Impala在网易大数据的优化和实践


文章作者:温正湖 网易杭研
编辑整理:张博
出品平台:DataFunTalk
Impala有哪些优势,让我们选择Impala作为网易内部的OLAP查询引擎?
1. Impala在数据处理中的角色
先来看一下Impala在数据处理中的角色。
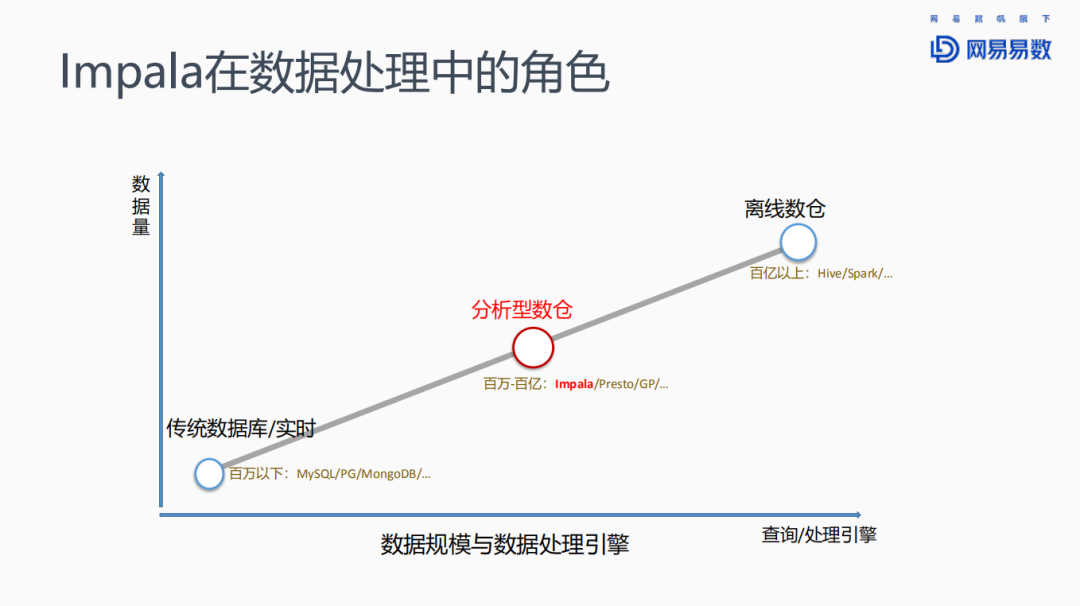
对于数据量较少的场景,例如百万数据以下的情况,可以采用传统的关系型数据库,如MySQL或者PostgreSQL等,或者一些文档数据库,比如MongoDB等。随着数据量的增大,达到上亿级别时,一般选择分析型数仓来存储,并使用OLAP引擎来查询。此等规模的数据查询,对响应时间的要求虽然比关系型数据库要低,但一般也要求在秒级返回查询结果,不能有太大的延迟。Impala、Presto、Greenplum等都在此列。当规模继续扩大到上百亿以上时,则会选择批处理引擎,如Hive、Spark来进行数据处理。
今天分享的Impala就是针对分析型数仓的查询引擎。分析型数仓有很多种建模方式。
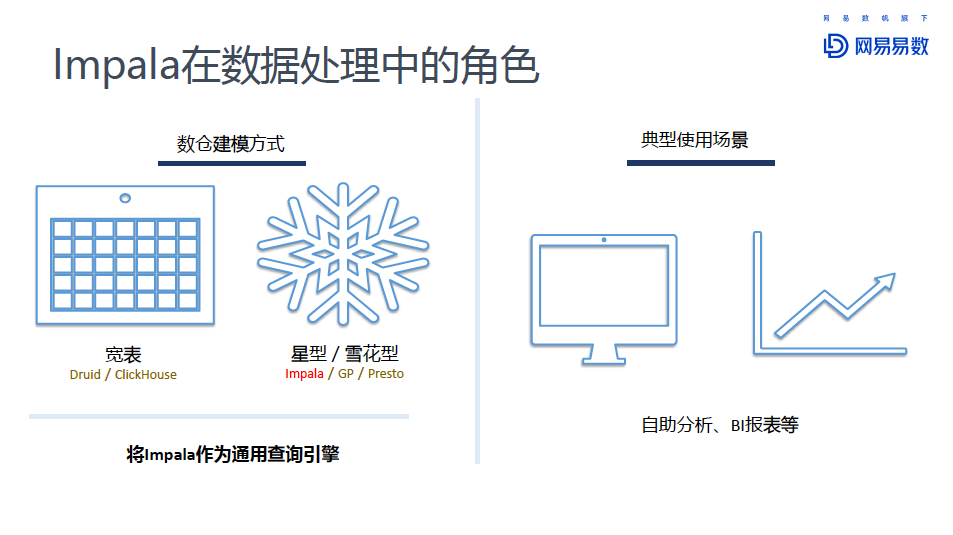
以Druid和Click House为代表的宽表模型,还有以Impala等为代表的星型/雪花型的建模方式。我们将Impala作为通用的查询引擎,比较典型的应用场景有自助数据分析、BI报表等。在分享的第三部分,有关于Impala在网易大数据平台“猛犸”中的介绍,以及在网易云音乐中的实际使用场景的说明。
2. Impala的优势
网易为什么选择Impala作为OLAP查询引擎,Impala到底有哪些优势?Impala的优势,总结起来包括:
MPP 架构,去中心化
优秀的查询性能
友好的 WebUI 界面
完全兼容 Hive 元数据
Apache 顶级项目,社区活跃度高
支持多种数据格式( Parquet/ORC 等)
与 Kudu 结合使用,实时数仓
① 去中心化的MPP并行架构
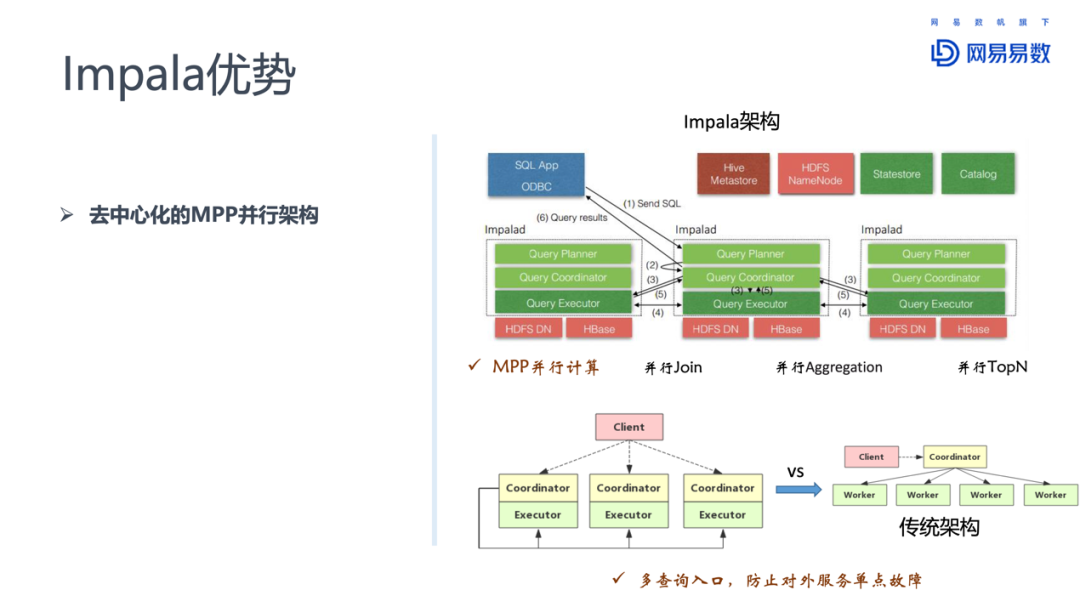
相比于传统的关系型数据库,MPP架构可以充分发挥多服务器的特点,将数据量比较大的操作,分散在多台服务器上并行处理。这些复杂的大数据量的操作,对于单台服务器来说是无法完成的任务。
Impala还区别于其他MPP架构的引擎的一点,是Impala有多个Coordinator和Executor,多个Coordinator可以同时对外提供服务。多Coordinator的架构设计让Impala可以有效防范单点故障的出现。
② 优秀的查询性能
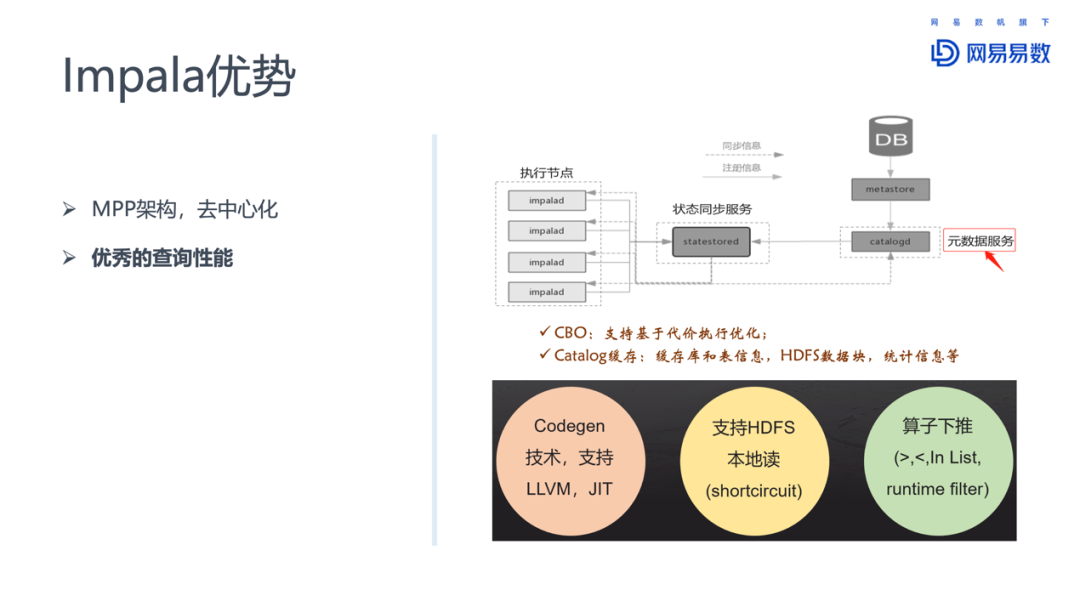
Impala支持CBO(基于代价的执行优化),除此之外,Impala还对Catalog进行了缓存。缓存的信息包括:库和表的信息、HDFS数据库、统计信息等。元数据都缓存在了Impala内部,在做CBO时,能够发挥更大的优势,做出更优的选择。除此之外,Impala同时具有典型的OLAP引擎应有的特征:静态代码生成支持LLVM、JIT;支持HDFS本地读区,减少访问NameNode、DataNode和数据网络传输的开销,对性能有比较大的提升;还有算子下推,runtime filter在Join时,对与join条件之外的列可以进行动态过滤。
从我们实际使用效果来说,Impala性能优势非常明显。前段时间我们对Impala、presto和spark3.0进行了对比测试。测试用例选择tpcds,并行节点8个。
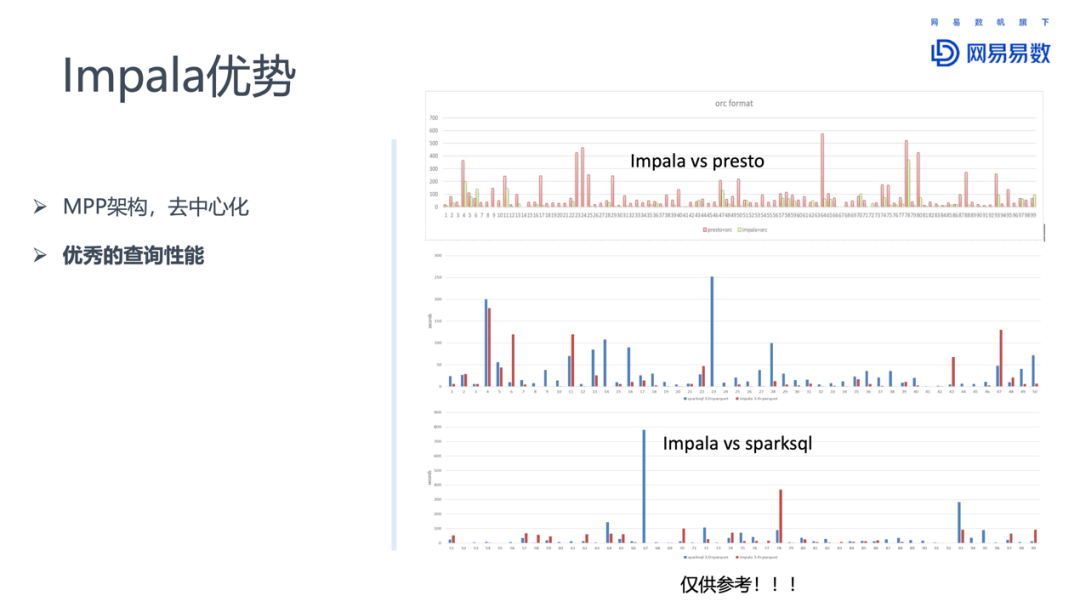
总的来说,Impala相比Presto有明显的优势,相比Spark 3.0也有一定的优势。Spark 3.0对性能做了很多优化和改进,相比之下Impala性能有一些优势,不过Impala因为支持的SQL类型少一些,有一些tpcds的测试用例并不能完成。
③ 友好的WebUI界面

一般来说,大数据查询引擎的查询计划,比关系型数据库的查询计划复杂的多。Impala提供了一个比较友好的WebUI,在这个界面上,能看到完整的执行计划、内存使用情况、异常查询分析,也可以通过界面终止查询语句。
此外,Impala的优势还体现在:完全兼容Hive元数据、Apache顶级项目有较高的社区活跃度、支持多种数据格式(Parquet、ORC等)、可以与Kudu结合使用等。
在我们生产实践中,也发现了Impala的一些不足,因此网易大数据团队对Impala进行了一些优化和增强。包括以下几个方面:
Impala 管理服务器
元数据同步增强
基于zookeeper的服务高可用
支持更多存储后端
其他增强和优化
1. Impala管理服务器
Impala已经提供了WebUI的情况下,为什么需要一个管理服务器?
其中一个原因,是社区版的WebUI是非持久化的,一旦Impalad异常退出,这些信息都会丢失。
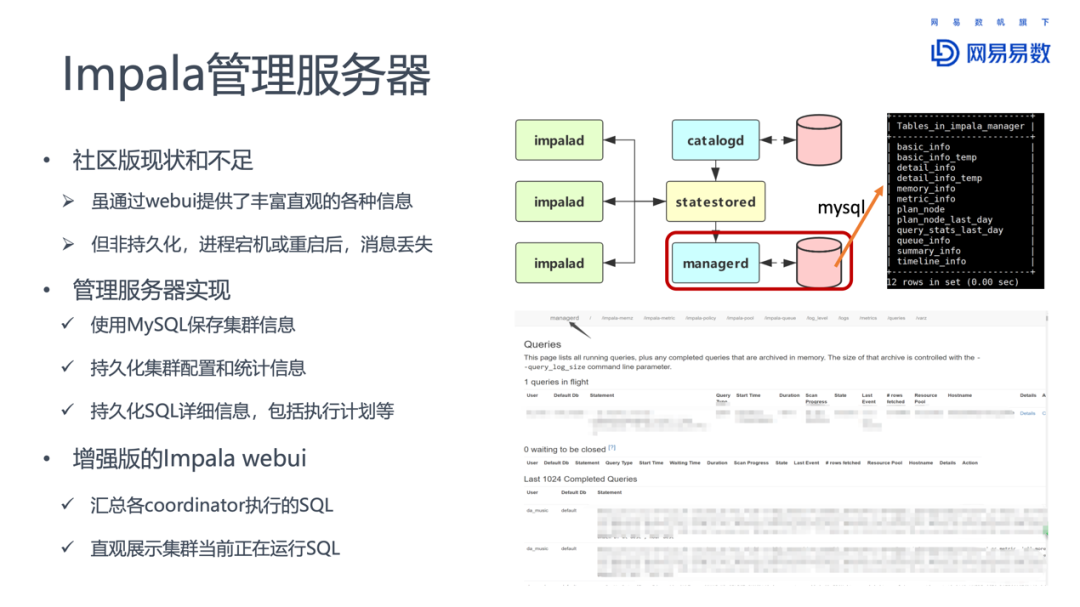
我们通过MySQL存储WebUI上的信息,将统计信息、执行信息等重要信息保存到MySQL数据库中,实现持久化保存。在此基础上,管理平台给我们带来许多增值收益。相比于原生的WebUI,增强版的WebUI可以汇总各个coordinator执行的SQL语句,直观展示当前执行的SQL。
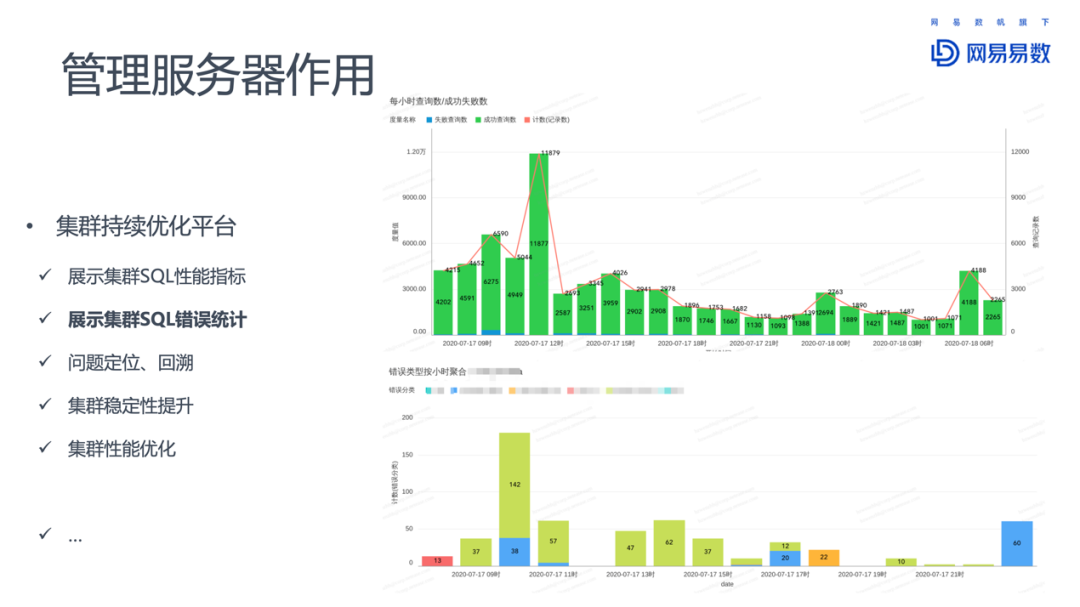
还可以作为集群持续优化的平台。因为记录了历史执行的SQL,可以为后续SQL优化提供依据,比如集群SQL的性能指标、随时间变化的性能表现,以及大部分SQL的执行时间。通过统计SQL执行失败的次数,出错SQL,为定位和回溯问题提供帮助。
2. 元数据同步增强
Impala对元数据的缓存,一方面大幅提升了查询性能,但另一方面,元数据更新也带来了新的问题。因为数据可以不通过Impala客户端,而通过其他组件比如Hive进行更新,这就让Impala无法感知到元数据的更新。而老旧的元数据会导致查询失败或者性能下降。因此,需要一个机制能够让Impala及时感知元数据的更新。社区版提供了INVALIDATE METADATA这一命令,可以手动刷新元数据。不过如果一些用户不熟悉这个操作,没有更新Impala缓存的元数据,就会导致查询的问题。怎么解决这样的问题?
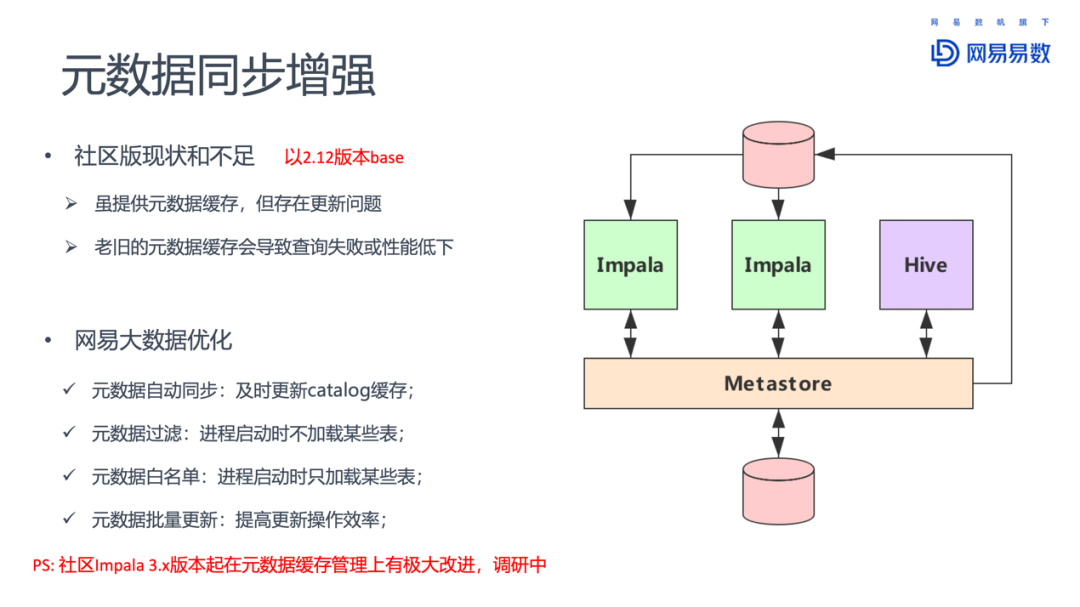
网易对此进行优化,引入了元数据自动同步机制:在Hive进行DDL相关操作时,记录操作日志,Impala通过消费操作日志,进行必要的Invalidate Metadata的操作,无须人工操作,大大提高了元数据缓存的可用性和实时性。对于提升Impala的查询性能,降低查询错误都有很大的帮助。
另外一个是元数据的黑白名单机制,配合Impala不同的元数据加载方式。对于启动时加载元数据的,配置黑名单,屏蔽不需要通过Impala查询的表;对于延迟加载元数据的,配置白名单,即刻加载元数据,避免首次查询时延迟过大。
另外需要提醒的是,Impala 3.x版本在元数据缓存管理上有了极大的改进,网易大数据团队也在调研中,准备从2.12升级到3.4版本。
3. 基于ZK的服务高可用
虽然每一个Impalad都可以作为Coordinator,对外提供访问服务,接受客户端请求,但是缺乏一个路由机制。当一个client连接的特定coordinator失效之后,就无法在进行查询了。
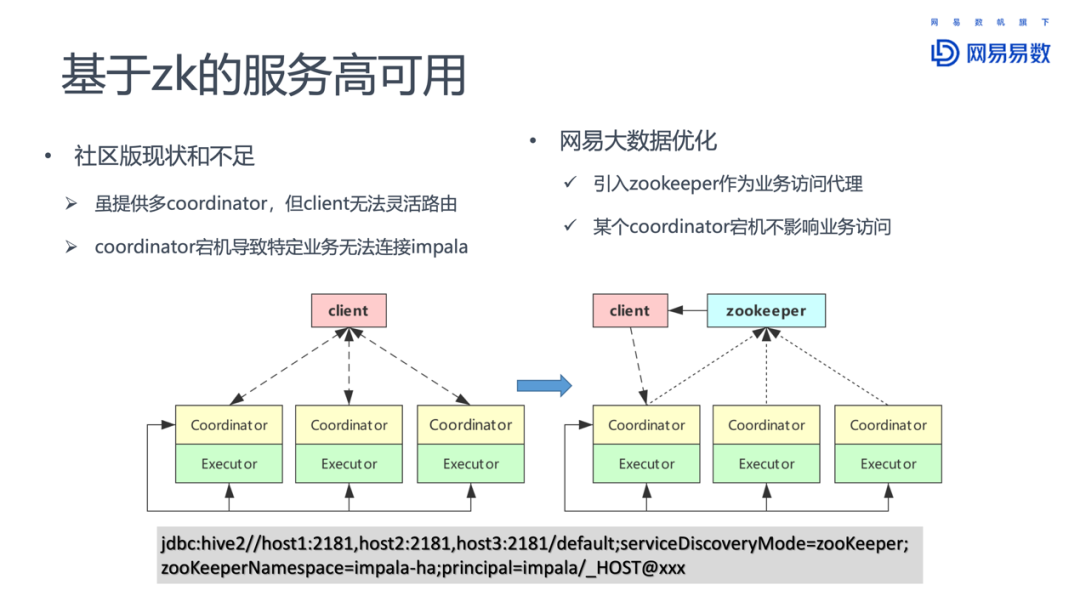
网易大数据团队参考Hive的实现,引入zookeeper作为访问代理,客户端首先通过zookeeper找到可用的coordinator节点,然后再提交SQL查询请求。通过这种方式,提供了更健壮的查询服务模式。
4. 支持更多存储后端
对于后端存储的支持,网易团队增加了对iceberg表的创建和查询的支持。已经在云音乐业务上使用,并且贡献给了Impala社区。
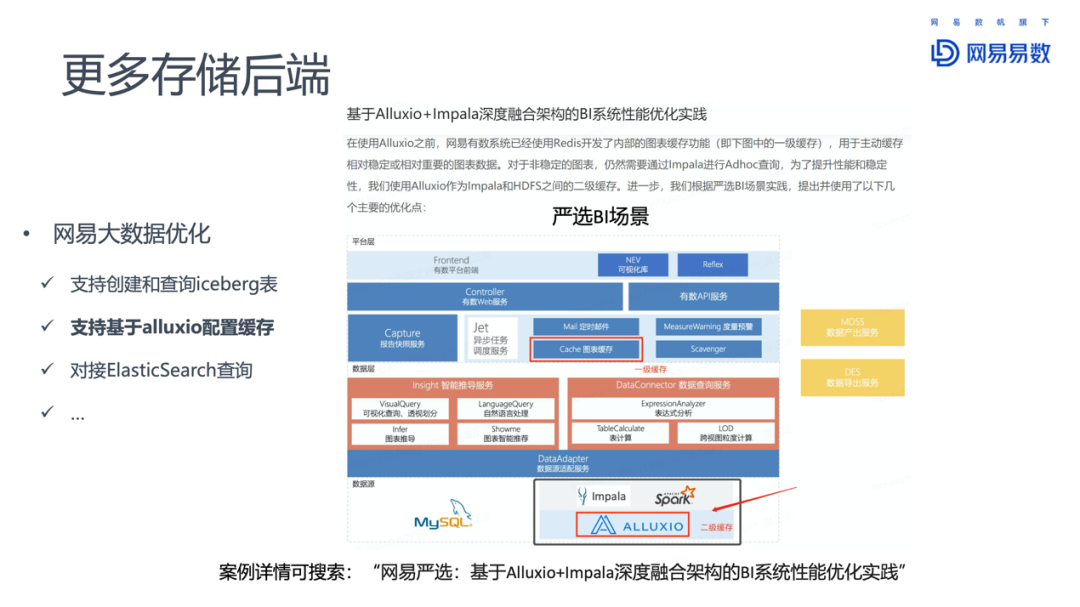
其他后端还包括对Alluxio的支持,使用Alluxio作为Impala和HDFS之间的二级缓存。这方面的详细信息,可以搜索《网易严选:基于 Alluxio+Impala 深度融合架构的 BI 系统性能优化实践》。
此外对接Elastic Search查询,充分发挥了ES倒排索引的优势。
5. 其他增强和优化

其他的增强还有:权限的优化、Hive多版本适配、支持JSON,以及社区版的一些Bug修正。
1. Impala的部署和使用
Impala两种部署方式:混合部署与独立部署。混合部署是指Impala和其他大数据组件共用HDFS。而独立部署则是为Impala配置独立的HDFS。独立部署的优势在于IO和网络通信都有保障,对性能和稳定性的提升有帮助。但是代价也十分明显:成本上升。
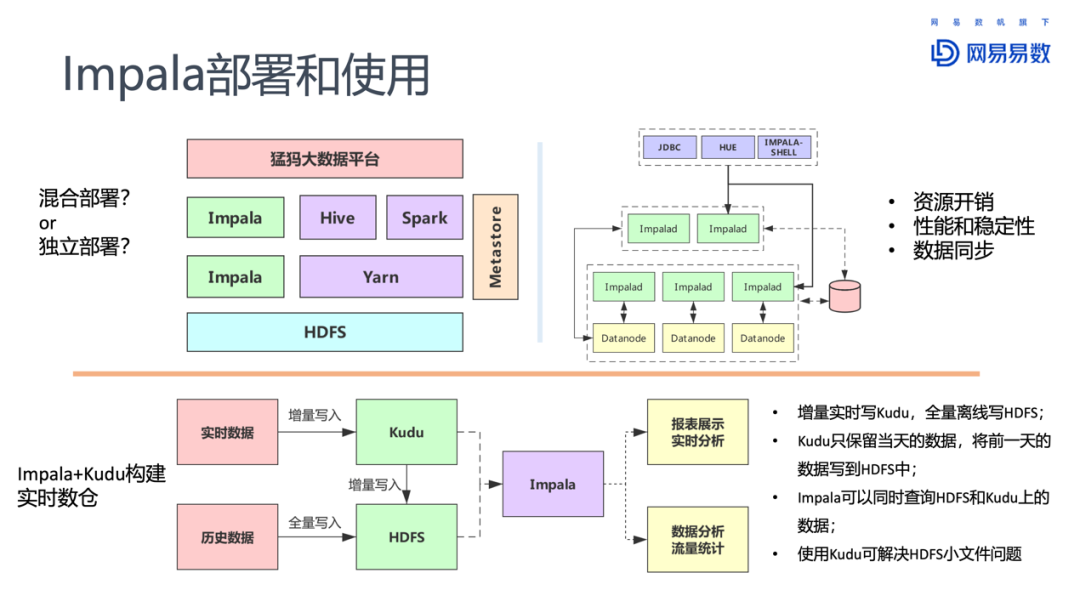
Impala与Kudu结合,可以用来构建实时数仓。Kudu增量写入,定期保存到HDFS。Kudu的使用一方面提供了更新数据和删除数据的能力,另一方面也解决了HDFS上小文件的问题。而Impala可以同时查询Kudu和HDFS上的数据。
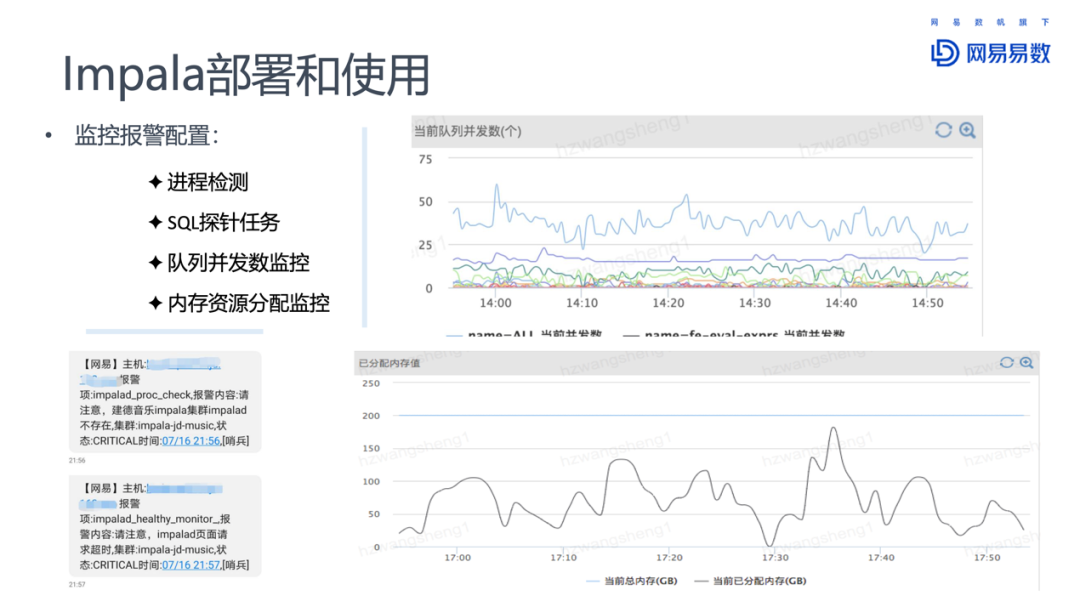
网易内部对集群的监控,对接了网易内部的哨兵服务。可以提供准实时的告警能力。运维人员通过设置阈值,订阅告警信息,从而了解集群的监控程度。
此外,对于Impala集群的部署和使用,还有几点需要注意:
按照大业务划分不同的集群
按照不同的子业务或者 SQL 类型划分队列
coordinator 节点与 executor 节点分开部署
对于机器数比较少的集群,机器上可部署多个节点,增加并发
业务方重试机制,以免 impalad 节点挂掉导致 SQL 失败
通过 impala hint 改变表的 join 方式
结合实际情况参考是否设置 mem_limit ,设置多大 mem_limit
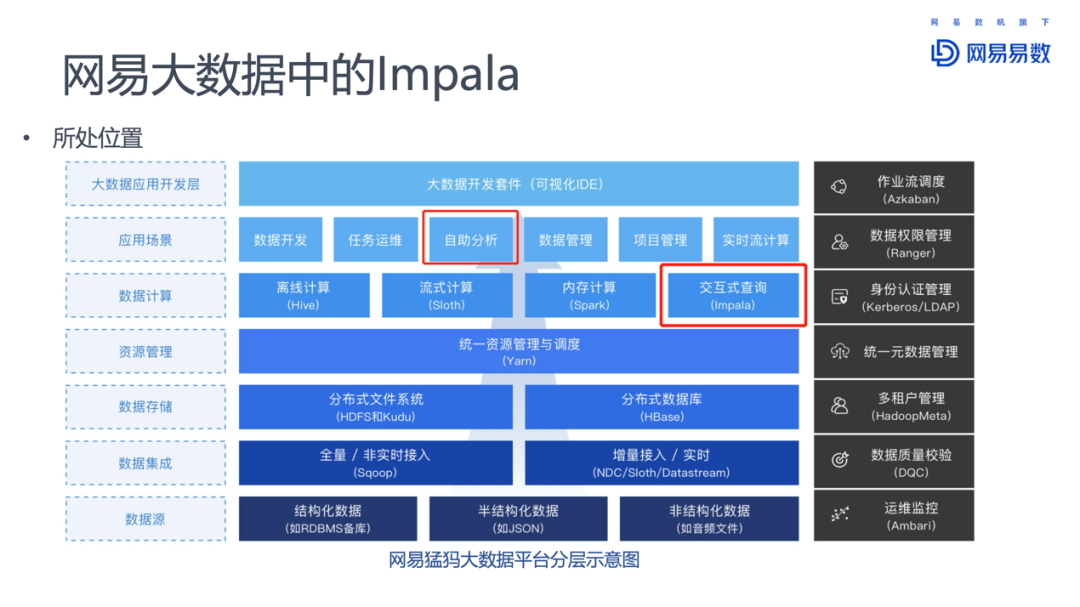
2. 网易大数据中的Impala
在网易大数据平台“猛犸”中,Impala位于数据计算层,提供交互式查询的能力,对应的应用场景是自助分析。
在网易对外提供的产品和服务中,复杂报表和自助取数,都用到了Impala。其中自助分析服务适用于有一定SQL基础的用户,通过自己写SQL语句,查询数据。灵活性比较大,同时门槛也比较高。
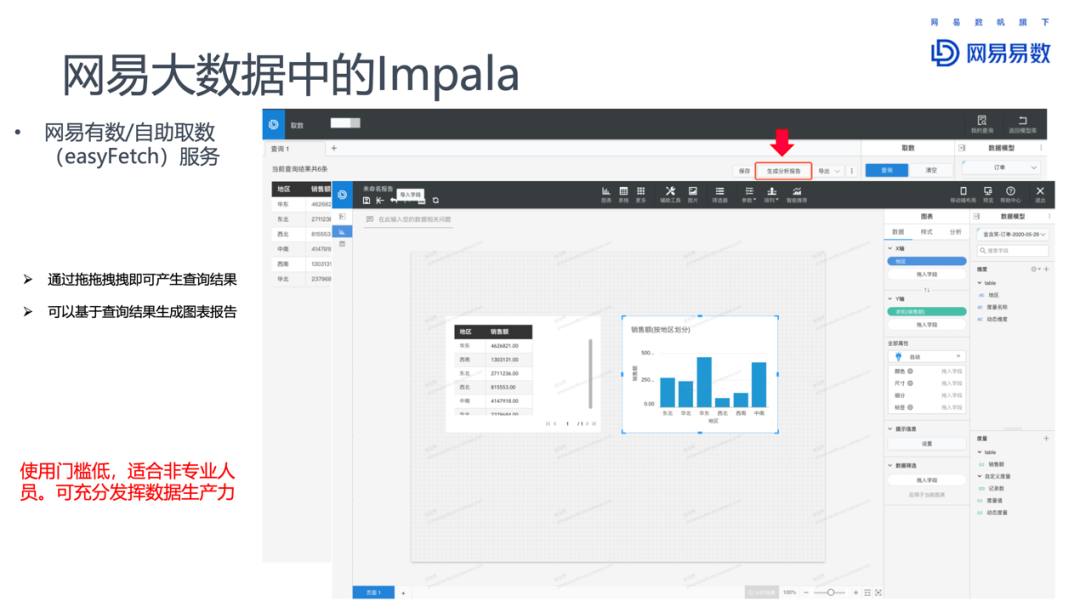
网易有数的自助取数服务(easyFetch)可以通过拖拽维度和度量,方便的获取数据,并生成图表报告。后端对接的是网易有数的API。非常适合非专业人员使用数据,发挥出数据的生产力。

网易现在内部有8个Impala集群,超过200个节点,最大集群规模超过60个节点。除了内部服务外,对外的商业化服务,已经有超过20个Impala集群。
3. Impala在云音乐的使用实践
网易云音乐,有2个Impala集群,超过60个节点的规模。主要的应用场景包括:有数报表、自助分析、音乐版权、A/B测试,easyFetch等等。绝大部分应用场景下,Impala的查询时间不超过2秒。
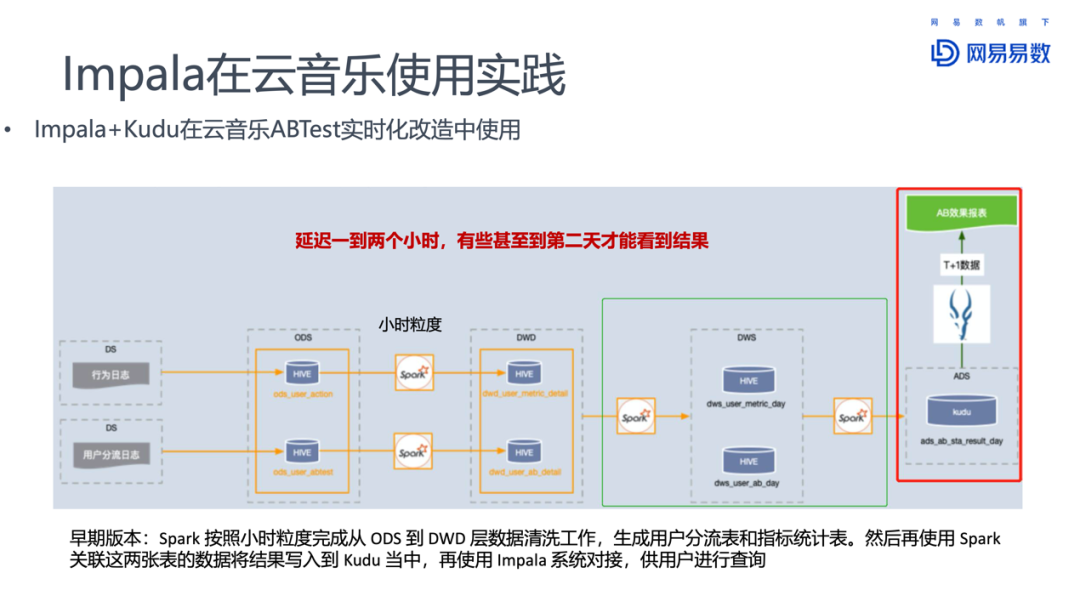
云音乐A/B测试早期使用Spark按照小时粒度,完成从ODS到DWD层的数据清洗工作,之后生成用户分流表和指标统计表,再使用Spark关联这两张表的结果写入到Kudu中,最后使用Impala对接数据,供用户查询。这样数据延迟至少1~2小时,有些结果甚至在第二天才能看到。但是对于A/B测试,能够实时看到结果才是最好的。
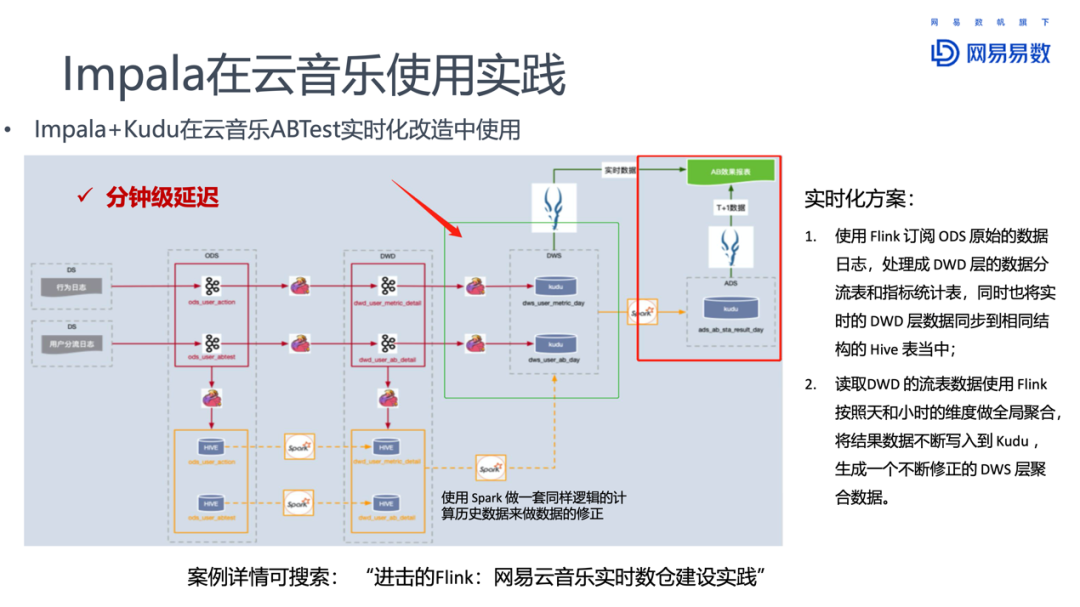
对此云音乐团队基于Flink做了实时性改造。将DWS变成流表,这样Impala可以同时查询T+1的结果表和流表中的实时数据。A/B测试的效果就可以近实时的看到了。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
嘉宾介绍:

温正湖
网易杭研 | 高级数据库技术专家
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇