十行代码就能搞定深度学习?飞桨框架高层API,计算机视觉研究院带你一起轻松玩转AI(附源码)




前言 向往深度学习技术,可是深度学习框架太难学怎么办?百度倾心打造飞桨框架高层API,零基础也能轻松上手深度学习,一起来看看吧?
另:文末有福利,一定要看完
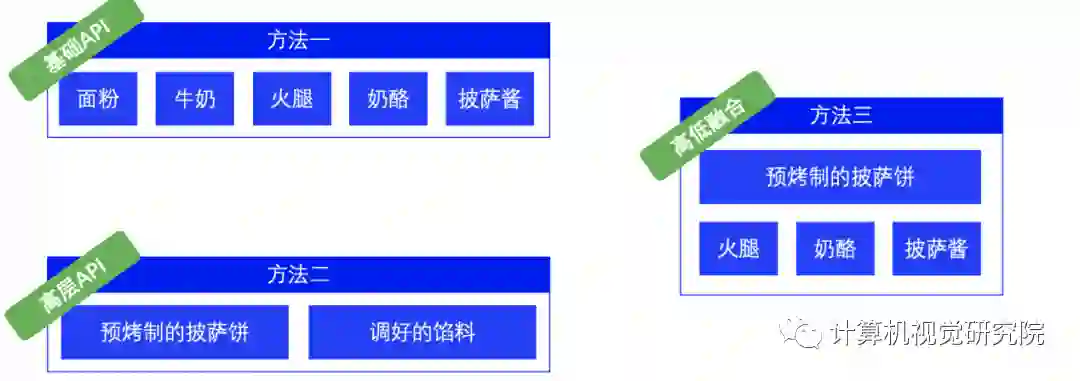
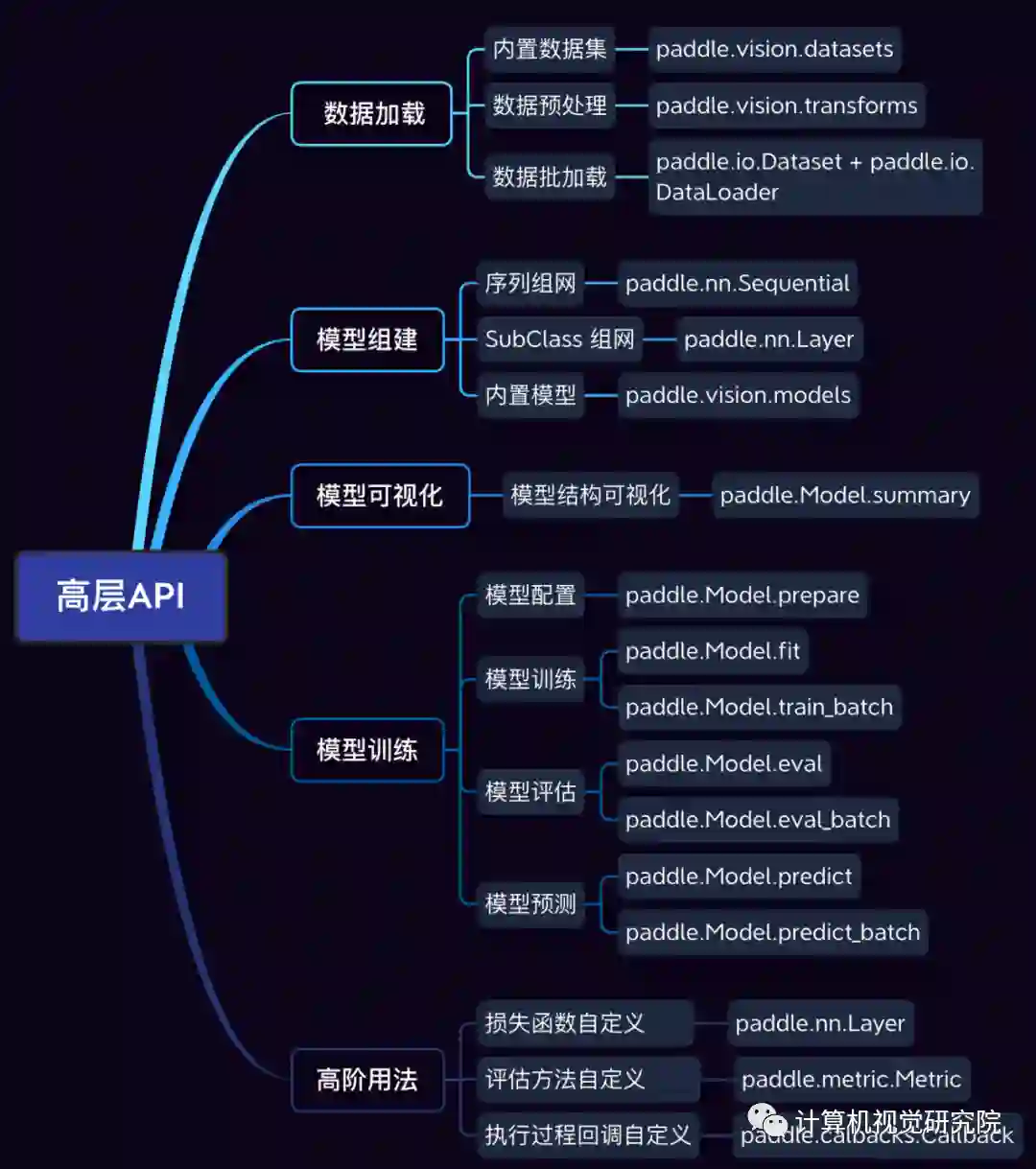
import paddlefrom paddle.vision.transforms import Compose, Normalizefrom paddle.vision.datasets import MNISTimport paddle.nn as nn# 数据预处理,这里用到了归一化transform = Compose([Normalize(mean=[127.5],std=[127.5],data_format='CHW')])# 数据加载,在训练集上应用数据预处理的操作train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)# 模型组网mnist = nn.Sequential(nn.Flatten(),512),10))# 模型封装,用 Model 类封装model = paddle.Model(mnist)# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式=paddle.optimizer.Adam(parameters=model.parameters()),loss=nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy())# 模型训练,model.fit(train_dataset,epochs=10,batch_size=64,verbose=1)# 模型评估,verbose=1)# 模型保存,model.save('model_path')
from paddle.io import Datasetclass MyDataset(Dataset):"""步骤一:继承 paddle.io.Dataset 类"""def __init__(self):"""步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集"""super(MyDataset, self).__init__()self.data = [['traindata1', 'label1'],['traindata2', 'label2'],['traindata3', 'label3'],['traindata4', 'label4'],]def __getitem__(self, index):"""步骤三:实现__getitem__方法,定义指定 index 时如何获取数据,并返回单条数据(训练数据,对应的标签)"""data = self.data[index][0]label = self.data[index][1]return data, labeldef __len__(self):"""步骤四:实现__len__方法,返回数据集总数目"""return len(self.data)# 测试定义的数据集train_dataset = MyDataset()print('=============train dataset=============')for data, label in train_dataset:print(data, label)
# Sequential 形式组网mnist = nn.Sequential(nn.Flatten(),nn.Linear(784, 512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512, 10))
# SubClass 方式组网class Mnist(nn.Layer):def __init__(self):super(Mnist, self).__init__()self.flatten = nn.Flatten()self.linear_1 = nn.Linear(784, 512)self.linear_2 = nn.Linear(512, 10)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.2)def forward(self, inputs):y = self.flatten(inputs)y = self.linear_1(y)y = self.relu(y)y = self.dropout(y)y = self.linear_2(y)return y
import paddlefrom paddle.vision.models import resnet18# 方式一: 一行代码直接使用resnetresnet = resnet18()# 方式二: 作为主干网络进行二次开发class FaceNet(paddle.nn.Layer):def __init__(self, num_keypoints=15, pretrained=False):super(FaceNet, self).__init__()self.backbone = resnet18(pretrained)self.outLayer1 = paddle.nn.Linear(1000, 512)self.outLayer2 = paddle.nn.Linear(512, num_keypoints*2)def forward(self, inputs):out = self.backbone(inputs)out = self.outLayer1(out)out = self.outLayer2(out)return out
mnist = nn.Sequential(nn.Flatten(),nn.Linear(784, 512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512, 10))# 模型封装,用 Model 类封装model = paddle.Model(mnist)model.summary()
其输出如下:
---------------------------------------------------------------------------Layer (type) Input Shape Output Shape Param===========================================================================Flatten-795 [[32, 1, 28, 28]] [32, 784] 0Linear-5 [[32, 784]] [32, 512] 401,920ReLU-3 [[32, 512]] [32, 512] 0Dropout-3 [[32, 512]] [32, 512] 0Linear-6 [[32, 512]] [32, 10] 5,130===========================================================================Total params: 407,050Trainable params: 407,050Non-trainable params: 0---------------------------------------------------------------------------Input size (MB): 0.10Forward/backward pass size (MB): 0.57Params size (MB): 1.55Estimated Total Size (MB): 2.22---------------------------------------------------------------------------{'total_params': 407050, 'trainable_params': 407050}
# 将网络结构用 Model 类封装成为模型model = paddle.Model(mnist)# 为模型训练做准备,设置优化器,损失函数和精度计算方式=paddle.optimizer.Adam(parameters=model.parameters()),loss=paddle.nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy())# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式epochs=10,batch_size=64,verbose=1)# 启动模型评估,指定数据集,设置日志格式verbose=1)# 启动模型测试,指定测试集Model.predict(test_dataset)
# 模型封装,用 Model 类封装model = paddle.Model(mnist)# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),loss=nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy())# 构建训练集数据加载器train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)# 使用 train_batch 完成训练for batch_id, data in enumerate(train_loader()):model.train_batch([data[0]],[data[1]])# 构建测试集数据加载器test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), batch_size=64, shuffle=True)# 使用 eval_batch 完成验证for batch_id, data in enumerate(test_loader()):model.eval_batch([data[0]],[data[1]])# 使用 predict_batch 完成预测for batch_id, data in enumerate(test_loader()):model.predict_batch([data[0]])
CPU 版pip3 install paddlepaddle==2.0.0rc0 -i https://mirror.baidu.com/pypi/simpleGPU 版pip3 install paddlepaddle_gpu==2.0.0rc0 -i https://mirror.baidu.com/pypi/simple
/End.
后台回复“飞桨代码”

获取源码下载地址

登录查看更多
相关内容

PaddlePaddle(PArallel Distributed Deep LEarning)是由百度推出的一个易用、高效、灵活、可扩展的深度学习框架。
官方网站:https://www.paddlepaddle.org.cn
Arxiv
0+阅读 · 2021年2月11日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年2月11日