TeaTalk·Online 演讲实录 | 圆满完结!大数据+云原生,再度风云起!



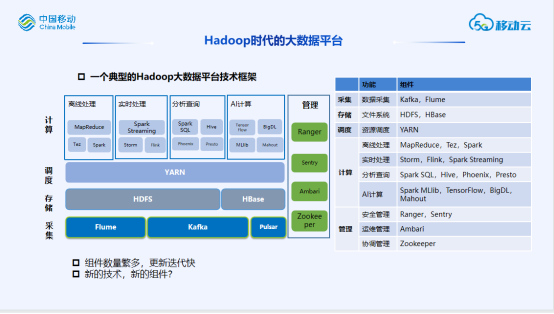
讲解基于开源的Hadoop技术发展以及和云原生技术的渊源
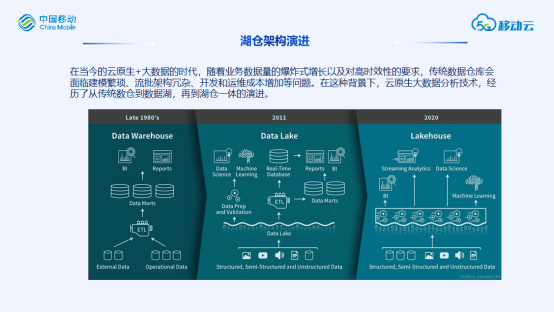
讲解大数据云原生的关键技术,这里主要包括大数据组件容器化、计算存储分离、数据湖&湖仓一体方面
介绍移动云云原生大数据分析Lakehouse产品,这个是大数据与云原生结合的典型案例
对云原生大数据进行总结和展望

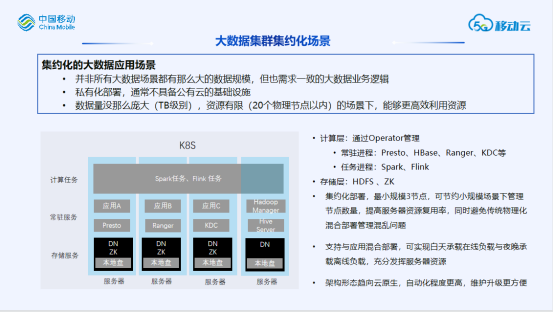
资源弹性伸缩不足
资源利用率低
资源隔离性差
自动化运维成本高
不同组件管理方式不统一
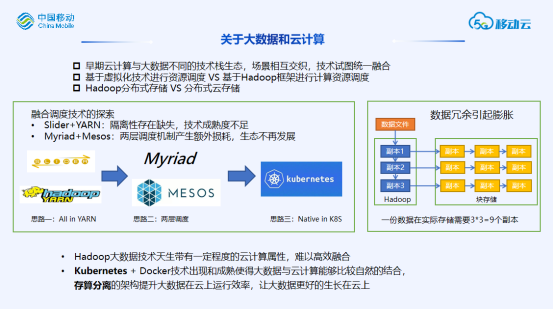

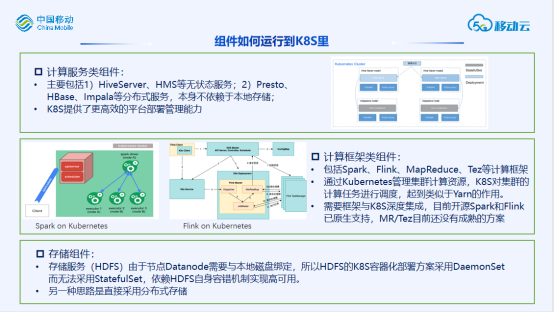

资源统一管理,但是任务会经过K8S/Yarn两层调度,产生额外开销。
采用组件原生支持调度框架,但是需要预先划分好yarn和k8s两个资源池,资源池之间难以负载均衡。
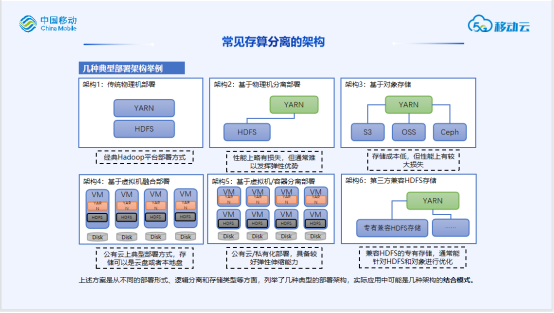

真正降低存储带来的成本(软硬件单位成本、适应不同性能需求下的成本、资源利用率/弹性伸缩带来的成本)
与现有大数据平台体系融合(是否兼容当前接口协议、能否与现有存储良好并存、能否满足当前对性能和扩展性的需求)
更高性价比的存储
数据统一访问方案
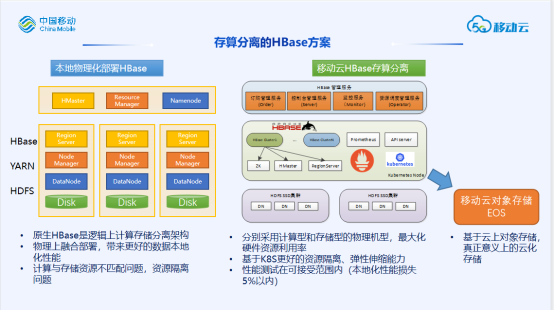

当前底层存储单一,主要以HDFS为主,未来演进为支持多种介质,多种类型数据的统一存储系统。
当前根据业务分多个集群,之间大量数据传输,未来演进到统一存储系统,降低集群间传输消耗。
当前计算框架以MR/Spark为主,未来演进在数据湖上直接构建更多计算框架和应用场景。
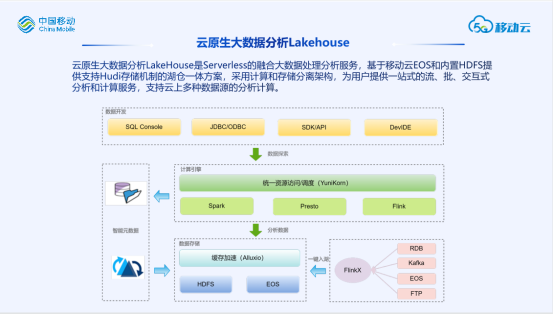

计算存储分离:我们计算基于K8S调度,存储支持HDFS和移动云对象存储EOS两种,并通过Alluxio进行缓存加速,计算存储分别计费,计算不足扩计算,存储不足扩存储。
Serverless:区别于传统资源类服务会按照使用的内存、cpu进行规格计费,Lakehouse对客户可以做到按实际使用的资源量进行计费,用户可以不必精细预估好需求资源,订购以后只有真正运行作业才会记录使用并收取费用,不用不收费。同时即使需要扩缩容规格,也是秒级完成。
All In SQL:传统大数据平台需要用户对大数据组件具备一定的开发能力,而Lakehouse采用通用的SQL作为交互的输入,用户只要会写SQL就能进行开发,像使用数据库一样开发大数据。
智能元数据:支持不同数据源元数据统一管理,同时具备元数据发现能力,对于存储在对象存储上无Schema的数据,能够自动爬取格式并转化为结构化数据。自动化工作减少大量ETL任务的繁琐配置。