干货 | 让算法解放算法工程师——NAS 综述
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文转自公众号:AI科技评论
NAS 综述
AutoML(automated machine learning)是模型选择、特征抽取和超参数调优的一系列自动化方法,可以实现自动训练有价值的模型。AutoML 适用于许多类型的算法,例如随机森林,gradient boosting machines,神经网络等。 机器学习最耗费人力的是数据清洗和模型调参,而一般在模型设计时超参数的取值无规律可言,而将这部分过程自动化可以使机器学习变得更加容易。即使是对经验丰富的机器学习从业者而言,这一自动化过程也可以加快速度。
Deep learning 实现端到端的的特征提取,相对于手工提取特征是一个巨大的进步,同时人工设计的神经网络架构提高了神经网络的复杂度。
随着技术的发展,Neural Architecture Search (NAS) 实现神经网络可以设计神经网络,代表机器学习的未来方向。NAS 是 AutoML 的子领域,在超参数优化和元学习等领域高度重叠。NAS 根据维度可分为三类:搜索空间、搜索策略和性能评估策略。(本文仅总结 NAS 在 CV 领域的应用,NLP 的应用将另写综述)。
搜索空间
搜索空间原则上定义了网络架构。对于一个任务,结合相关属性的先验知识可以缩小搜索空间的大小并简化搜索。但是同时也引入了人类偏见,这可能妨碍发现超越当前人类知识的新颖架构模块。
搜索策略
搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。
性能评估策略
因为深度学习模型的效果非常依赖于训练数据的规模,通常意义上的训练集、测试集和验证集规模实现验证模型的性能会非常耗时,所以需要一些策略去做近似的评估。
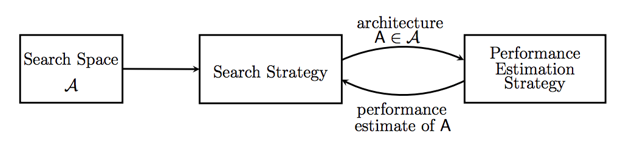
图 1 网络架构搜索方法
1.1 搜索空间
搜索空间,顾名思义,代表一组可供搜索的神经网络架构。
搜索空间根据网络类型可以划分为链式架构空间、多分支架构空间、cell/block 构建的搜索空间。根据搜索空间覆盖范围可分为 macro(对整个网络架构进行搜索)和 micro(仅搜索 cell,根据 cell 扩展搜索空间)。
1. 第一种搜索空间是链式架构空间(图 2 左图所示)。链式架构空间的每一层输出都是下一层的输入。搜索空间包括以下参数:
(1)网络最大层数 n。(2)每一层的运算类型:池化、连接、卷积(depthwise separable convolutions,dilated convolutions、deconvolution)等类型。(3)运算相关的超参数:滤波器的大小、个数、 strides 等。(4)激活函数:tanh,relu,identity,sigmoid 等。
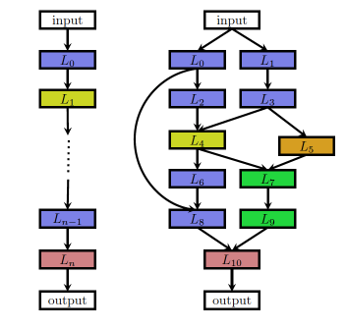
图 2 链式架构空间(左图)与多分支架构空间(右图)
2. VGG19 等模型已经证明直筒的链式结构容易造成梯度弥散,卷积网络无法使层数更深。ResNet 和 DenseNet 等引入的跳跃连接和密集连接,使得更深的网络成为可能。目前很多论文的实验数据也证实多分支架构空间可以实现更高精度(代价是搜索空间呈指数级别增加)。图 2 右图所示为多分支架构空间连接示意图。
3. 基于基本的 cell/block 构建的搜索空间。
很多神经网络结构虽然很深,但会有基本的 cell/block,通过改变 cell/block 堆叠结构,一方面可以减少优化变量数目,另一方面相同的 cell/ block 可以在不同任务之间进行迁移。BlockQNN[2] 结合 Inception blocks 和 residue blocks,设计 block 模块,通过堆叠 block 设计搜索空间。Zoph et al[3] 设计两类 cells:normal cell 和 reduction cell (normal cell 不改变输入 feature map 的大小的卷积,而 reduction cell 将输入 feature map 的长宽各减少为原来的一半的卷积,通过增加 stride 的大小来降低 size),通过构建重复模块(cells)的深度堆叠结构。这个堆叠结构是固定的,但其中各个模块的结构可以改变。
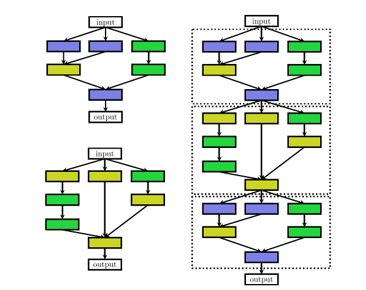
图 3 基于 cell/block 构建的搜索空间
Cell 作为基本单元,也可以固定不变。PNAS[9] 学习的是单一一种 cell 类型,而没有区分 Normal cell 和 Reduction cell.
1.2 搜索策略
搜索算法通常是一个迭代过程,定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法。其中强化学习和进化学习是主流算法,也是本章节重点介绍对象。
在搜索过程的每个步骤或迭代中,从搜索空间产生“样本”形成一个神经网络,称为“子网络”。所有子网络都在训练数据集上进行训练,然后将它们在验证数据集上的准确性视为目标(或作为强化学习中的奖励)进行优化。搜索算法的目标是找到优化目标的最佳子网络,例如最小化验证损失或最大化奖励。
基于强化学习的搜索方法
基于强化学习(reinforcement learning ,RL)的方法已经成为 NAS 的主流方法[4]。RL 有四个基元:agent, action,environment 和 reward. 强化学习是通过奖励或惩罚(reward)来学习怎样选择能产生最大积累奖励的行动(action)的算法。
NAS 的核心思想是通过一个 controller RNN 在搜索空间(search space)中得到一个子网络结构(child network),然后用这个子网络结构在数据集上训练,在验证集上测试得到准确率,再将这个准确率回传给 controller,controller 继续优化得到另一个网络结构,如此反复进行直到得到最佳结果,整个过程称为 Neural Architecture Search。
基于 NAS 的 RL 算法主要区别在于:
(a) 如何定义行动空间(在新的空间选择配置还是在修订已经存在的网络)
(b) 如何更新行动策略。Zoph et al 首先使用梯度策略更新策略 [4],并在其后的工作中使用 proximal policy optimization。Baker et al. 使用 Q-learning 更新行动策略。
在探索高维搜索空间时,基于 RL 的搜索成本非常高。NAS[4] 在使用 800 块 GPU 情况下耗时 28 天。其后续工作 [3] 使用 450 块 GPU 耗时 4 天生成简单的搜索空间。
基于进化学习的搜索方法
进化学习(Evolutionary algorithms ,EA)为了达到自动寻找高性能的神经网络结构,需要进化一个模型簇(population)。每一个模型,也就是个体(individual),都是一个训练过的结构。模型在单个校验数据集(validation dataset)上的准确度就是度量个体质量或适应性的指标。
在一个进化过程中[7],工作者(worker)随机从模型簇中选出两个个体模型;根据优胜劣汰对模型进行识别,不合适的模型会立刻从模型簇中被剔除,即代表该模型在此次进化中的消亡;而更优的模型则成为母体(parent model),进行繁殖;通过这一过程,工作者实际上是创造了一个母体的副本,并让该副本随机发生变异。研究人员把这一修改过的副本称为子代(child);子代创造出来后,经过训练并在校验集上对它进行评估之后,把子代放回到模型簇中。此时,该子代则成为母体继续进行上述几个步骤的进化。
简言之,该进化算法就是在随机选出的个体中择其优,因此该方法也属于联赛选择算法(tournament selection)的一种。
另外,如无其他说明,模型簇一般能容纳 1000 个个体,工作者的数量一般是个体数量的 1/4,而消亡个体的目录会被删除,以保证整个算法能长时间在有限空间中运行。
进化学习的一个缺点是进化过程通常不稳定,最终的模型簇质量取决于随机变异。Chen et al[8] 提出通过 RL 控制器确定变异替代随机变异,稳定搜索过程。
Chenxi Liu et al.[9] 使用了基于序列模型的优化(SMBO)策略,按复杂度逐渐增大顺序搜索架构,同时学习一个用于引导该搜索的代理函数(surrogate function),类似于 A* 搜索。
1.3 性能评估策略
性能评估策略是实现搜索加速的过程。基于强化学习、进化学习等搜索策略,为了引导搜索空间,每个子网络都需要训练和评估。但是训练每个子网络需要巨大的资源消耗(比如 NAS[4] 需要 2000 GPU*天)。通常加速 NAS 的方法是通过训练后再查找近似度量的方式(例如减少训练 epochs,简化评估数据集 [3][4]、使用低分辨率图像、每一卷积层使用更少的滤波器)。本章节介绍两种更优的类型:(a) 代理度量 improved proxy;(b) 权值共享 weight-sharing。
1. 使用代理度量时,子网络之间的相对排名需要保持与最终模型准确率相关。Zhong et al.[10] 提出 FLOPS、子模型的 model size 与最终模型准确率负相关,介绍一种应用于奖励计算的修正函数,子网络的准确性可以通过提前训练停止获得,弥合代理度量和真实准确率的差距。有些算法提出通过预测神经网络模型的准确率、学习曲线、验证曲线等来改进代理度量,预测准确率低/学习曲线差的子网络暂停训练或直接放弃。
2. 权值共享。
子网络直接继承已经训练好的模型权重参数,可以显著降低模型的运算量 [7]。One-Shot 架构搜索 [11] 将所有架构视作一个 one-shot 模型(超图)的子图,子图之间通过超图的边来共享权重。一些论文直接在模型基础上添加卷积层或插入跳跃连接,参数权重可以直接复用,减少模型的运算量。
1.4 Multi-Objective NAS
以 Google 的 NAS 为基础,很多模型专注于优化模型的准确率而忽视底层硬件和设备,例如工作站,嵌入式设备和移动终端具有不同的计算资源和环境,仅考虑准确率高的模型难以在移动终端部署。
图 4 基于单目标 VS 多目标神经网络架构搜索算法对比
MONAS/ MnasNet/DPP-Net[12][13][14] 等模型提出基于移动端的多目标神经网络搜索算法,评价指标从准确率扩展到功耗、推断延时、计算强度、内存占用、FLOPs 等指标。如图 4 所示单目标和多目标神经网络架构搜索算法对比。
多目标神经网络架构搜索采用帕雷托最优寻找最佳解决方案。帕雷托最优来源于经济学的概念,指资源分配的一种理想状态。延伸到工程,解决方案在不降低其他目标的前提下,任何目标都能不能得到改善,则认为是帕雷托最优的。
多目标 NAS 可以分为两类:基于 RL 和基于 EA 的算法。MnasNet/ MONAS 是基于 RL 的多目标算法。本人在知乎写过一篇叫基于 MnasNet 的阅读笔记,详情可参阅:https://zhuanlan.zhihu.com/p/42474017
NAS 局限性:
NAS 的搜索空间有很大的局限性,目前 NAS 算法仍然使用手工设计的结构和 blocks,NAS 仅仅是将这些 blocks 堆叠。NAS 还不能自行设计网络架构。NAS 的一个发展方向是更广泛的搜索空间,寻找真正有效率的架构,当然这也对搜索策略和性能评估策略提出更高的要求。
AutoML概述
构建一个典型的机器学习项目,一般分成以下步骤:收集原始数据(标注数据)、清洗数据、特征工程、模型构建、超参数调优、模型验证和模型部署。整个过程中,模型构建最能体现创造力,而最耗时的,要数特征工程和超参数调优。

图 5 AutoML 开源框架全景图
AutoML 框架能帮助算法工程师减轻负担,降低特征工程和超参数调优的工作量,NAS 可以完成模型的构建,基于 AutoML 的一揽子解决方案(如图 5 包含 AutoML 开源框架)。
AutoML 抽象所有 deep learning 的复杂过程,所需要的仅仅是数据。目前互联网巨头已经在很多行业提供 AutoML 服务,如微软的 CustomVision.AI、谷歌 Cloud AutoML、中科院的 BDA 系统、阿里 PAI 等。这些平台仅仅需要上传数据,AutoML 实现深度学习的训练、调优、云服务等,如图 6 所示(当然现在还是半自动化的人工参与状态,全自动化的 AutoML 是未来发展方向)。
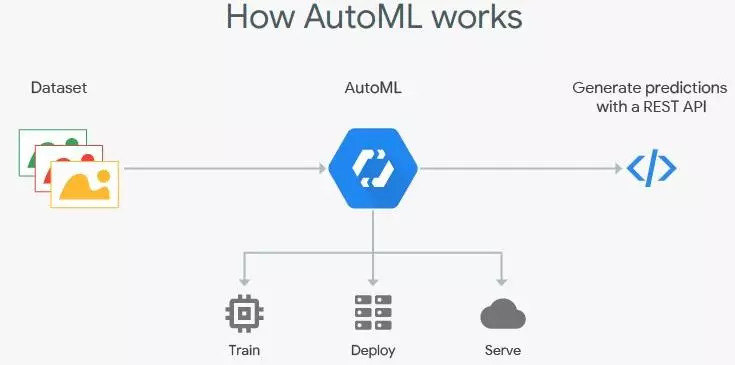
图 6 AutoML 工作流程图
阿里的 PAI Studio 汇集了阿里集团大量优质分布式算法,包括数据处理、特征工程、机器学习算法、文本算法等,可高效完成海量、亿级维度数据的复杂计算,给集团业务带来更为精准的洞察力。
AutoML Vision 是 Cloud AutoML 这个大项目推出的第一项服务,提供自定义图像识别系统自动开发服务。根据谷歌介绍,即使是没有机器学习专业知识的的小白,只需了解模型基本概念,就能借助这项服务轻松搭建定制化的图像识别模型。只需在系统中上传自己的标签数据,就能得到一个训练好的机器学习模型。整个过程,从导入数据到标记到模型训练,都可以通过拖放式界面完成。除了图像识别,谷歌未来还计划将 AutoML 服务拓展到翻译、视频和自然语言处理等领域。目前 Cloud AutoML 的费用是 20 美金/小时,相当于国内算法工程师的时薪。
机器学习的平台化降低了 AI 产品的使用成本,最终会降低机器学习的准入门槛,但提高了个人的职业门槛。随着谷歌、亚马逊、微软、BAT 等大厂对 AI 的持续投入,调参效果和业务范围会越来越广。笔者所在的项目组经过 6 个月努力发版上线一个应用,降低了 60% 的人力成本,自动化效率提高到 80%。工业时间业务不止模型调参那么简单,需要结合很多图像数据的先验知识,随着 NAS 的发展,也许不能取代 100% 的人力成本,但是在项目团队中解放 50% 以上的算法工程师还是可行的。
以上仅为个人阅读论文后的理解、总结和思考。观点难免偏差,望读者以怀疑批判态度阅读,欢迎交流指正。
参考文献
[1] Thomas. Elsken,Jan Hendrik.Metzen: Neural Architecture Search: A Survey .arXiv preprint arXiv: 1808.05377 (2018)
[2] Zhao Zhong, Zichen Yang, Boyang Deng:BlockQNN: Efficient Block-wise Neural Network Architecture Generation .arXiv preprint arXiv: 1808.05584 (2018)
[3] Zoph B, Vasudevan V, Shlens J, Le QV .Learning Transferable Architectures for Scalable Image Recognition.arXiv preprint arXiv: 1707.07012 (2017)
[4] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. ICLR’17,2016.
[5] Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, and Jun Wang. Efficient architecture search by network transformation. AAAI’18, 2017.
[6] Chenxi Liu, Barret Zoph, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. arXiv preprint arXiv:1712.00559, 2017.
[7] Esteban Real ,Sherry Moore,Andrew Selle , Saurabh Saxena .Large-Scale Evolution of Image Classifiers .arXiv preprint arXiv:1703.01041
[8] Yukang Chen, Qian Zhang, Chang Huang, Lisen Mu, Gaofeng Meng, and Xinggang Wang. Reinforced evolutionary neural architecture search. arXiv preprint arXiv:1808.00193, 2018.
[9] Chenxi Liu, Barret Zoph, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. arXiv preprint arXiv:1712.00559, 2017.
[10] Zhao Zhong, Junjie Yan, and Cheng-Lin Liu. Practical network blocks design with q-learning. AAAI’18, 2017.
[11] Andrew Brock, Theodore Lim, James M Ritchie, and Nick Weston. Smash: one-shot model architecture search through hypernetworks. ICLR’18, 2017.
[12] Chi-Hung Hsu, Shu-Huan Chang, Da-Cheng Juan, Jia-Yu Pan, Yu-Ting Chen, Wei Wei, and Shih-Chieh Chang. Monas: Multi-objective neural architecture search using reinforcement learning. arXiv preprint arXiv:1806.10332,2018.
[13] Jin-Dong Dong, An-Chieh Cheng, Da-Cheng Juan, Wei Wei, and Min Sun. Dpp-net: Device-aware progressive search for pareto-optimal neural architectures. arXiv preprint arXiv:1806.08198, 2018.
[14] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. arXiv preprint arXiv:1807.11626, 2018.
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~



