![]()
摘要 随着应用数据处理需求的激增, 在传统冯 · 诺依曼 (von Neumann) 体系结构中, 处理器到主存 之间的总线数据传输逐渐成为瓶颈. 不仅如此, 近年来兴起的数据密集型应用, 如神经网络和图计算 等, 呈现出较严重的数据局部性, 缓存命中率低. 在这些新兴数据密集型应用的处理过程中, 中央处 理器到主存间的数据传输量大, 导致系统的性能不佳且能耗变高. 针对传统冯 · 诺依曼体系结构的局 限性, 内存计算通过赋予主存端一定的计算能力, 以缓解因数据量大以及数据局部性差带来的总线拥 堵和传输能耗高的问题. 内存计算有两大形式, 一种是以高带宽的连接方式将计算资源集成到主存单 元中 (近数据计算), 另一种是直接利用存储单元做计算 (存内计算). 这两种形式有各自的优缺点和适 用场景. 本文首先介绍并分析了内存计算的提出和兴起原因, 然后从硬件和微体系结构方面介绍内存 计算技术, 接着分析和总结了内存计算所面临的挑战, 最后介绍了内存计算给目前流行的应用带来的 机遇.
https://engine.scichina.com/publisher/scp/journal/SSI/51/2/10.1360/SSI-2020-0037?slug=fulltext
近年来, 应用数据呈现爆炸式增长, 处理器和主存之间的带宽限制成为数据密集型应用的瓶颈. 此外, 目前流行的一些数据密集型应用, 如神经网络应用和图计算应用, 数据的局部性差. 这会导致处理器片上缓存命中率降低, 进而导致处理器和主存之间频繁地传输数据. 这样的大量数据传输除了使得总线拥堵并影响性能, 还会造成大量的能耗开销
[1-5]
. 研究表明, 两个浮点数在CPU (central processing unit)和主存之间传输所需的能耗要比一次浮点数运算大两个数量级
[6,7]
. 在大数据系统中, 能耗开销大会使得基于传统冯⋅⋅诺依曼(von Neumann)结构的系统扩展性差, 甚至无法支持大型的数据密集型应用
[8-10]
.
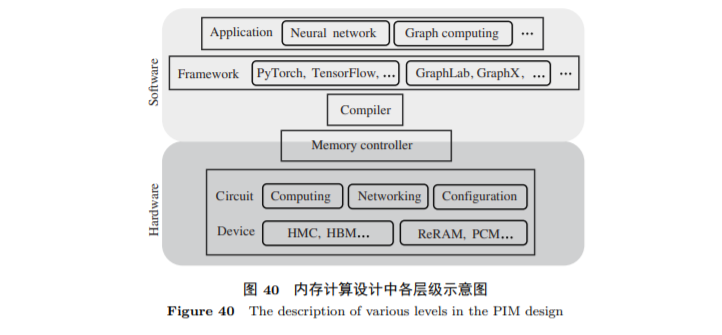
内存计算(processing in memory, PIM)给总线上数据传输量过大的问题提供了一个根源性的解决方案. 它通过赋予内存一部分计算能力, 使其能直接处理一些形式单一且数据量大的计算(例如向量乘矩阵). 内存计算有两种形式, 一种是将计算资源以高带宽的连接方式集成到主存单元中(一般称之为近数据计算, near data computing, NDC)
[11]
, 另一种是直接利用存储单元做计算(一般称之为存内计算, compute in memory, CIM)
[12]
. 这两种形式都很大程度减少了中央处理器和主存之间的数据移动, 从而达到提升系统性能并降低能耗的目的. 数据表明, 近年来提出的内存计算架构相比于传统冯⋅⋅诺依曼架构有着几十, 上百, 甚至上千倍的性能提升
[6,7,12]
. 尽管在性能和能耗方面优势明显, 目前内存计算的应用仍面临着诸多挑战.
在近数据计算方面, 由于内存中用于数据处理的逻辑芯片计算能力较弱, 架构设计者需要分析和提取出程序中适合放到内存中做计算的部分, 其余留给中央处理器处理
[13]
. 其次, 架构设计者还需要针对上层应用的特点, 对近数据计算中的逻辑芯片进行精心设计以取得大幅性能提升
[14]
. 不仅如此, 近数据计算还缺乏高效透明的系统级支持. 虽然一些面向特定应用设计的近数据计算微体系结构提供了上层软件接口, 但是程序员需要对底层充分了解才能够使用该近数据计算系统
[15]
. 也有研究者设计了对上层透明的内存计算系统接口, 但仅能适应特定的内存计算结构, 缺乏通用性
[16]
.
在存内计算方面, 由于用来直接做计算的内存单元能够支持的算子类型有限, 存内计算较难高效支撑复杂多样的计算模式
[12]
. 因此, 研究者们常针对算子类型少且简单的数据密集型应用设计专用的计算体系结构和系统
[12]
. 除此之外, 存内计算模块集成到现有系统结构中的形式尚不明确
[6,12]
. 虽然存内计算模块既可以作为存储模块也可作为计算模块, 但其作为内存的一部分和现有存储系统合作的方式仍有待研究. 另外, 存内计算模块硬件本身存在性能和可靠性的问题, 例如基于非易失存储的存内计算单元中非易失模块的可靠性问题
[17]
.
由此可见, 内存计算技术虽然潜力大, 但是其结构复杂, 与上层应用关系紧密, 应用到现有系统中仍面临着诸多挑战. 因此, 我们对现有的内存计算研究进行综述, 阐述内存计算从硬件架构到软件系统支持的相关技术方法和研究进展. 本文首先详细分析和介绍了内存计算的兴起原因, 然后介绍了内存计算的形式以及目前已有的内存计算微体系结构, 接着分析和总结内存计算所面临的挑战, 最后介绍内存计算给现在流行的应用带来的机遇.
![]()
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源