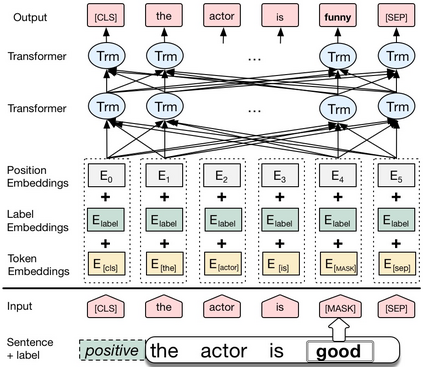
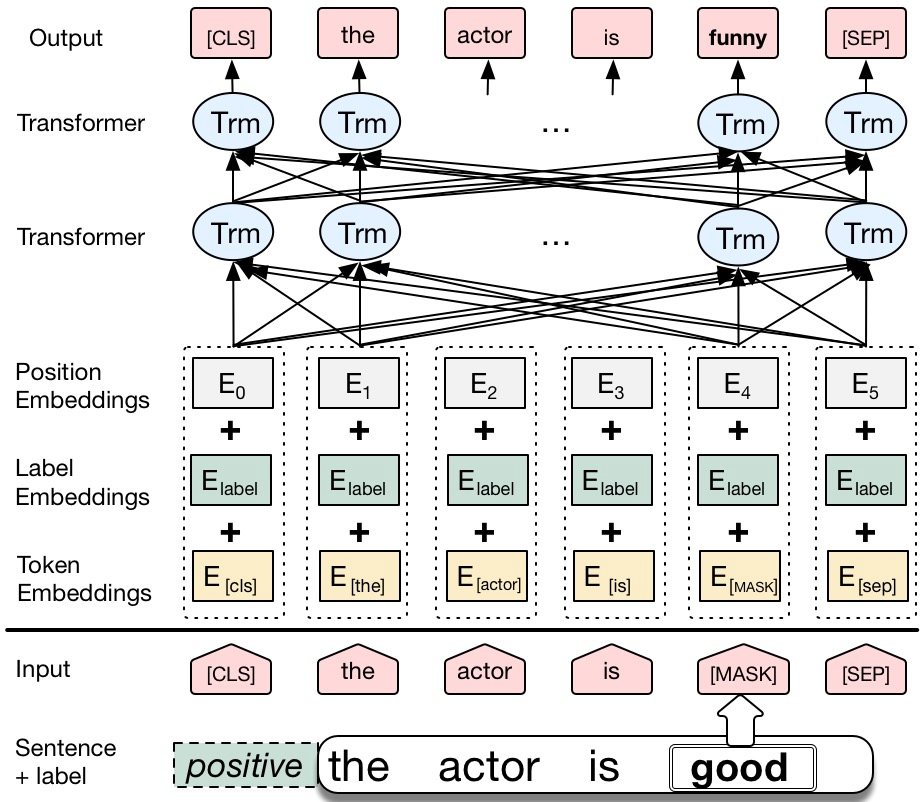
We propose a novel data augmentation method for labeled sentences called conditional BERT contextual augmentation. Data augmentation methods are often applied to prevent overfitting and improve generalization of deep neural network models. Recently proposed contextual augmentation augments labeled sentences by randomly replacing words with more varied substitutions predicted by language model. BERT demonstrates that a deep bidirectional language model is more powerful than either an unidirectional language model or the shallow concatenation of a forward and backward model. We retrofit BERT to conditional BERT by introducing a new conditional masked language model\footnote{The term "conditional masked language model" appeared once in original BERT paper, which indicates context-conditional, is equivalent to term "masked language model". In our paper, "conditional masked language model" indicates we apply extra label-conditional constraint to the "masked language model".} task. The well trained conditional BERT can be applied to enhance contextual augmentation. Experiments on six various different text classification tasks show that our method can be easily applied to both convolutional or recurrent neural networks classifier to obtain obvious improvement.
翻译:我们为标签的句子提出了一种新的数据增强方法,称为有条件的BERT背景增强。数据增强方法通常用于防止过度适应和改进深神经网络模型的概括化。最近提出的背景增强方法通过随机替换语言模型预测的更多样化的替代语言来增加标记的句子。BERT表明,深双向语言模型比单向语言模型或前向和后向模型的浅相融合都更强大。我们通过引入一个新的有条件的蒙面语言模型来将BERT改装为有条件的BERT 。我们通过引入一个新的有条件的隐形语言模型\ footoot{在原始的 BERT 文件中出现过一次“有条件的隐蔽语言模型”的术语,它表示背景条件性,相当于“大规模语言模型”的术语。在我们的文章中,“有条件的蒙面语言模型”表明,我们对“有额外附加条件的附加条件的制约性语言模型...... ” 任务。经过良好训练的有条件的BERT可以应用来增强背景的增强。在六种不同的文本分类任务上进行的实验表明,我们的方法可以很容易地适用于革命性或经常性的神经网络分类,以获得明显的改进。