大会 | 年度最有价值研究,CVPR 2017六篇获奖论文介绍(附打包下载)| CVPR 2017
AI 科技评论按:CVPR 2017的获奖论文已经在大会的第一天中公布,共有6篇论文获得四项荣誉。AI 科技评论对6篇获奖论文作简要介绍如下。
CVPR最佳论文
本届CVPR共有两篇最佳论文,其中就有一篇来自苹果。
「Densely Connected Convolutional Networks」
论文作者:康奈尔大学 Gao Huang,清华大学 Zhuang Liu,康奈尔大学 Kilian Q. Weinberger,Facebook 人工智能研究院 Laurens van der Maaten
论文地址:https://arxiv.org/abs/1608.06993
论文简介:近期的研究已经展现这样一种趋势,如果卷积网络中离输入更近或者离输出更近的层之间的连接更短,网络就基本上可以更深、更准确,训练时也更高效。这篇论文就对这种趋势进行了深入的研究,并提出了密集卷积网络(DenseNet),其中的每一层都和它之后的每一层做前馈连接。对于以往的卷积神经网络,网络中的每一层都和其后的层连接,L层的网络中就具有L个连接;而在DenseNet中,直接连接的总数则是L(L+1)/2个。对每一层来说,它之前的所有的层的 feature-map 都作为了它的输入,然后它自己的 feature-map 则会作为所有它之后的层的输入。
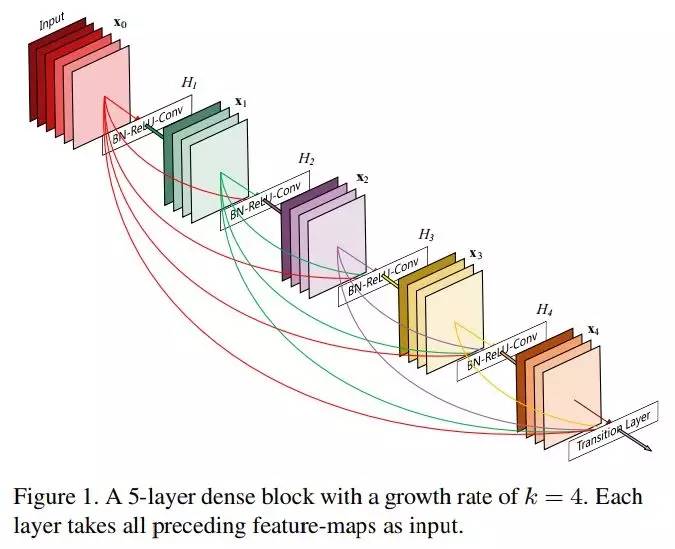
DenseNet 类型的网络有这样几个引人注目的优点:它们可以缓和梯度消失的问题,可以加强特征传播,可以鼓励特征的重用,而且显著减少参数的数量。论文中在 CIFAR-10、CIFAR-100、SVHN、ImageNet 这四个高竞争性的物体识别任务中进行了 benchmark,DenseNet 在多数测试中都相比目前的顶尖水平取得了显著提升,同时需要的内存和计算力还更少。
「Learning From Simulated and Unsupervised Images through Adversarial Training」
论文作者:苹果公司 Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb
论文地址:https://arxiv.org/abs/1612.07828
论文简介:随着图像领域的进步,用生成的图像训练机器学习模型的可行性越来越高,大有避免人工标注真实图像的潜力。但是,由于生成的图像和真实图像的分布有所区别,用生成的图像训练的模型可能没有用真实图像训练的表现那么好。为了缩小这种差距,论文中提出了一种模拟+无监督的学习方式,其中的任务就是学习到一个模型,它能够用无标注的真实数据提高模拟器生成的图片的真实性,同时还能够保留模拟器生成的图片的标注信息。论文中构建了一个类似于 GANs 的对抗性网络来进行这种模拟+无监督学习,只不过论文中网络的输入是图像而不是随机向量。为了保留标注信息、避免图像瑕疵、稳定训练过程,论文中对标准 GAN 算法进行了几个关键的修改,分别对应“自我正则化”项、局部对抗性失真损失、用过往的美化后图像更新鉴别器。
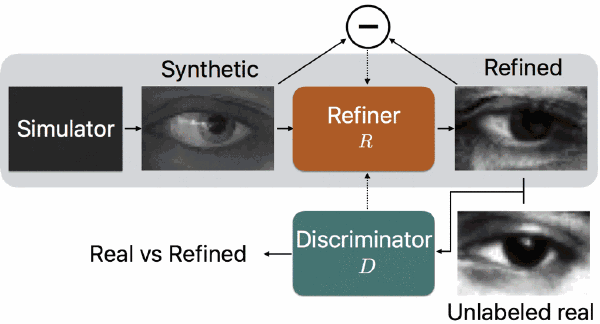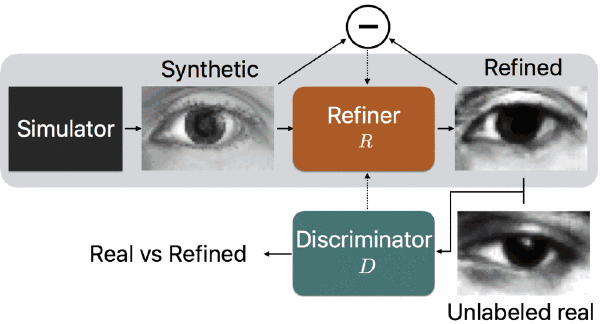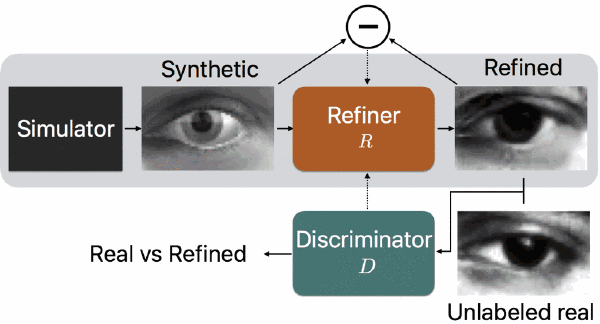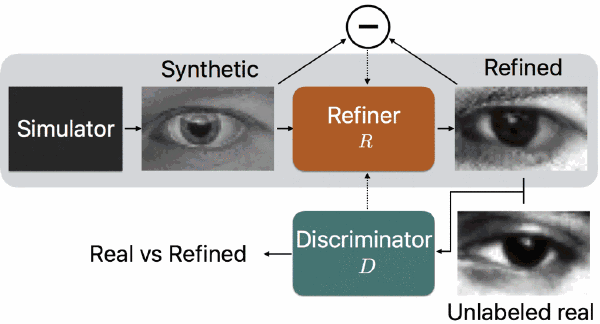
论文中表明这些措施可以让网络生成逼真的图像,并用定性的方法和用户实验的方法进行了演示;定量测试则是用生成的数据训练模型估计目光注视方向、估计手部姿态。结果表明,经过模型美化后的生成图像可以为模型表现带来显著提升,在 MGIIGaze 数据集中不依靠任何有标注的真实数据就可以取得超过以往的表现。
论文详解:上周时候苹果开放了自己的机器学习博客“苹果机器学习日记”,其中第一篇就是对这篇获奖论文的详解,AI 科技评论编译文章在这里,欢迎感兴趣的读者详细了解。
CVPR最佳论文提名
「Annotating Object Instance with a Polygon-RNN」
论文作者:多伦多大学计算机学院Llu´ıs Castrejon,Kaustav Kundu,Raquel Urtasun,Sanja Fidler
论文地址:https://arxiv.org/abs/1704.05548
论文简介:论文中介绍了一种半自动的物体标注方法。这套系统的思路是,不再像以往一样把图像中的物体分割作为一种像素标注问题,把它看作一个多边形位置预测问题,从而模仿目前已有的标注数据集的方式生成检测标注框。具体来讲,论文中的方法在输入图像后可以依次生成多边形的边把图像中的物体围起来。这个过程中,人类标注员可以随时参与并纠正错误的顶点,从而得到人类标注员眼中尽可能准确的分割。

根据论文中的测试,他们的方法可以在 Cityscapes 的所有类别中把标注速度提升至4.7倍,同时还可与原本真值的重合度 IoU 达到78.4%,与人类标注者之间的典型重合率相符。对于车辆图像,标注速度可以提升至7.3倍,重合度达到82.2%。论文中也研究了这种方法对于从未见过的数据集的泛化能力。
「YOLO9000: Better, Faster, Stronger」
论文作者:华盛顿大学,Allen 人工智能学院的 Joseph Redmon 与 Ali Farhadi
论文地址:https://arxiv.org/abs/1612.08242
论文简介:论文中介绍了名为“YOLO9000”的顶级水平的实时物体检测系统,它可以检测的物体种类达到了9000种。论文中首先介绍了对原始的 YOLO 系统的多方面提升,有些是论文中新提出的方法,有些是从之前别人的成果中借鉴的。提升后的 YOLOv2 模型在 PASCAL VOC 和 COCO 这样标准的物体检测任务中有顶级的表现。在使用一个新的、多尺度训练方法之后,这个 YOLOv2 模型可以处理各种不同的图像,从而在速度和准确性之间轻松地取得了平衡。在67FPS下,YOLOv2 可以在 VOC 2007中取得76.8mAP;在40FPS下,分数可以提升为78.6mAP。这样的准确率不仅超越了目前最好的带有 ResNet 和 SSD 的 Faster R-CNN,而且运行速度还明显更快。论文中最后还提出了一种将物体检测和物体分类合并训练的方法,论文作者们借助这种方法,同时运用物体检测数据集 COCO 和物体分类数据集 ImageNet 训练得到了 YOLO9000。有的物体类别并没有对应的物体检测数据,而合并训练的方法让 YOLO9000 遇到它们的也时候也能够预测检测结果。
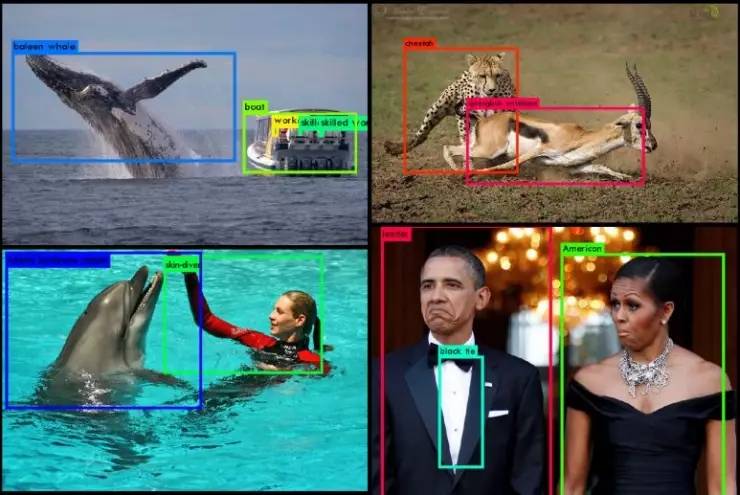
为了验证方法的效果,论文中进行了物体检测的验证测试,YOLO9000 只用了200个类别中44个类别的检测数据,就在 ImageNet 的检测验证数据集中取得了 19.7mAP;对于 COCO 中没有的156个类别,YOLO9000得到了16.0mAP。不过YOLO9000能够检测的类别远不只这200个类,它可以预测超过9000个不同类别物体的检测结果,而且仍然可以实时运行。
最佳学生论文奖
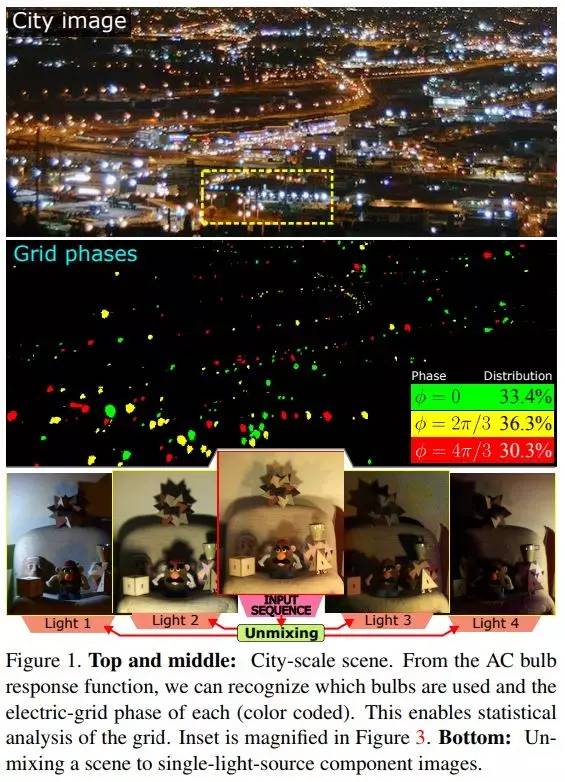
「Computational Imaging on the Electric Grid」
论文作者:以色列理工学院电气工程学院 Mark Sheinin、Yoav Y. Schechner,多伦多大学计算机学院 Kiriakos N. Kutulakos
论文地址:http://openaccess.thecvf.com/content_cvpr_2017/papers/Sheinin_Computational_Imaging_on_CVPR_2017_paper.pdf
论文简介:夜晚的风景随着交流电照明一起跳动。通过被动方式感知这种跳动,论文中用一种新的方式揭示了夜景中的另一番画面:夜景中灯泡的类型是哪些、上至城市规模的供电区域相位如何,以及光的传输矩阵。为了提取这些信息需要先消除灯光的反射和半反射,对夜景做高动态范围处理,然后对图像采集中未观察到的灯泡做场景渲染。最后提到的这个场景渲染是由一个包含各种来源的灯泡响应函数数据库支持的,论文中进行了收集并可以提供给读者。并且论文中还构建了一个新型的软件曝光高动态范围成像技术,专门用于供电区域的交流电照明。
Longuet-Higgins 奖
Longuet-Higgins 奖以英国著名理论化学家、认知科学家 H. Christopher Longuet-Higgins 的名字命名。该奖设立于 2005 年,用以奖励对 CV 研究产生根本性影响的学术论文,专门用来奖励十年以前在 CVPR 发表、“经得起时间考验”产生广泛影响的论文。它是世界上第一个针对过往论文的奖项。这个奖项是由 IEEE 计算机协会的“模式分析和机器智能技术委员会”TCPAMI 评选的。
在颁布该奖项时还有一个有意思的花絮——主持人介绍说,设立这样一个奖项的初衷,是因为“大家都知道,许多对学界贡献很大、影响力也很大的论文,在当年并不是最佳论文。”
「Object retrieval with large vocabularies and fast spatial matching」
论文作者:牛津大学科学工程学院James Philbin、Ondˇrej Chum、Josef Sivic、Andrew Zisserman,微软硅谷研究院 Michael Isard
论文地址:https://pdfs.semanticscholar.org/943d/793f6cbbc6551d758c1eefca2a9333bd8921.pdf
论文简介:这篇论文介绍了一个大规模的物体图像搜寻系统。系统把用户在一副图片中框选的区域作为查询输入,然后就可以返回一个有序列表,其中都是从指定的大数据集中找到的含有同一个物体的图像。论文中用从 Flickr 上爬超下来的超过100万张图像组成一个数据集,用牛津大学的地标作为查询输入,展示了系统的可拓展性和查询性能。

由于数据集规模的原因,实验过程中给图像特征构建列表的过程是时间和性能的主要瓶颈。基于这个问题,论文中对比了不同规模拓展的方法在构建特征列表方面的表现,并且介绍了一种全新的基于随机树的量化方法,这种方法在广泛的真值中都具有最好的表现。论文中的实验表明这种量化方法对搜索结果质量的提高也有重要作用。为了进一步提升搜索性能,系统中还增加了一个高效的空间验证阶段来对论文中构建的这种基于特征列表的方法进行重新标识,结果表明它可以稳定地提高搜索质量,虽然当特征列表很大的时候效果并不显著。作者们觉得这篇论文是通往更多图片、互联网规模的图像语料库的前途光明的一步。
六篇论文打包下载如下链接: http://pan.baidu.com/s/1dFgq4d7 密码: 3t73
更多 CVPR 后续报道、更多近期学术会议现场报道,请继续关注 AI 科技评论。