成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
Hadoop
关注
14
Hadoop 是 Apache 软件基金会所研发的开放源码并行运算编程工具和分布式档案系统,与 MapReduce 和 Google 档案系统的概念类似。
综合
百科
VIP
热门
动态
论文
精华
精品内容
【干货】大数据入门指南:Hadoop、Hive、Spark、 Storm等
专知会员服务
97+阅读 · 2019年12月4日
【VLDB2019 tutorial】加快分析速度:数据库和大数据系统的自动调参 Speedup Your Analytics: Automatic Parameter Tuning for Databases and Big Data Systems,芬兰赫尔辛基大学|Jiaheng Lu,塞浦路斯科技大学|Herodotos Herodotou,杜克大学|Shivnath Babu
专知会员服务
6+阅读 · 2019年8月28日
参考链接
父主题
大数据处理
数据批处理框架
子主题
MapReduce
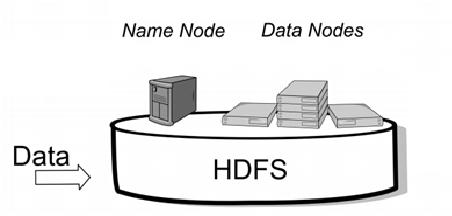
HDFS
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top