
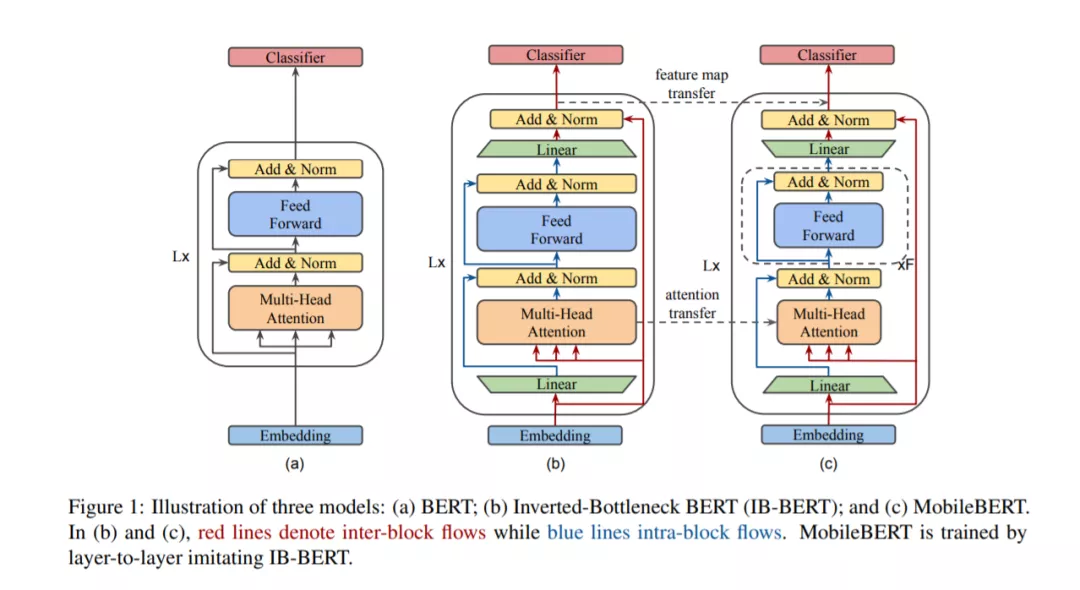
自然语言处理(NLP)最近取得了巨大的成功,它使用了带有数亿个参数的巨大的预先训练的模型。然而,这些模型存在模型大小过大和延迟时间长等问题,因此无法部署到资源有限的移动设备上。在本文中,我们提出了压缩和加速流行的BERT模型的MobileBERT。与最初的BERT一样,MobileBERT是与任务无关的,也就是说,它可以通过简单的微调应用于各种下游NLP任务。基本上,MobileBERT是BERT_LARGE的瘦版,同时配备了瓶颈结构和精心设计的自关注和前馈网络之间的平衡。为了训练MobileBERT,我们首先训练一个特别设计的教师模型,一个倒瓶颈合并BERT_LARGE模型。然后,我们把这个老师的知识传递给MobileBERT。实证研究表明,MobileBERT比BERT_BASE小4.3倍,快5.5倍,同时在著名的基准上取得了有竞争力的结果。在GLUE的自然语言推断任务中,MobileBERT实现了GLUEscore o 77.7(比BERT_BASE低0.6),在Pixel 4手机上实现了62毫秒的延迟。在team v1.1/v2.0的问题回答任务中,MobileBERT获得了dev F1的90.0/79.2分(比BERT_BASE高1.5/2.1分)。
成为VIP会员查看完整内容
相关内容

专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
11+阅读 · 2019年10月30日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
15+阅读 · 2018年10月11日
相关主题
相关VIP内容
专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
15+阅读 · 2018年10月11日