赛尔笔记|多模态情感分析语料库调研
作者:哈工大SCIR 杨浩、彭湃、张震宇
1. 介绍
2. 相关任务概述
表1 多模态情感分析相关数据集和方法概览
模态 |
任务 |
数据集及下载地址 |
方法 |
|||
声图文 |
面向视频评论的情感分析 |
Youtube数据集 |
MOSI数据集 |
MOSEI数据集 |
Self-MM[5] |
Mult[4] |
https://projects.ict.usc.eduyoutube |
https://github.com/A2Zadeh/CMU-MultimodalSDK |
https://github.com/A2Zadeh/CMU-MultimodalSDK |
||||
声图文 |
面向视频评论的细粒度情感分析 |
CH-SIMS数据集 |
MTFN[6][7] |
|||
https://github.com/thuiar/MMSA |
||||||
声图文 |
面向视频对话的情绪分析 |
IEMOCAP数据集 |
MELD数据集 |
DialogueRNN[11] |
MESM[12] |
|
https://sail.usc.edu/iemocap/ |
https://affective-meld.github.io |
|||||
声图文 |
面向视频的反讽识别 |
MUStARD数据集 |
Early Fusion +SVM[13] |
|||
https://github.com/soujanyaporia/MUStARD |
||||||
图文 |
面向图文的反讽识别 |
Twitter反讽数据集 |
D&R net[20] |
|||
https://github.com/headacheboy/data-of-multimodal-sarcasm-detection |
||||||
图文 |
面向图文的情感分析 |
Yelp数据集 |
MVSA数据集 |
|||
https://www.yelp.com/dataset |
http://mcrlab.net/research/mvsa-sentiment-analysis-on-multi-view-social-data/ |
|||||
图文 |
面向图文的细粒度情感分析 |
Multi-ZOL数据集 |
Twitter-15&17数据集 |
TomBert[22] |
||
https://github.com/xunan0812/MIMN |
https://github.com/jefferyYu/TomBERT |
|||||
声图文 |
幽默检测 |
UR-FUNNY数据集 |
C-MFN[18] |
|||
https://github.com/ROC-HCI/UR-FUNNY |
||||||
声图文 |
抑郁检测 |
DAIC-WOZ数据集 |
||||
https://dcapswoz.ict.usc.edu |
||||||
图文 |
抑郁检测 |
Twitter抑郁检测数据集 |
MDL[17] |
|||
https://depressiondetection.droppages.com |
||||||
3.1 面向视频评论的情感分析
数据集
方法
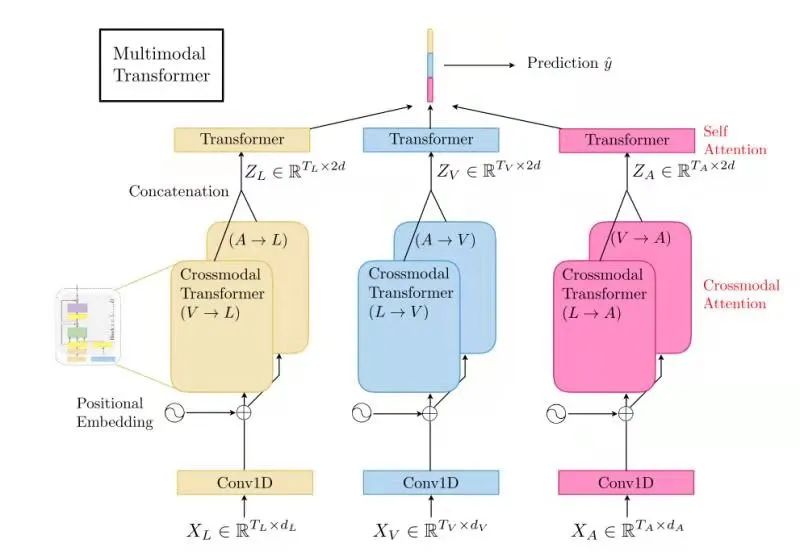
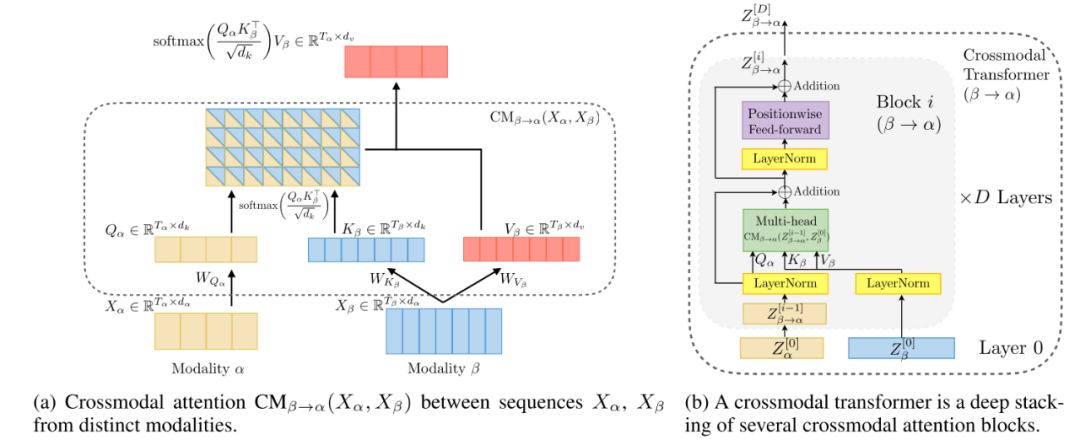
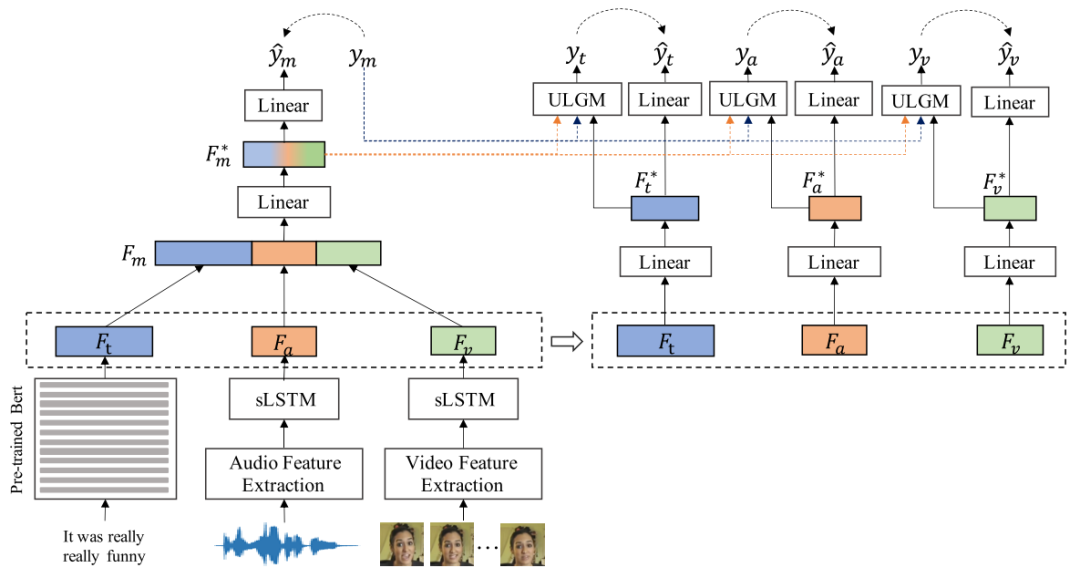
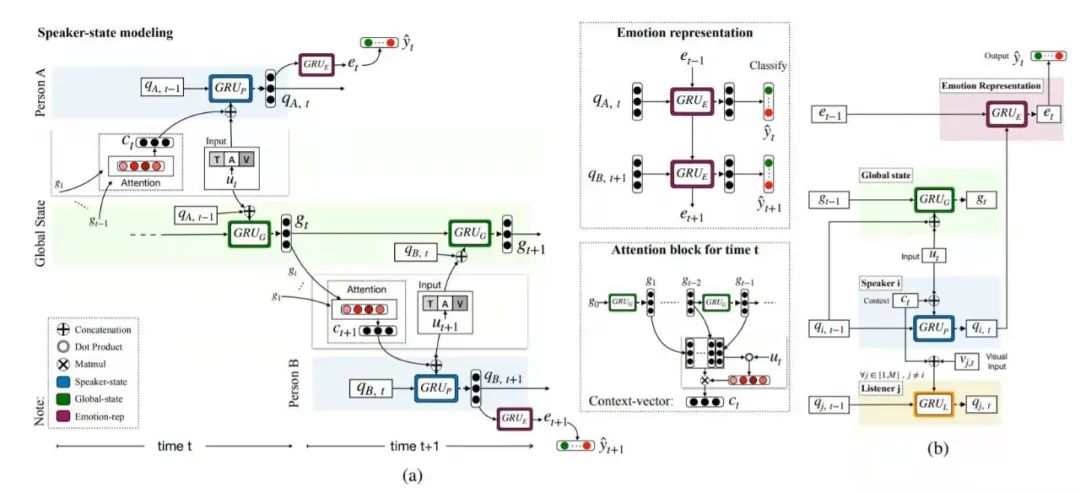
3.2 面向视频的对话情绪分析
数据集
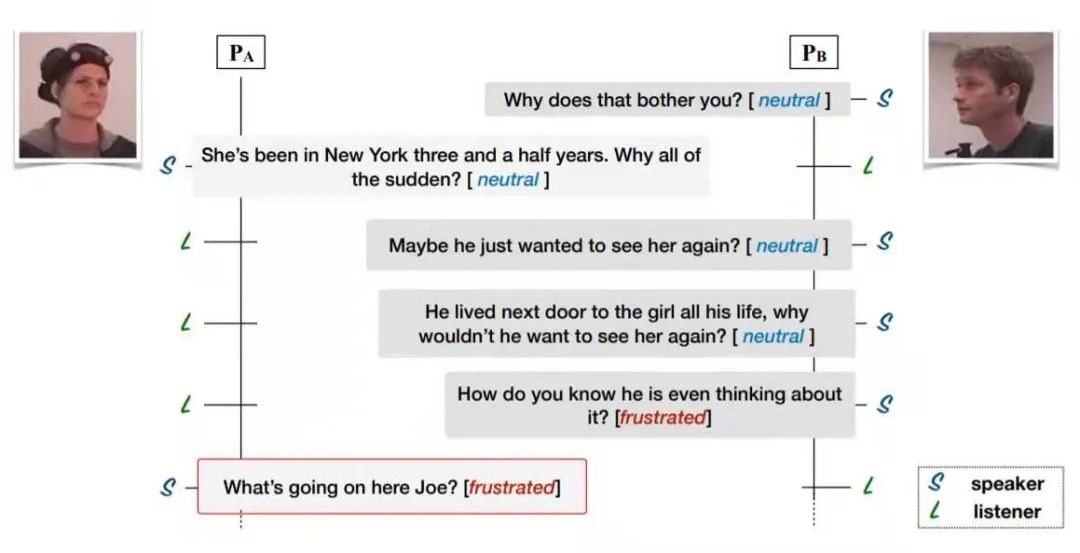
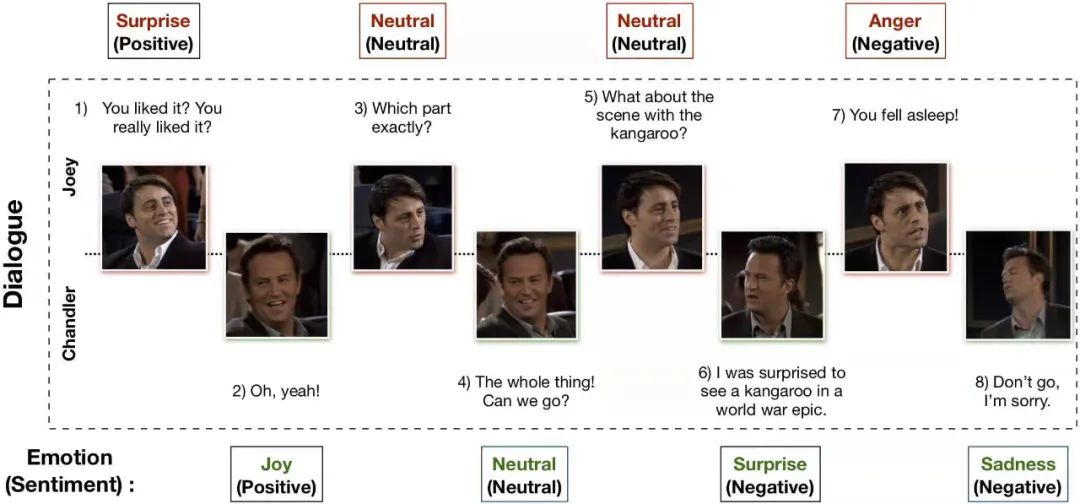
方法
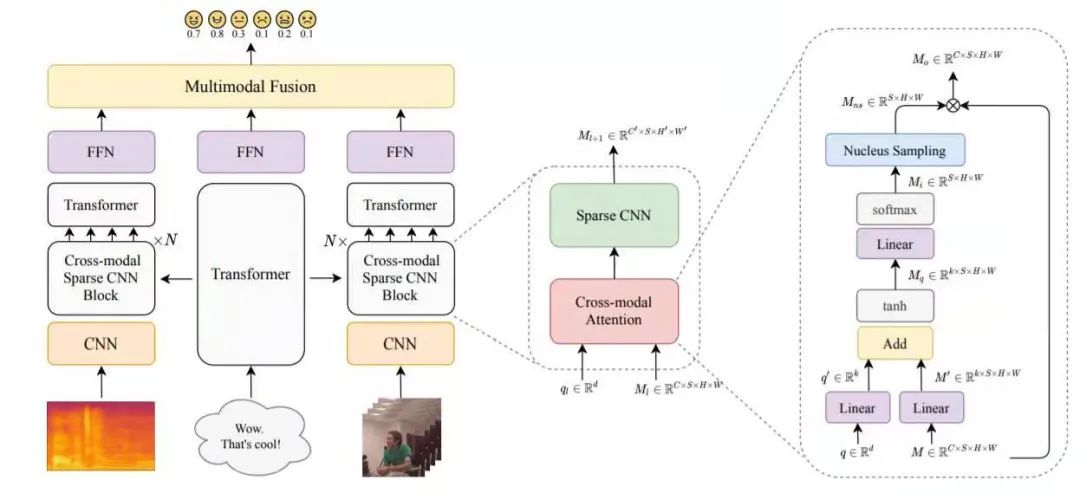
3.3 面向视频的细粒度情感分析
数据集
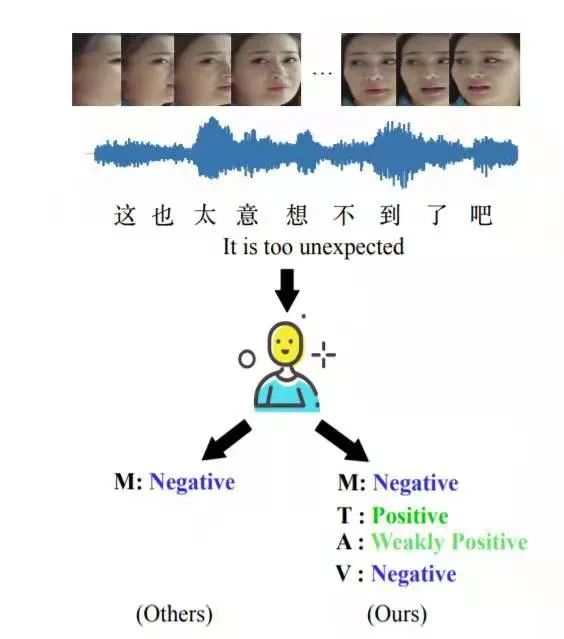
方法
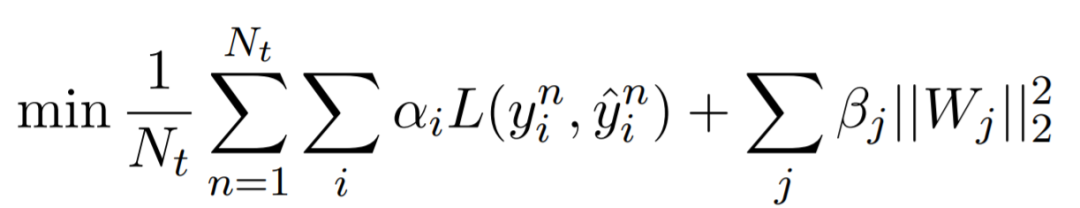
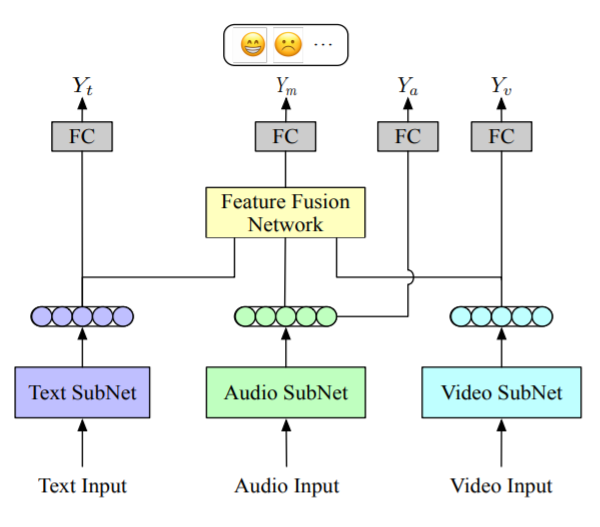
3.4 面向视频的反讽识别
数据集

方法

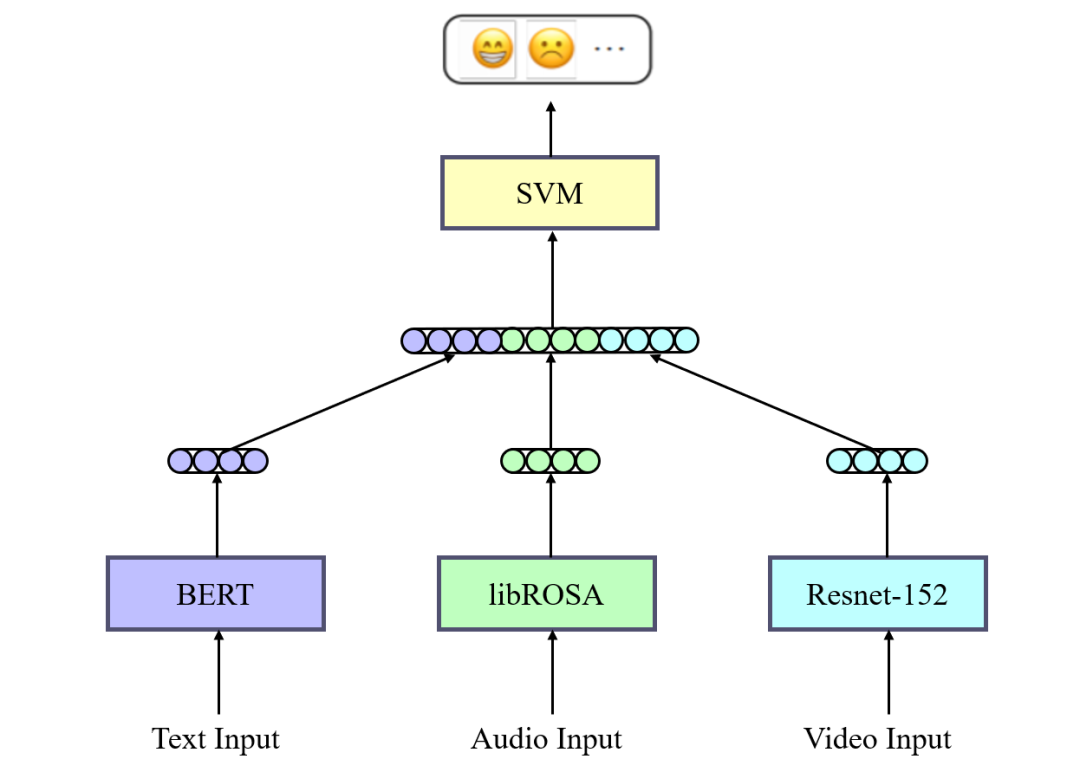
3.5 面向图文的反讽识别
数据集
方法
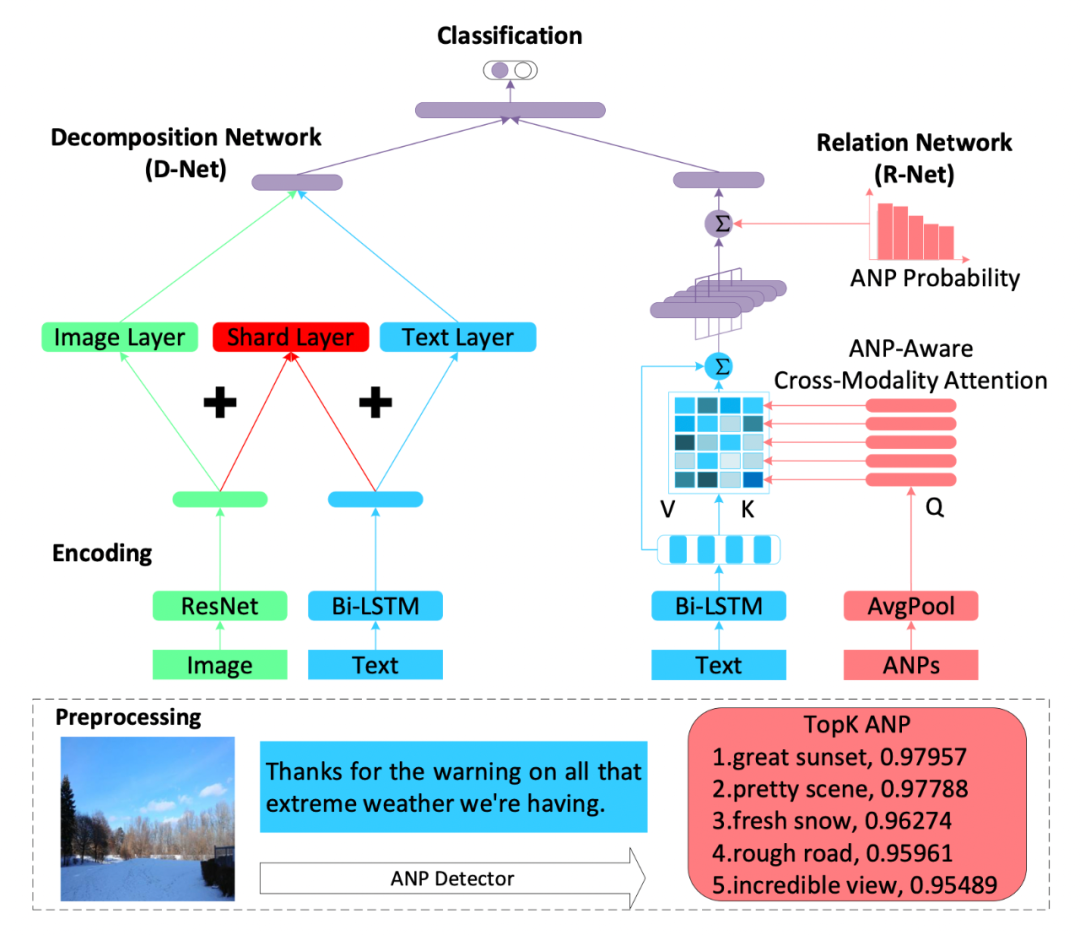
3.6 面向图文的情感分析
数据集
3.7 面向图文的细粒度情感分析
数据集
方法
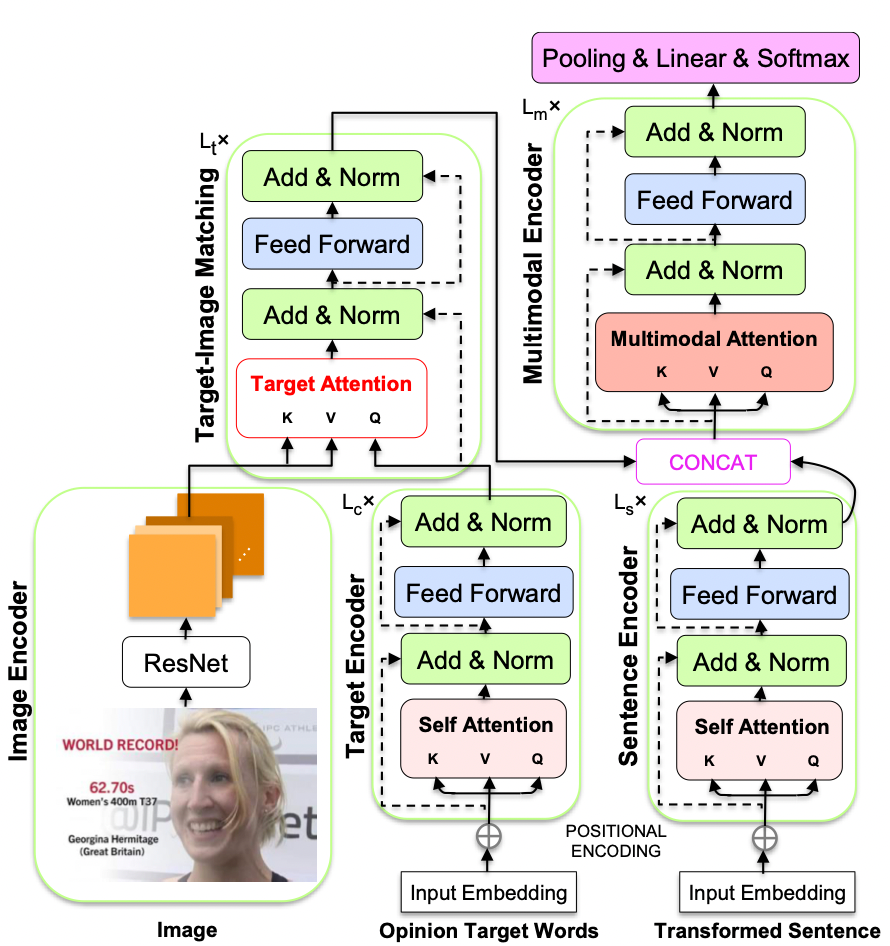
3.8 幽默检测
数据集
方法
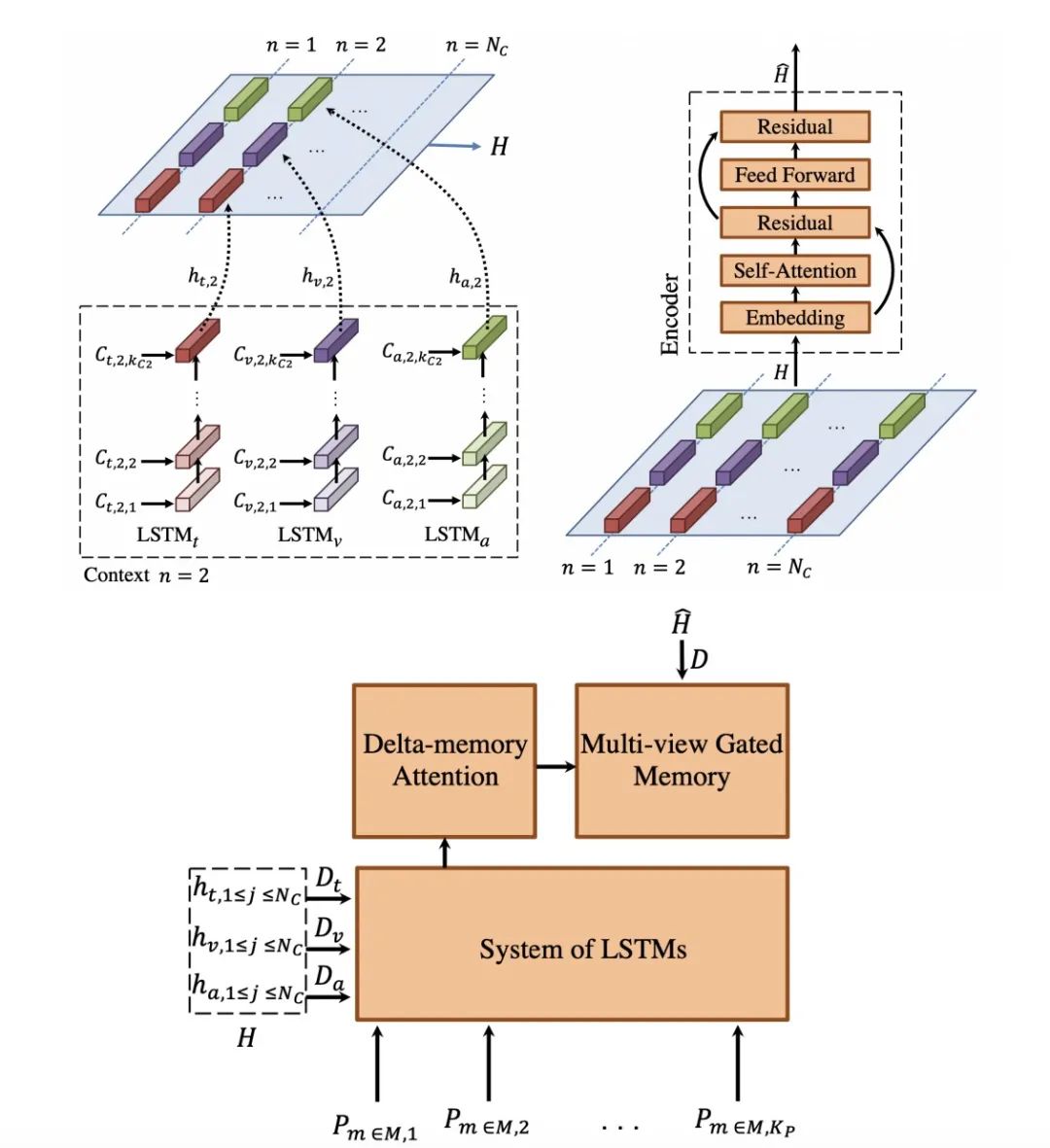
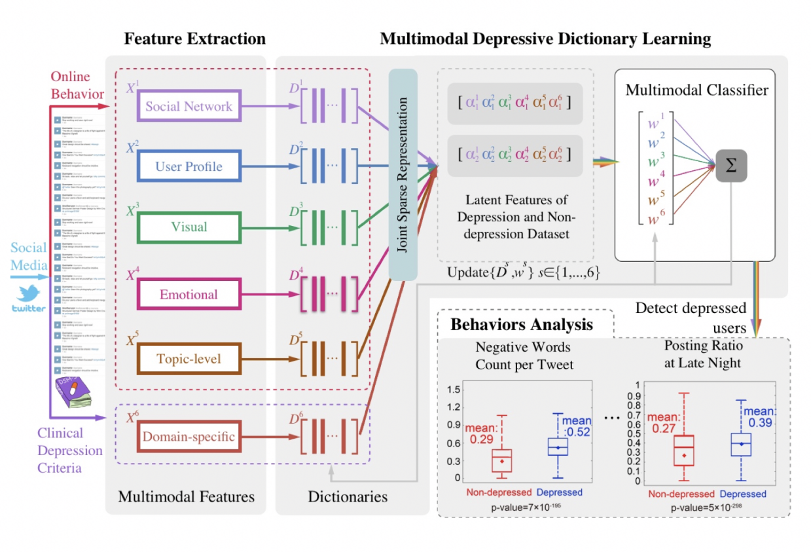
3.9 抑郁检测
数据集
方法
4. 总结
参考文献
本期责任编辑:丁 效
理解语言,认知社会
以中文技术,助民族复兴



