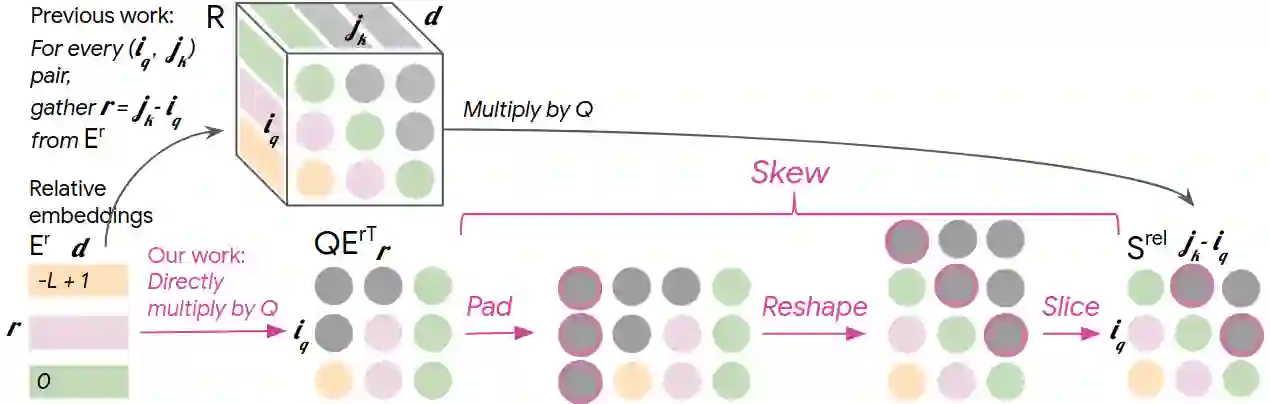
Music relies heavily on repetition to build structure and meaning. Self-reference occurs on multiple timescales, from motifs to phrases to reusing of entire sections of music, such as in pieces with ABA structure. The Transformer (Vaswani et al., 2017), a sequence model based on self-attention, has achieved compelling results in many generation tasks that require maintaining long-range coherence. This suggests that self-attention might also be well-suited to modeling music. In musical composition and performance, however, relative timing is critically important. Existing approaches for representing relative positional information in the Transformer modulate attention based on pairwise distance (Shaw et al., 2018). This is impractical for long sequences such as musical compositions since their memory complexity for intermediate relative information is quadratic in the sequence length. We propose an algorithm that reduces their intermediate memory requirement to linear in the sequence length. This enables us to demonstrate that a Transformer with our modified relative attention mechanism can generate minute-long compositions (thousands of steps, four times the length modeled in Oore et al., 2018) with compelling structure, generate continuations that coherently elaborate on a given motif, and in a seq2seq setup generate accompaniments conditioned on melodies. We evaluate the Transformer with our relative attention mechanism on two datasets, JSB Chorales and Piano-e-Competition, and obtain state-of-the-art results on the latter.
翻译:音乐在很大程度上依赖重复来构建结构和含义。 自 自我参照发生在多个时间尺度上, 从元素到词组, 以及音乐整段内容的重复使用, 例如与ABA结构的片段。 变形器( Vaswani et al., 2017) 是一个基于自我注意的序列模型, 在许多需要保持远程一致性的一代任务中, 已经取得了令人信服的结果 。 这表明自我注意可能也非常适合模拟音乐。 然而, 在音乐构成和性能中, 相对时间尺度是极为重要的。 以对称距离( Shaw et al., 2018) 为基础, 代表变形器中相对位置信息的当前方法, 以及重新使用整段音频结构的音乐成份等长序列。 变形器( Vaswani et al., 201717) 由于中间相对信息的记忆复杂性在序列长度中是四分立的, 我们建议一种算法, 将其中间记忆要求降低到我的序列长度。 这让我们能够证明一个变形器与我们的相对关注机制可以产生一分秒的组合组成( 千个步骤, 四倍的步伐, 在Oore etal etal etal- lavequal laus) 结构上, 我们的变形的C- deal deal deal develillational deal deal deal se res res roal deal deal deal se se routs routs seal seal seal lacude se se lautal lautds sqs