CVPR2019 oral | 这个面部3D重建模型,造出了6000多个名人的数字面具
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | Ayush Tewari等
来源 | 机器之心
马克斯·普朗克计算机科学研究所、斯坦福大学等近期提出了一种新型的面部三维重建模型,效果惊艳。该模型基于自监督学习,使用了来自 YouTube 抓取的 6000 多个名人的视频片段进行训练;其能以任意帧数重建人脸面部,适用于单目和多帧重建。特别是,该模型可以完全从零开始学习,将面部的多种特征分离再重新组合,结构化程度很高。目前这项工作已被CVPR2019接收。
论文展示地址:https://gvv.mpi-inf.mpg.de/projects/FML19/
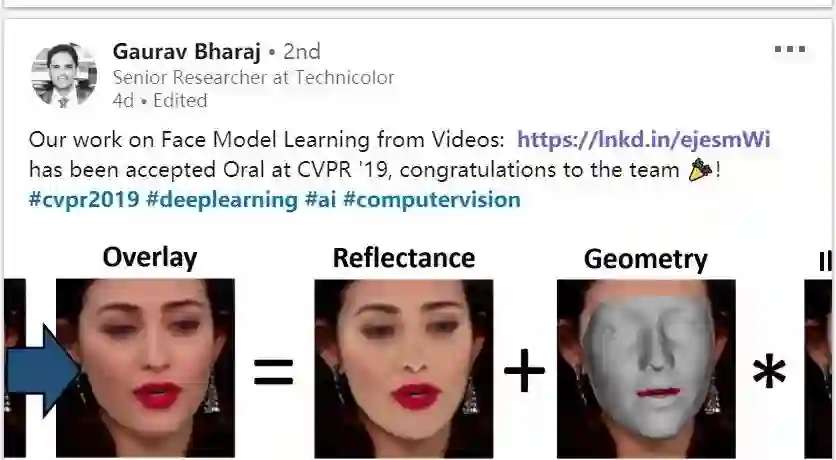
如下图所示,最右边的重建人脸除了没有皱纹以外,身份特征和面部表情都和原人相当一致,阴影效果也高度还原。只是眼睛部分似乎不太对,显得浑浊无神,看看视频会更清楚。

这个合成效果也很不错,表情动态很到位。只是可能原人的眼神实在太有戏,AI 也表示无力模仿。

值得注意的是,这个面部重建模型的 pipeline 很复杂,但又几乎无处不在使用深度学习。重建面部不能很好地还原皱纹,可能是因为自监督学习过程中多帧图像面部动作的正则化作用,但从另一方面来看,这也使得身份重建更加鲁棒。
简言之,研究者把面部分解成了反照率、三维几何形状和光照等特征,再进行组合重建。如下图所示,overlay 是最终合成结果。
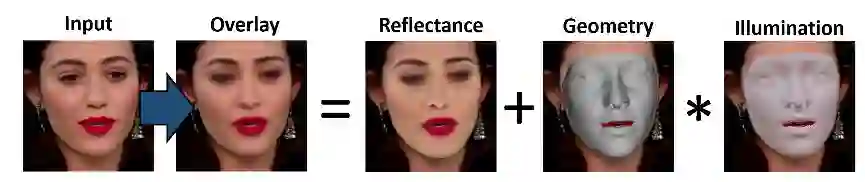
图 1:本文提出了基于 in-the-wild 视频数据的深度网络的多帧自监督训练,以联合学习面部模型和 3D 面部重建。该方法成功地解纠缠了面部形状、外观、表情和场景光照。
如下图所示,研究者还提供了 200 多个重建结果展示。

展示地址:https://gvv.mpi-inf.mpg.de/projects/FML19/visualizeResults.html
以下是和其它已有方法的比较。从图中的效果看来,该模型合成的各种特征都能很好地贴合面部,不受侧面视角影响。

图 6:与 Tewari 等人 [59] 的方法比较。当面部大部分被遮挡时,该方法也优于 Tewari 等人的方法。
除了还原度以外,其相对于其它方法可以更好地分离不同特征。

图 8:与 Tran 等人 [62] 的方法对比。我们可以估计更好的几何形状,并将反射与光照分离。注意 Tran 等人的方法不能分离反射和光照(或阴影)。
研究者使用了 VoxCeleb2 多帧视频数据集来训练模型。该数据集包含从 Youtube 抓取的 6000 多个名人的超过 140k 部视频。他们一共从这个数据集采样了 N=404k 的多帧图像
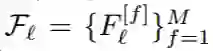

引言
从视觉数据重建面部在视觉和图形中具有广泛的应用,包括面部跟踪、情感识别以及与多媒体相关的交互式图像/视频编辑任务。面部图像和视频无处不在,因为智能设备、消费者和专业相机提供了连续且几乎无穷无尽的来源。当在没有受控场景定位、照明或侵入式设备(例如,自我中心照相机或演员身上的动作追踪标记)的情况下捕获这样的数据时,其属于「in-the-wild」图像。通常,in-the-wild 数据具有低分辨率、噪声或包含运动和焦点模糊,使得重建问题比在受控设置中更难。来自 in-the-wild 单目 2D 图像和视频数据的三维人脸重建涉及解纠缠面部形状身份(中性几何)、皮肤外观(或反照率)和表情,以及估计场景光照和相机参数。其中一些属性,例如反照率和光照,在单目图像中不易分离。此外,由于面部毛发、太阳镜和大幅头部旋转导致的不良场景照明、深度模糊以及遮挡使得 3D 面部重建变得复杂化。
为了解决困难的单目三维人脸重建问题,大多数现有方法依赖于现有的强大的先验模型,这些模型充当了其他不适定问题的正则化因子。尽管这些方法实现了令人印象深刻的面部形状和反照率重建,但其使用的面部模型引入了固有的偏差。例如,3D Morphable Model(3DMM)基于相对较小规模的白种人演员的 3D 激光扫描集,从而限制了泛化到一般的现实世界身份和种族。随着基于 CNN 的深度学习的兴起,人们已经提出了各种技术,其除了 3D 重建之外还从单目图像执行面部模型学习。然而,这些方法严重依赖于已有的 3DMM 来解决单目重建设置的固有深度模糊。而有另一些工作就不需要类似 3DMM 的面部模型,基于照片集。然而,这些方法需要同一个目标的非常大量(例如,≈100)的面部图像,因此它们对训练集有很高的要求。
在本文中,研究者介绍了一种方法,该方法使用从互联网视频中抓取的剪辑来学习全面的人脸身份模型。该面部身份模型包括两个部分:一个部件表征面部身份的几何形状(modulo expressions),另一个部件表征根据反照率的面部外观。由于其对训练数据的要求很低,该方法可以使用几乎无穷无尽的社区数据,从而获得具有更好泛化性的模型,而用激光扫描类似的一大群人进行模型建造几乎是不可能的。与大多数以前的方法不同,该模型不需要已有的形状标记和反照率模型作为初始化,而是从头开始学习。因此,该方法适用于没有现有模型,或者难以从 3D 扫描创建这样的模型(例如,对于婴儿的面部)的情况。
从技术角度来看,本研究的主要贡献之一是提出了新型的多帧一致性损失,这确保了面部身份和反照率重建在同一主体的帧之间是一致的。通过这种方式,可以避免许多单目方法中存在的深度模糊,并获得更准确和更鲁棒的面部几何和反照率模型。此外,通过在本研究的学习面部识别模型和现有的 blendshape expression 模型之间强加正交性,该方法可以自动将面部表情从基于身份的几何变化中解纠缠,而不需要求助于大量的手工制作的先验。
总之,本研究基于以下技术贡献:
一种深度神经网络,其从包含每个目标的多个帧的无约束图像的大数据集中学习面部形状和外观空间,例如多视图序列,甚至单目视频。
通过投影到 blendshapes 的 nullspace 上进行显式的混合形状(blendshape)和身份的分离,从而实现多帧一致性损失。
基于 Siamese 网络的新型多帧身份一致性损失,具有处理单目和多帧重建的能力。
完整视频演示和方法解读
论文:FML: Face Model Learning from Videos

论文地址:https://gvv.mpi-inf.mpg.de/projects/FML19/paper.pdf
摘要:基于单目图像的面部三维重建是计算机视觉中长期存在的问题。由于图像数据是 3D 面部的 2D 投影,因此产生的深度模糊性使问题变得不适定。大多数现有方法依赖于由有限的 3D 面部扫描构建的数据驱动的先验。相比之下,我们提出了一种深度网络的基于视频的多帧自监督训练,其(i)在形状和外观上学习面部身份模型,同时(ii)联合学习重建 3D 面部。我们只使用从互联网收集的未经标记(in-the-wild)视频片段来学习面部模型。几乎无穷无尽的训练数据源可以学习高度通用的 3D 人脸模型。为了实现这一点,我们提出了一种新颖的多帧一致性损失,确保在目标面部的多个帧上保持一致的形状和外观,从而最小化深度模糊。在测试时,我们可以使用任意数量的帧,这样我们就可以执行单目和多帧重建。
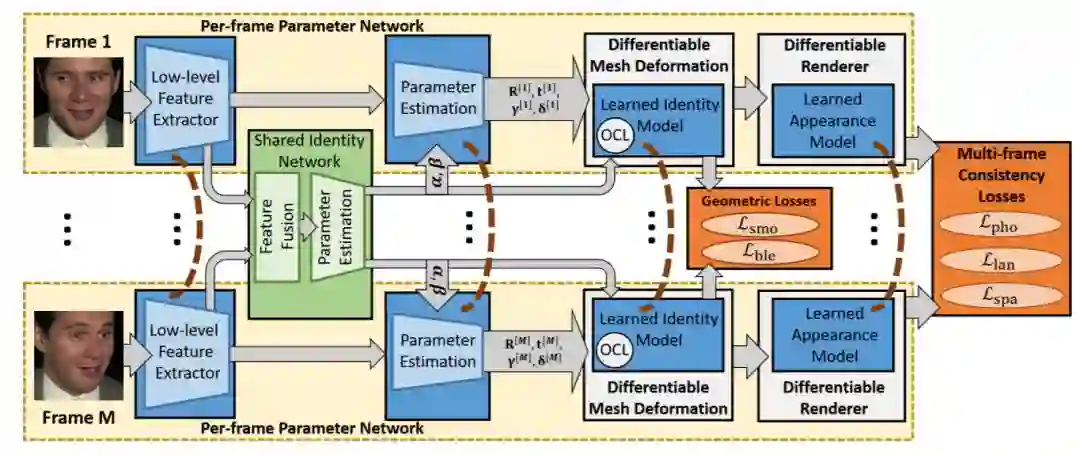
图 2:训练 pipeline 图示。给定多帧输入展示人不同的面部表情、头部姿势和光照下,我们的方法首先估计每帧的这些参数。此外,它联合获得控制面部形状和外观的共享身份参数,同时学习基于图形的几何和 per-vertex 外观模型。我们使用可微分网格变形层与可微分面部渲染器相结合来实现基于模型的面部自编码器。

图 4:通过从 in-the-wild 数据学习最优模型,我们的方法可以生成面部几何的高质量单目重建、反照率和光照。这使得我们也能重建面部毛发(胡子、眉毛等)和妆容。
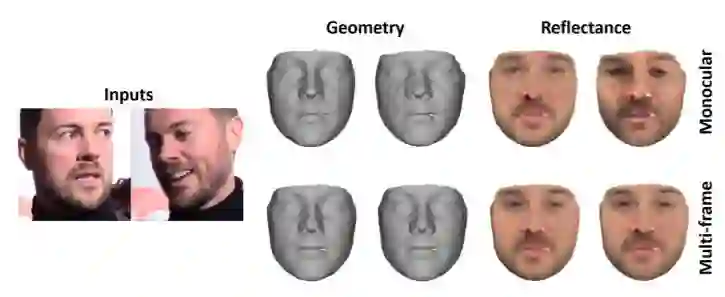
图 5:单目与多帧重建。为清晰起见,所有结果均以正面和中性表情展示。多视图重建改善了一致性和质量,尤其是在部分图像被遮挡的区域中。

图 7:与 [48,52,60] 的比较。这些方法受(合成)训练集和/或基础 3D 脸部模型的限制。我们的最佳学习模型可以产生更准确的结果,因为它是从大量真实图像中学习的。

图 9:与 Booth 等人 [12] 的纹理模型对比。[12] 不能分离阴影,而我们的方法可以估计反照率模型。
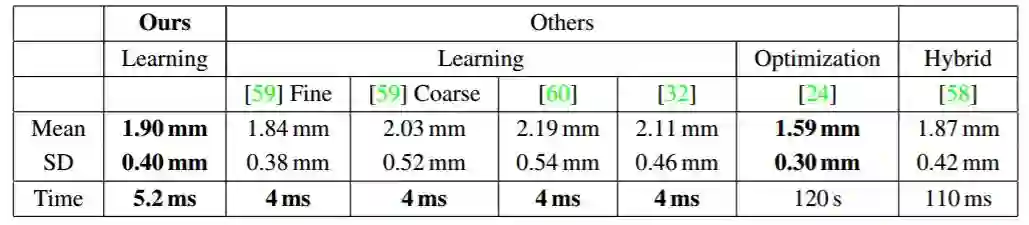
表 2:FaceWarehouse 上的几何误差。我们的方法与 [59] 和 [58] 相当,并且优于 [60] 和 [32]。请注意,与这些方法相比,我们在训练期间不需要预先计算的面部模型,而是从头开始学习。它接近 [24] 的离线高质量方法,同时速度提高了几个数量级,不需要特征检测。
*推荐阅读
CVPR2019 | FSAF:来自CMU的Single-Shot目标检测算法
人体姿态估计做到今天,还有哪些「硬核场景」、「性能瓶颈」、「新战场」上的难题?
小Tips:如何查看和检索历史文章?
有不少小伙伴提问如何号内搜文章,其实很简单,在“极市平台”公众号后台菜单点击极市干货-历史文章,或直接搜索“极市平台”公众号查看全部消息,即可在如下搜索框查找往期文章哦~
ps.可以输入CVPR2019/目标检测/语义分割等等,快去探索宝藏吧~~
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~




