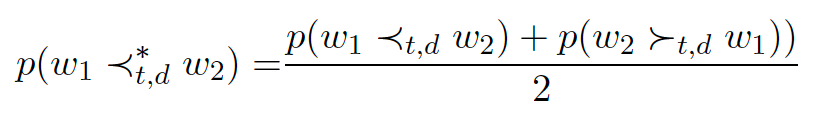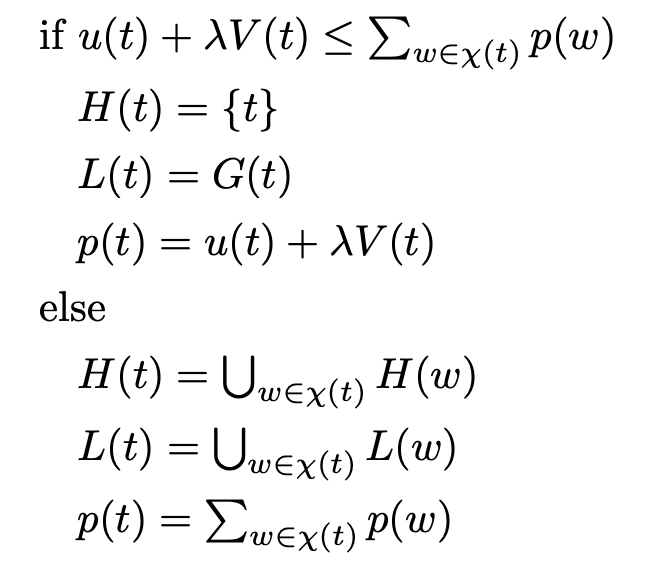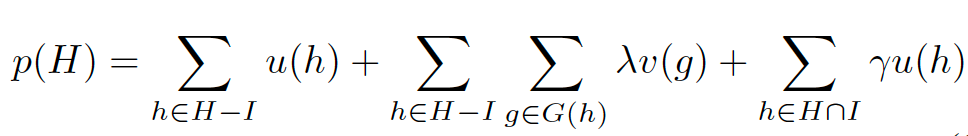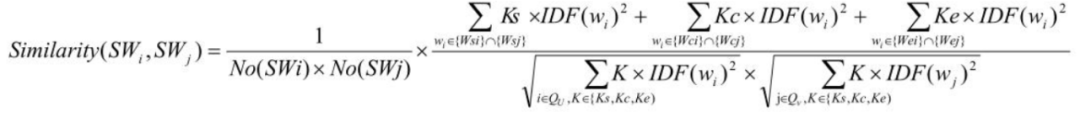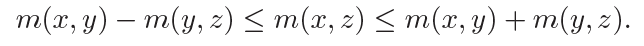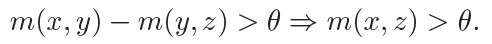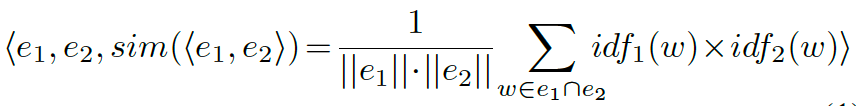前言
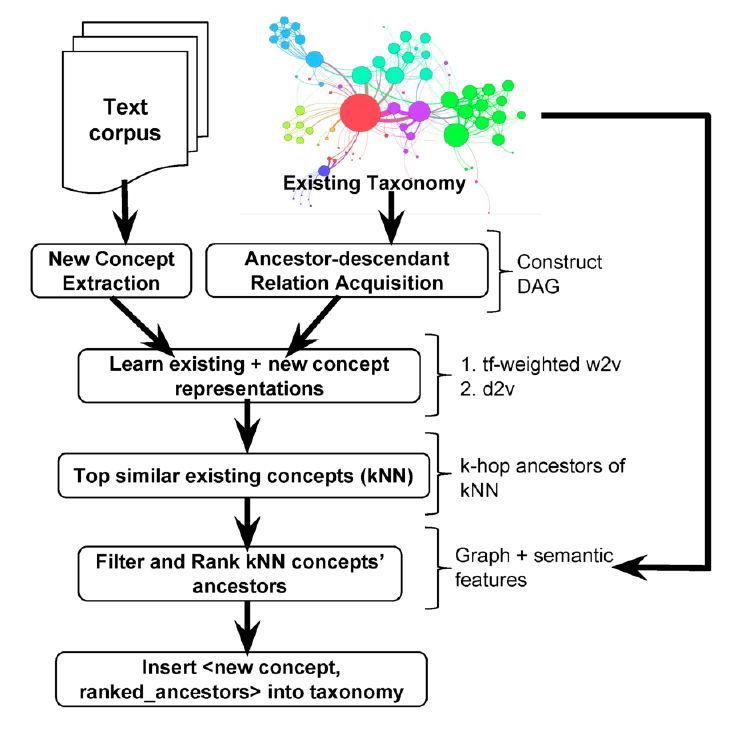
在过去一年的文章中,我们讨论了很多关于知识图谱构建、结合NLP应用的方法。逐渐,这些算法开始深入到许多业务中的搜索、推荐工作中。很自然的做法是,为了契合各个业务的实际场景,我们会为每个业务方独立出各自的知识图谱,方便与业务方共同管理数据。随着业务深入,很快会发现单个业务知识图谱因为规模小,在文本语义理解类任务上非常受限,此时需要将多个知识图谱进行融合,打通知识边界。比如在丁香园的场景中,有问诊、求职、电商、资讯、论坛等业务,背后使用同一套专业医学知识,而各自业务线又有丰富的职位、商品、科研等数据,另外可以在 OpenKG 找到其他领域或常识类图谱。融合之后不仅对相关NLP任务效果带来不小的提升,为后续实现不同业务之间的导流和推荐也提供了想象力。
那么,两个(或多个)知识图谱的融合是怎么实现的呢?所谓融合,可以理解存在以下三种操作:1)实体词在新的上下级位置上进行插入;2)不同图谱中的同义实体词完成合并;3)三元组关系随着实体词位置变化而动态调整
单看这些任务,类似的技术我们在《知识图谱构建技术综述与实践》、《抽取获得的知识图谱三元组该如何质检?》和《如何扩充知识图谱中的同义词》均有部分提及。本文我们来系统地看一下在不同阶段,图谱融合该采取什么策略,以及相关的算法论文调研。
一.小规模知识图谱如何进行图谱融合
业务图谱建立初期,图谱规模较小,基于知识表示的图谱融合方法壁垒比较多,基本以人工为主力,那么怎么才能尽可能的减少人工成本呢?
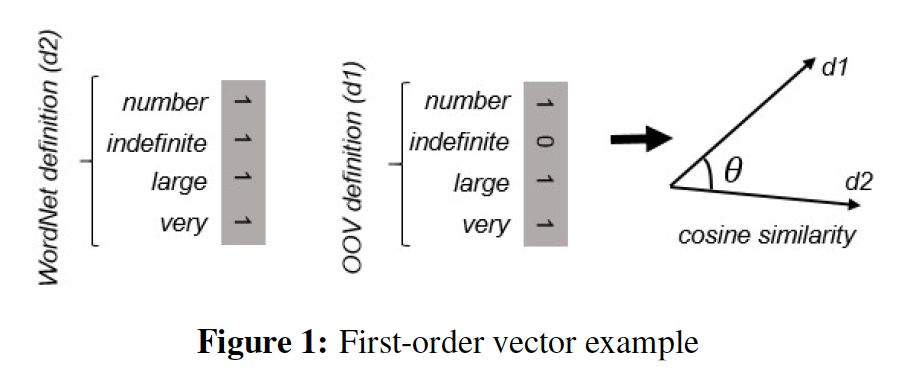
图谱融合的最早做法是利用First-Word-First-Sense,在WordNet中找到OOV的适当位置。First-Word-First-Sense策略就是将新的概念链接到其定义中的第一个与其词性相同,并源于WordNet中的同一gloss(术语词汇表)分组的词。这种方法在英文数据中适用性比较强,并且能得到比下面介绍的三种方法更好的效果,但这却取决于我们的图谱和WordNet的组织方式是否相同,即每个词语都有一个义原,并有明确的词性,每个概念标注了基于义原的定义以及词性、情感倾向、例句。实际上并不是所有的图谱都严格遵循语言学结构,因此对于领域图谱First-Word-First-Sense方法并不适用。
《VCU at Semeval-2016 Task 14: Evaluating similarity measures for semantic taxonomy enrichment》
VCU系统设计了三种无监督融合方式。首先,通过词性或实体类型进行候选集确定。其次,给每个候选集实体赋予一个分数,分数通过基于字典的相似性度量得到(分别使用Lesk,一阶向量,二阶向量三种方法进行分数计算)。最后,将得分最高的候选集分配给OOV;如果得分大于特定阈值,则标记为merge(这两个词是同义的),否则标记为attach,即OOV是synset的下位词。
Lesk度量通过计算两个定义之间出现的一个或多个连续单词的最长序列,来量化两个术语之间的相关性,最终权重为序列长度的平方,目的是较长重叠赋予更大的权重。
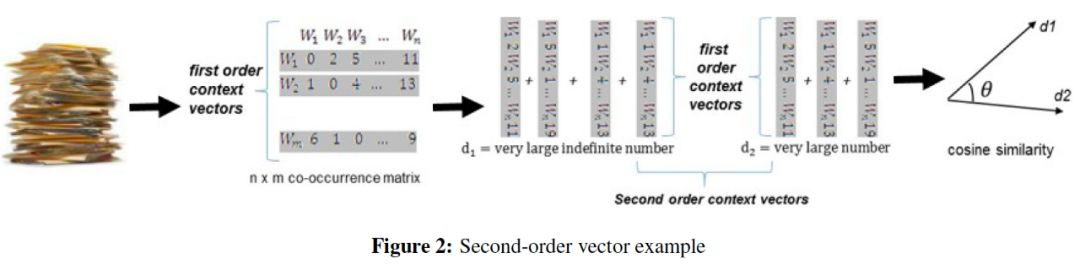
一阶向量由候选集与新实体定义中关联单词出现的次数构成,利用余弦相似性来量化相似程度。但缺点是向量矩阵过于稀疏。因此在二阶向量度量中,为定义中的每个单词创建一个向量,其中包含其在外部语料库中共现的单词,将词向量平均值作为新实体和候选集的二阶向量。
![]()
![]()
VCU系统算是比较Naive,但有效的方法,尤其是对一些字面上和定义中具有上下级暗示的实体对,如:糖尿病,1型糖尿病。利用简单的语义相似性度量,分数高的实体对质量也比较好。但不足也较明显,首先在于阈值的设定,低于阈值即为下位词,这将造成一些分数极低的噪音插入图谱;其次在于定义中的多义实体的出现和特定的词汇;最后,VCU系统其实并没有充分的利用已有图谱的结构。
《TALN at SemEval-2016 Task 14: Semantic Taxonomy Enrichment Via Sense-Based Embeddings》
TALN系统与VCU的输入相同,均为新实体、词性及其相关定义。
VCU系统在新实体定义的使用上存在以下问题:新实体的定义可能没有明确提到其最接近WordNet候选集,为解决这一问题,TALN在向量上采用了基于BabelNet的SENSEMBED模型,即更多地考虑句法,词性,短语。首先对每个定义进行词性标注和句法分析,生成一组名词和动词短语,然后利用词和短语对定义进行向量空间表示。最后对候选词排序,获取最终结果。
在父级候选部分,TALN通过深度优先遍历WordNet,直到与新实体词性相同的词根为止,获取新实体定义的语义解析树中的词根集,作为父级候选。设计了三种扩充父级候选方式:
(2)以定义中的centroid sense进行扩充
![]()
(1)确定定义的centroid sense之后,找到定义中哪个chunk最接近centroid sense,以此扩充。
![]()
《MSejrKu at SemEval-2016 Task 14: Taxonomy Enrichment by Evidence Ranking》
TALN虽在词法,句法分析上进行了大量的改进,但仍没有考虑实体消歧问题,并且依然采用简单的相似度排序做法。MSejrKu系统尝试了两种算法,其一是使用Mate解析器对描述语句进行词性和依赖性分析,获得词汇,句法特征和Skip-Gram embeddings,作为二分类器(线性logistic回归分类器和一个包含100个单位的单隐层非线性神经网络分类器)特征,进行新实体父级预测。
方法二与以往研究都不同,TALN在父级候选部分做了详细的数据分析,并依据分析结果设计模型。首先它定义了以下概念:
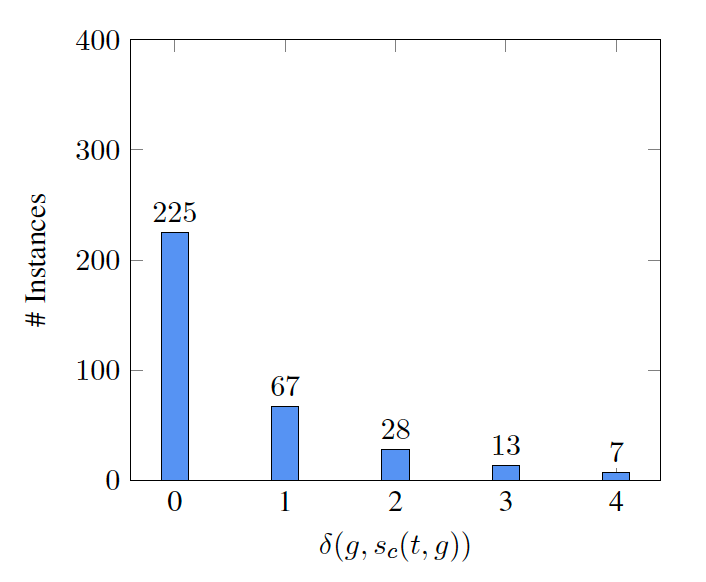
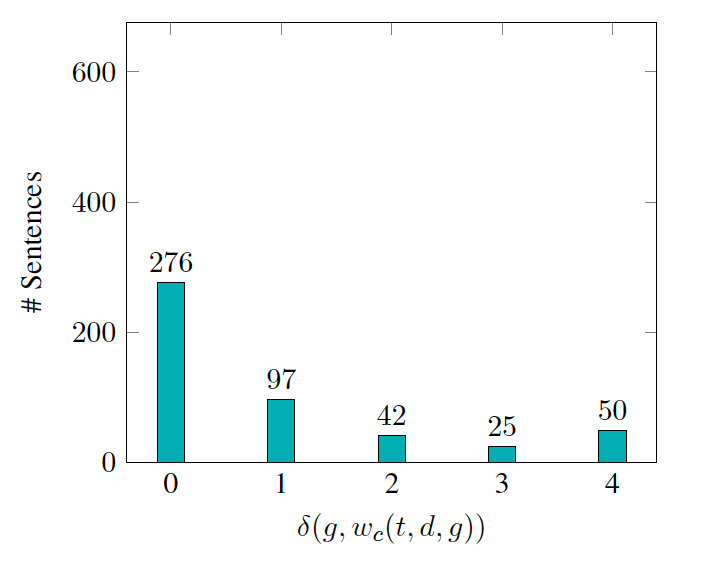
(1)wc与sc:wc代表从某一句实体定义中筛选出的同义词集;sc代表从所有实体定义中筛选出的同义词集
(2)g:同义词集需要满足条件g,即同义词集中的所有词根必须出现在新实体的定义中,并且新实体与同义词在taxonomy上的路径最短。路径长度分别为δ(g, sc(t, g)),δ(g,wc(t, d, g))。
通过统计发现,发现新实体与δ(g, sc(t, g)),实体定义与δ(g,wc(t, d, g))之间都服从Zipfian分布,并由此推断优化每一个wc,即可得到最优化的sc。
![]()
![]()
在具体的排序算法中,MSejrKu采用个性化Pagerank进行词义消歧和排序操作,为解决训练数据不足导致的模型泛化性不足问题,将pointwise转化为pairwise,将排序问题作为逐点回归或成对分类来处理,通过Gaussian kernel SVM确定每一句的候选父级wc,最后采用投票方式或Pagerank决定所有句子中的候选父级。
![]()
二. 初具规模时的图谱融合
不难发现,当图谱规模较小时,大多采用基于词法句法,无法利用图层次结构相关特征。当图谱规模达到一定规模,新实体融合主要依靠知识表示和图结构相关特征设计并改进模型。
《Enriching Taxonomies With Functional Domain Knowledge》
与上述论文不同,本文应用了大量的图语义特征和图中心度量特征,因此在语义理解上,会有明显的提升。
本文的主要挑战是找到一个计算度量,它能够代表图谱中独立于语言和领域的语义逻辑,将新概念插入到知识结构,不破坏之前网络的语义完整性关系。算法面向已存在的概念框架和新的概念,学习了一个高维的词向量。用于对比新概念和相邻概念之间的相似度,来预测这种潜在的链接新旧概念之间的父子关系,为了解决这个挑战,本文将高效图论特征和利用额外知识的语义相似度特征进行结合。其中选取了大量的图特征和语义特征:Katz相似度,RandomWalk Betweenness Centrality(如果想尝试更多的中心度量特征,可参考论文《Unsupervised graph-based topic labelling using dbpedia》),PMI等
训练集的正例是图谱中已经存在的概念的父级,反例是新概念通过KNN随机获得的父级。每一个概念取相同数量的正例和反例,模型采用LambdaMART,对每对候选父子级进行排序,最终判断出最适合父子级的新实体和已有实体。
![]()
不难发现,上一篇文章虽然使用了图结构相关特征,也获取了语义子图,但并没有将重点放在上下级结构的学习上,同时在新实体的抽取方面也没有做过多的研究。接下来的算法,不仅着重学习了图谱中的父子级结构,同时也研究了如何找到符合目前图谱结构的新实体。
《Using Taxonomy Tree to Generalize a Fuzzy Thematic Cluster》
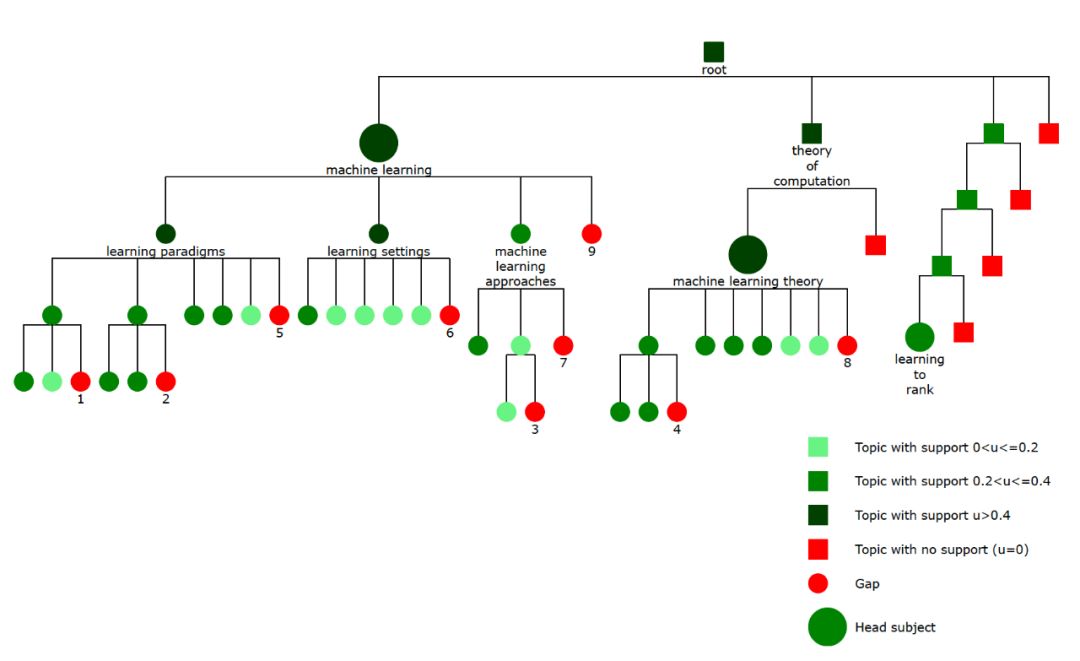
本文基于已有图谱结构,借助模糊主题聚类算法(FADDIS),发现并概念化新发现的实体,通过最小化惩罚函数,找到新实体在图谱中的位置。
为什么要选择FADDIS算法:(1)Laplacian伪逆规范化(Lapin):通过模拟热分布实现相似数据转换,从而使聚类结构更清晰;(2)可加性:相似值是多个隐藏主题的贡献之和;(3)非完整性:集群不一定涵盖所有可用的关键短语,因为文本集合可能有一些无关短语。
惩罚函数主要由三个部分组成:head subjects, gaps,offshoots。其中head subjects代表模糊子集最终对应到图谱中的中间节点(概念节点),gaps代表可以被插入的位置,offshoots代表应该在head subjects下但插入到错误未位置的叶子节点。通过Parsimonious Generalization of Fuzzy Sets算法,得到模糊子集H。通过对head subjects, gaps,offshoots最小化,将模糊子集正确的融合进已有图谱,并保证图谱结构的整体准确性。
![]()
![]()
![]()
三. 两个完整图谱的融合—实体对齐
两个完整图谱的融合其实本质上是不同领域实体词之间的实体对齐,从而形成语义上的链接,是后续的不同业务之间推荐的基础。
(一) String-Similarity-based Entity Alignment
基于字符串相似的实体对齐方法,大致分为两种,一是与实体相关的语义字符串相似度,如定义,属性。
《RDF-AI: an Architecture for RDF Datasets Matching, Fusion and Interlink》
RDF-AI实现了一个由预处理、匹配、融合、互连和后处理模块组成的对齐框架,提出一种基于属性的实体对匹配算法:基于序列对齐的模糊字符串匹配算法和词义相似度算法。后者有两种实现:基于WordNet的同义词比较算法和基于SKOS的taxonomy相似算法(详见https://www.w3.org/TR/2005/WD-swbp-skos-core-guide-20051102/),这两种算法也可以结合使用。
![]()
![]()
利用上述方法计算属性匹配相似度,得到两图中所有可能对齐的属性对,通过对属性对相似度求和得到实体相似度。最终实体相似度最高者,被认为是一个实体。但缺点非常明显,即存在WordNet和SKOS这样的外部图谱,并且属性中的词必须存在在外部图谱中。
《Limes: a time-efficient approach for large-scale link discovery on the web of data》
LIMES基于三角不等距离逼近算法,推导距离的上下边界条件,使用这些边界条件来减少映射比较次数。被分割的空间内可以计算该区域中的每个实例与其他实例之间的相似度距离的精确近似。通过这些方法,可以在不牺牲精度的情况下有效地发现链接数据源之间的链接。
LIMES在相似度距离计算上提供了多种方案,包括字符串,语义,向量,point-set等(详见http://dice-group.github.io/LIMES/#/)。
![]()
![]()
![]()
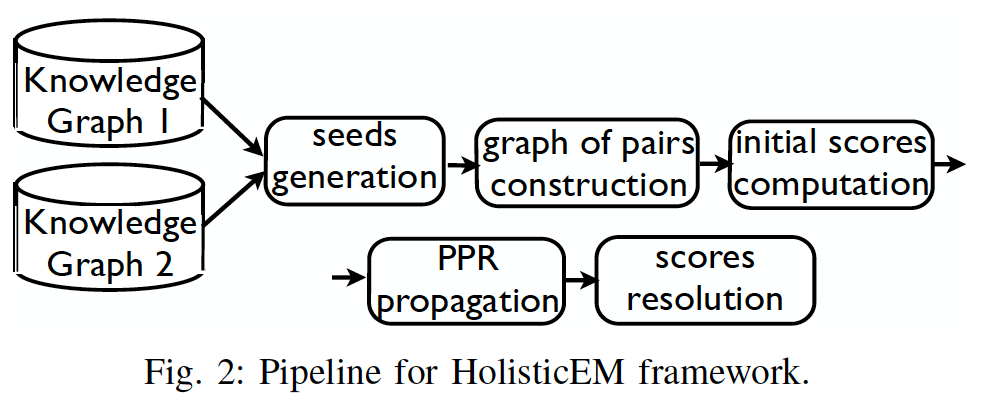
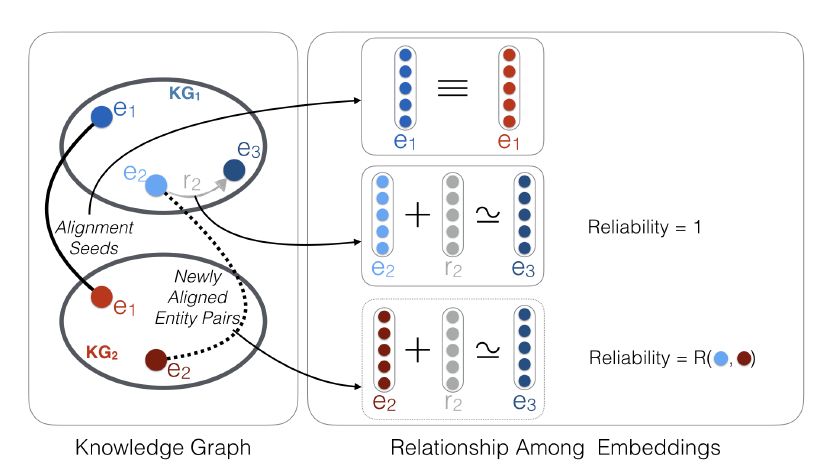
《Holistic Entity Matching Across Knowledge Graphs》
也有一些研究使用图形相似性来提高实体对齐性能。本文提出了一种基于Personalized PageRank的知识库实例对齐算法(HolisticEM)。除了经典的Personalized PageRank,创新之处有两点:
(1)考虑了每个实体中,每个单词对整个实体的语义贡献程度,一个单词的IDF得分越低,这个单词共享的实体就越多,因此,这样一个词与其实体的区别越小。
![]()
(2)Pairs Graph构建:首先通过计算基于IDF的实体属性相似度选出种子对集合,其次,使用与种子对相连接实体,并将必要的新实体对和边添加到Pairs Graph图中,扩展原有种子对。这样的种子对筛选方式要比n-hop方式获取到该实体更多的语义信息。
![]()
(二) Embedding-based Entity Alignment
基于字符串相似性的实体对齐,大多都局限在实体,定义,属性的字符串描述上,无法对图谱结构进行量化。基于知识表示的实体对齐方法不仅能够学习已有结构中的潜在联系,同样也能灵活添加更多语义特征。
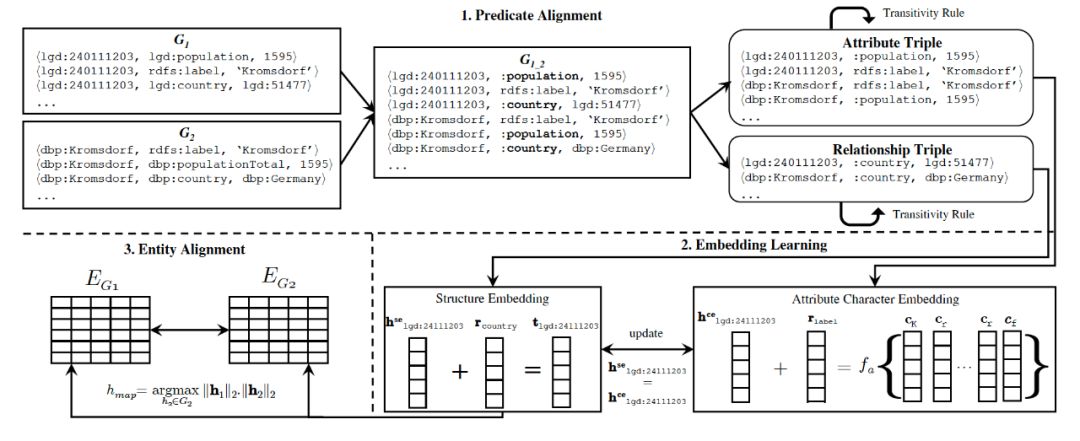
《Entity Alignment between Knowledge Graphs Using Attribute Embeddings》
不同于TranE和PTransE等模型,学习实体或者路径,本文还考虑了图谱中的实体属性值,进一步丰富了实体的语义环境。算法分为三个部分:谓词对齐、知识表示学习和实体对齐。
基于嵌入的实体对齐要求两个KG的嵌入(关系和实体嵌入)落在同一向量空间中。为了给关系嵌入提供一个统一的向量空间,我们基于谓词相似度(即谓词对齐)合并了两个KG。谓词对齐模块查找部分相似的谓词,并使用统一的命名方案重命名它们。基于这个统一的命名方案,将两图合并。然后,将合并后的图分解为一组关系三元组和一组属性三元组,用于表示学习。
表示学习模块使用结构表示学习和属性表示学习,共同学习两个KG的实体表示。使用关系三元组学习结构表示,而使用属性三元组学习属性嵌入。最初,来自G1和G2的实体结构表示属于不同的向量空间,因为来自两个KG的实体使用不同的命名方案表示。相反,从属性三元组中学习到的属性表示可以落在同一向量空间中。即使属性来自不同的KG,但属性字符串基本类似,因此可以从属性字符串中学习字符表示。然后,利用属性字符表示,将实体结构表示带入同一向量空间中,使得实体嵌入能够从两个KGs中获取实体间的相似性。
![]()
《Iterative Entity Alignment via Joint Knowledge Embeddings》
大多数现有的方法通常依赖于诸如维基百科之类的实体外部信息,并且需要大量的人工特征来完成对齐。本文提出了一种基于联合知识表示的实体对齐方法。算法分为三部分:知识表示,联合表示,实体对齐迭代。知识表示部分采用了经典的TransE模型。而在联合表示部分,为将不同KG的实体和关系映射到一个统一的低维语义空间,基于一组已对齐的实体子集,设计了三种模型:
(1) 受到基于翻译的KRL方法启发,将对齐视为实体之间的一种特殊关系,在需要对齐的实体之间执行特定的翻译模型来学习联合表示。
(2) 线性变换模型,即学习两实体之间的线性变化矩阵。
(3) 参数共享模型:利用变量之间依赖性的先验知识替代正则化变量。
最终通过实体迭代对齐方式,缩小联合语义空间中的语义距离,提高实体对齐性能。
![]()
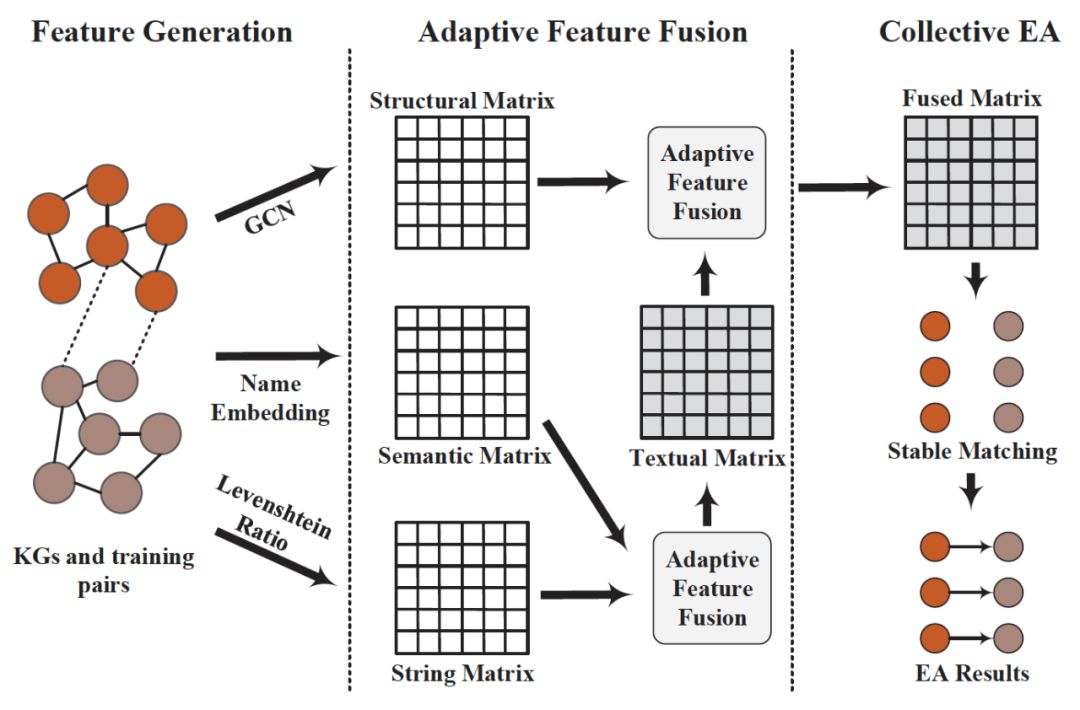
《Collective Embedding-based Entity Alignment via Adaptive Features》
以往研究中,基于知识表示的解决方案都是独立的处理实体,而没有考虑实体之间的相互依赖性。此外,大多数基于知识表示的实体对齐方法存在以下问题:
(1)在表示层融合不同特征,生成统一的实体表示,进行对齐,这可能会导致信息丢失。
(2)在结果层使用手动调整的权重聚集特征,这在特征数量不断增加的情况下并不实用。
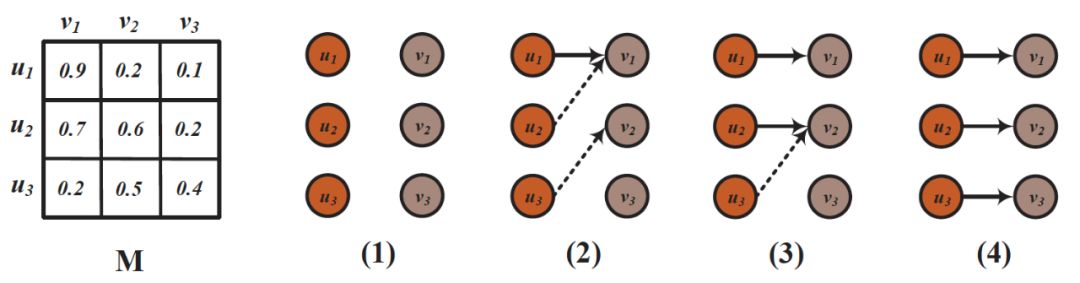
针对这些不足,本文提出了一个基于集合嵌入的自适应特征融合实体对齐框架。首先使用三个具有代表性的特征,即结构、语义和字符串,来捕捉异构KGs中实体之间不同方面的相似性。然后通过自适应特征融合策略动态分配权重。最后,将实体对齐定义为待对齐实体之间的stable matching问题,(详见论文《Secure stable matching at scale》),并使用融合特征矩阵构造偏好矩阵,采用延迟接受算法(deferred acceptance algorithm,详见论文《Deferred acceptance algorithms: history, theory, practice, and open questions》)实现实体对齐。
![]()
假设有三个源实体u1,u2,u3和三个目标实体v1,v2,v3。给定融合相似度矩阵M,其中实体对应行/列中的值表示其偏好(首选较大的值)。源实体按照偏好矩阵,依次向目标实体进行对齐。
![]()
四. 总结
文章分别介绍了在不同图谱规模下,不同的图谱融合算法,我们可以根据当下的数据情况进行选择。当图谱规模较小时,我们还是推荐上文介绍的小规模图谱融合的方法,可解释性高,算法简单,同时可达到不错的效果。当图谱规模非常大时,图谱自身就是一个可解释性非常高的模型,此时采用层次聚类或知识表示抽象化图谱结构,才能达到较好的效果。
在实际应用中,需要根据不同的业务建立不同的图谱,散落在各业务线的数据,永远只是服务于自身业务,并不能发现业务之间的潜在联系。为了实现跨业务语义解析和推荐,图谱融合是关键,需要根据不同业务的特点选择不同的融合算法,复杂不一定是最好。
从以上研究中可以看到,如何丰富并更好的抽象新实体的外部语义环境和其在图谱中的关联结构,依然是今后研究的重点。
参考文献
[1].《VCU at Semeval-2016 Task 14: Evaluating similarity measures for semantic taxonomy enrichment》
[2].《TALN at SemEval-2016 Task 14: Semantic Taxonomy Enrichment Via Sense-Based Embeddings》
[3].《MSejrKu at SemEval-2016 Task 14: Taxonomy Enrichment by Evidence Ranking》
[4].《Enriching Taxonomies With Functional Domain Knowledge》
[5].《Using Taxonomy Tree to Generalize a Fuzzy Thematic Cluster》
[6].《RDF-AI: an Architecture for RDF Datasets Matching, Fusion and Interlink》
[7].《Holistic Entity Matching Across Knowledge Graphs》
[8].《Entity Alignment between Knowledge Graphs Using Attribute Embeddings》
[9].《Iterative Entity Alignment via Joint Knowledge Embeddings》
[10].《Collective Embedding-based Entity Alignment via Adaptive Features》
招聘信息
丁香园大数据NLP团队招聘各类算法人才,Base杭州。NLP团队的使命是利用NLP(自然语言处理)、Knowledge Graph(知识图谱)、Deep Learning(深度学习)等技术,处理丁香园海量医学文本数据,打通电商、在线问诊、健康知识、社区讨论等各个场景数据,构建医学知识图谱,搭建通用NLP服务。团队关注NLP前沿技术,也注重落地实现,包括但不仅限于知识图谱、短文本理解、语义搜索、可解释推荐、智能问答等。加入我们,让健康更多,让生活更好!
欢迎各位朋友推荐或自荐至 yangbt@dxy.cn
本文转载自公众号丁香园大数据,作者丁香园大数据NLP
推荐阅读
AINLP年度阅读收藏清单
知识图谱构建技术综述与实践
谈谈医疗健康领域的Phrase Mining
医疗领域知识图谱构建-关系抽取和属性抽取
中文NER任务实验小结报告——深入模型实现细节
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
鼠年春节,用 GPT-2 自动写对联和对对联
transformer-XL与XLNet笔记
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
征稿启示 | 稿费+GPU算力+星球嘉宾一个都不少
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。
![]()