RoBERTa中文预训练模型,你离中文任务的「SOTA」只差个它
机器之心报道
有了中文文本和实现模型后,我们还差个什么?还差了中文预训练语言模型提升效果呀。
24 层 RoBERTa 模型 (roberta_l24_zh),使用 30G 文件训练,9 月 8 日
12 层 RoBERTa 模型 (roberta_l12_zh),使用 30G 文件训练,9 月 8 日
6 层 RoBERTa 模型 (roberta_l6_zh),使用 30G 文件训练,9 月 8 日
PyTorch 版本的模型 (roberta_l6_zh_pytorch),9 月 8 日
30G 中文语料,预训练格式,可直接训练(bert、xlent、gpt2),9 月 8 日
测试集测试和效果对比,9 月 14 日

数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得 (见:Model Input Format and Next Sentence Prediction,DOC-SENTENCES);
更大更多样性的数据:使用 30G 中文训练,包含 3 亿个句子,100 亿个字 (即 token)。由于新闻、社区讨论、多个百科,保罗万象,覆盖数十万个主题;
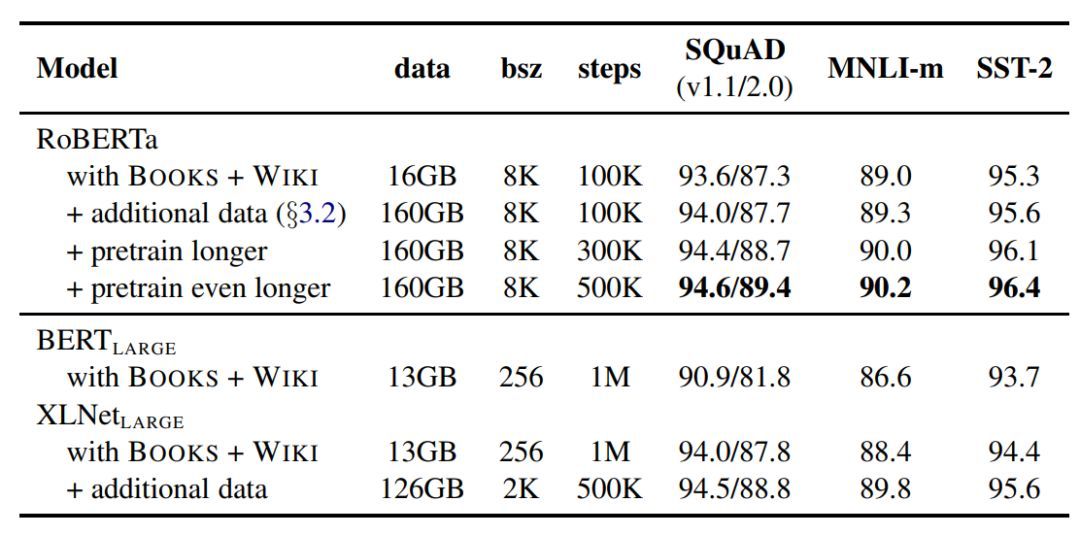
训练更久:总共训练了近 20 万,总共见过近 16 亿个训练数据 (instance); 在 Cloud TPU v3-256 上训练了 24 小时,相当于在 TPU v3-8(128G 显存) 上需要训练一个月;
更大批次:使用了超大(8k)的批次 batch size;
调整优化器参数;
使用全词 mask(whole word mask)。

更大的模型参数量(从 RoBERTa 论文提供的训练时间来看,模型使用 1024 块 V 100 GPU 训练了 1 天的时间)
更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本)