用 ICLR 论文求婚,除了撒“高级狗粮”,还能缓解「过拟合」与「过平滑」

编辑 | 丛末
ICLR,中文全称是国际表征学习大会,专注于有关深度学习各个方面的前沿研究。
此会议在人工智能、统计和数据科学领域以及机器视觉、语音识别、文本理解等重要应用领域中贡献了众多极其有影响力的论文。
另外,据说在此会议上发布论文除了能够普及学术成果,还能够增加求婚成功的几率。
没错,如果你有男/女朋友,并且还有一篇顶级会议的论文。那么,恭喜你就可以“为所欲为”了~
例如下面这位~
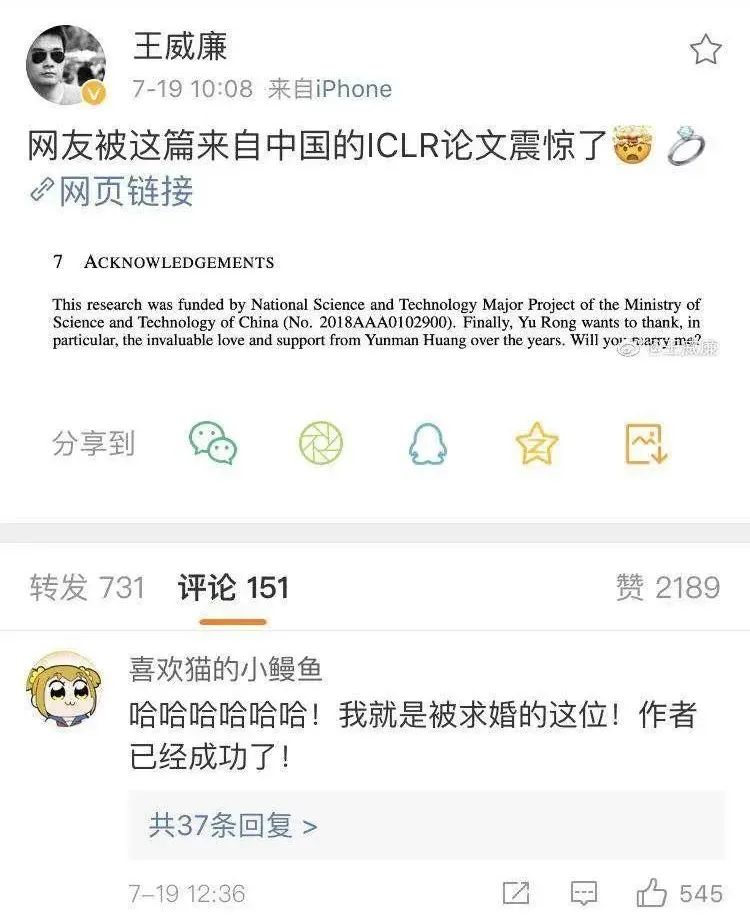
在这篇论文致谢部分,作者说:“本研究受国家科技部重大专项资助。另外,Yu Rong特别要感谢Yunman Huang多年来的关爱和支持,你愿意嫁给我么?”
显然,在论文中求婚得到了积极的反馈,微博网友@喜欢猫的小鳗鱼说,她就是被求婚的这位,并且作者已经成功了。
这般“花式虐狗”自然引起了热议,@王威廉微博下已经有两千多个赞为这两位送上了祝福。评论区也是一水的祝福~
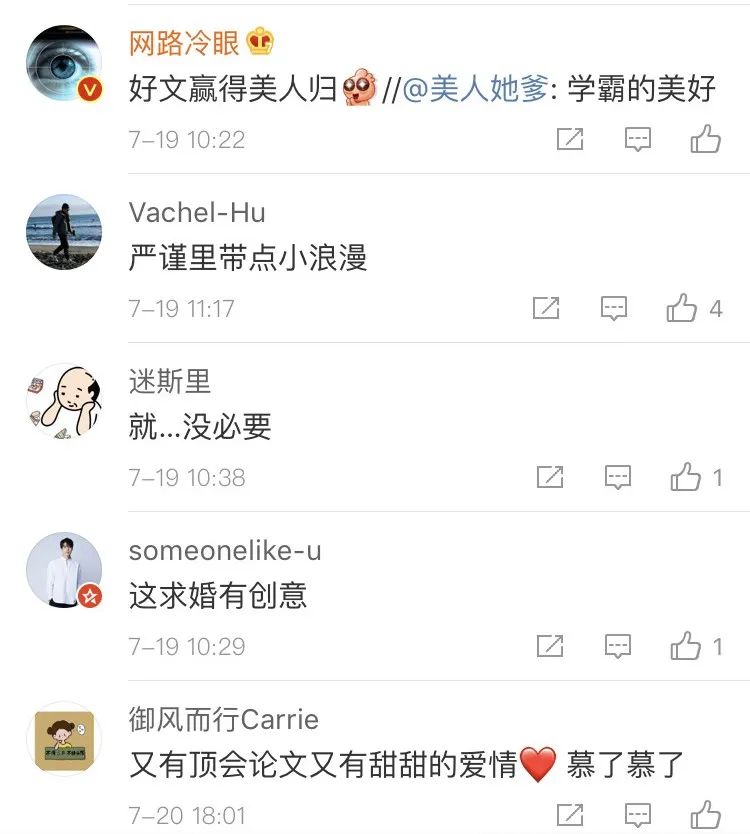
当然,还有姑娘想到了自己的朋友,并在这条微博下@自己的朋友:“希望你的论文里能有我”,被@的网友用了带两个“感叹号”强调句回复道:“我会的!!”
其实,用发表的论文在致谢部分求婚不是“孤例”,例如央视新闻曾经报道过,华中科技大学的龙瑞在论文致谢部分,公然向女友求婚。当时网友笑称:“你的意中人是个科研大牛,有一天他会带着一篇附有求婚致谢的SCI来娶你”。
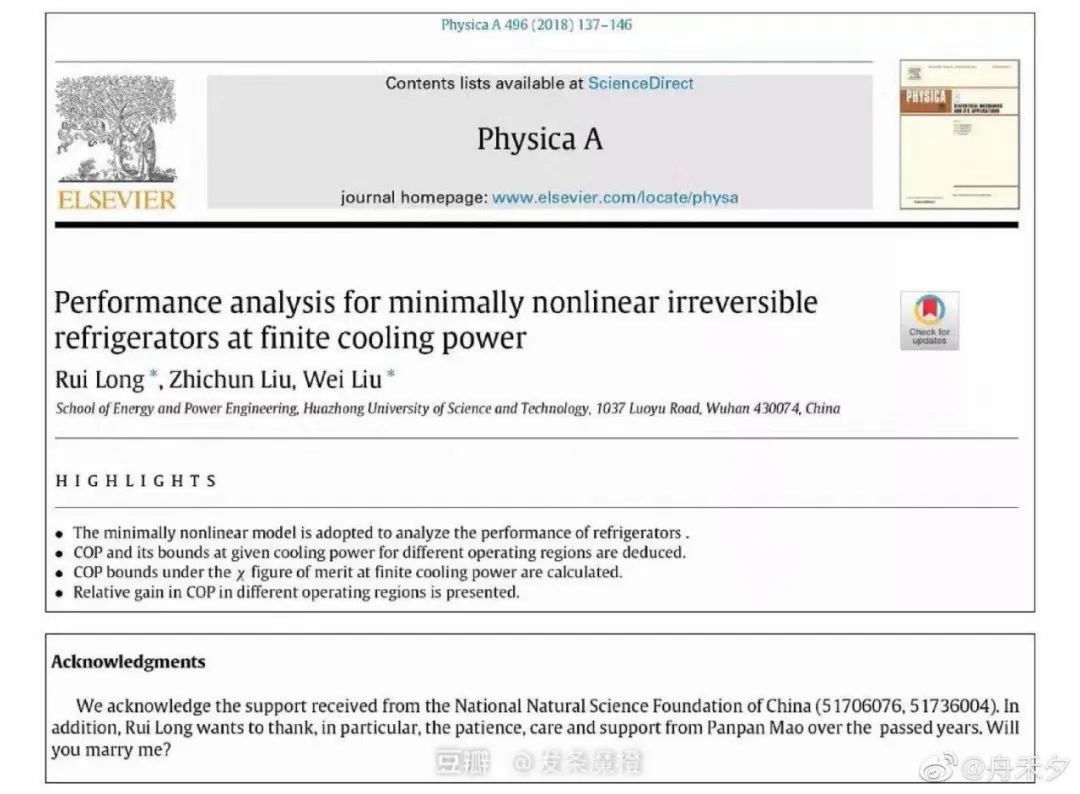
但是,AI科技评论发现,无论是这篇ICLR论文,还是SCI论文,所讲述的都是“工科故事”,求婚用的英文句式也都是:Will you marry me?
为此,小编专门找了几个优秀的求婚表达,供大家参考:
1、Will you spend the rest of your life with me?
2、I think it's time we took some vows.
3、Let’s tie the knot.
4、I'm ready for a life-long commitment.
5、I don’t just want temporary affection, but a partner for a lifetime.
好了,书回正传,这篇ICLR论文具体做的什么工作呢(敲黑板,划重点了)?下面AI科技评论对此论文进行解读☺
「过拟合」与「过平滑」是开发用于节点分类的深度图卷积网络(GCN)的两大拦路虎。具体而言,过拟合降低了模型在小数据集上的泛化能力;而随着网络深度增加,过平滑则会导致 GCN 的输出表征与输入特征之间的关联性降低(隐层表征会趋向于收敛到同一个值),从而为训练带来困难。
本文提出了一种新颖、灵活的技术 DropEdge 来缓解以上两个问题。DropEdge 的核心思想是在每轮训练中随机地从输入图中删除掉一定数量的边,它扮演着类似于数据增强器和消息传递减速器的角色。
此外,本文还从理论上说明了 DropEdge 不仅降低了过平滑的收敛速度,也减少了由于过平滑引起的信息损失。更重要的是,作为一种通用的技术,DropEdge 可以被应用于许多其它的主干网络模型(例如,GCNResGCN、GraphSAGE、JKNet),从而提升它们的性能。
本文作者在一些对比基准任务上进行了大量的实验,实验结果表明 DropEdge 在较浅和较深的 GCN 网络上始终可以实现性能的提升。作者通过实验验证和可视化技术证明了 DropEdge 对于防止过平滑的作用。

论文链接:https://arxiv.org/pdf/1907.10903.pdf
代码链接:https://github.com/DropEdge/DropEdge
引言与符号定义
图卷积网络(GCN)是一种利用消息传递或某种邻居节点聚合函数从节点及其邻居中提取出高级特征的网络模型,它促进了许多针对图上任务(节点分类、社交推荐、链接预测等)的模型的性能提升,已经成为了最重要的图表征学习工具之一。然而,目前典型的用于节点分类的 GCN 往往都很浅,这限制了图网络的表征能力。
受深度卷积神经网络在图像分类任务上取得的成功的启发,许多研究者试图构建深度的 GCN 用于节点分类任务,然而他们至今仍没有开发出高效的表达架构。本文旨在深入剖析阻碍更深的 GCN 取得良好性能的关键因素,并开发相应的方法解决这些问题。
作者首先考虑了两种关键的因素:「过拟合」与「过平滑」。
(1)过拟合:过拟合一直是各种机器学习方法力图解决的难点,当我们通过一个过参数化的模型使用数量有限的训练数据拟合某一个分布时,就会产生过拟合现象,此时我们学到的模型可以很好地拟合训练数据,但是在测试集上的泛化效果却很差。当我们将一个深度 GCN 应用在小型图上也会产生过拟合的问题。
(2)过平滑:图卷积操作本质上会促使相邻节点的表征相互融合。在极端情况下,如果我们使用了层数无限大的 GCN,所有的节点表征都会由于信息聚合收敛到一个固定点上,这会导致最终的表征与输入特征无关,还会导致梯度弥散现象。
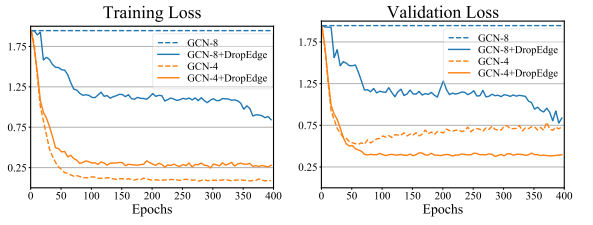
图 1:多层 GCN 在 Cora 数据集上的性能表现。橙色实线/虚线(GCN-4+DropEdge/GCN-4)分别代表加入了 DropEdge 和不加入 DropEdge 的深度为 4 层的 GCN;蓝色实线/虚线(GCN-8+DropEdge/GCN-8)分别代表加入了 DropEdge 和不加入 DropEdge 的深度为 8 层的 GCN。GCN-4 陷入了过拟合问题中,其训练误差很低而验证误差较高。GCN-8 则由于过平滑问题而无法理想地收敛。通过应用 DropEdge 技术,GCN-4 与 GCN-8 在训练与验证过程中都取得了很好的性能。
本文提出的 DropEdge 方法可以缓解过拟合和过平滑问题,在训练过程中,它随机地删除输入图中一定比例的边。将 DropEdge 应用于 GCN 训练有以下好处:
(1)DropEdge 可以被看做一种数据增强技术。通过应用 DropEdge,我们可以生成原始图数据的各种随机的残缺子图,从而增强了输入数据的随机性和多样性,缓解了过拟合问题。
(2)DropEdge 可以被看做一个消息传递减速器。在 GCN 中,节点之间的消息传递是通过连边上的路径实现的,删除连边可以使得节点连接更加系数,从而避免深度 GCN 中的过平滑问题。
符号定义:
(1)令图 G=(V,E),该图包含 N 个节点 v_i∈V,节点之间的连边(v_i,v_j)∈E。
(2)节点特征:X={x_1,...,x_N}∈R^(N*C)。
(3)邻接矩阵:A∈R^(N*N),其中的元素 A_ij 对应于 E 中的连边(v_i,v_j)。
(4)节点度向量:d={d_1,...,d_N}。
(5)度矩阵 D:对角线上的元素取自 d。
GCN 的前向传播通过以下公式递归地计算得到:
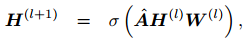
其中,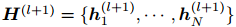
为节点 i 的隐特征。
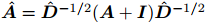
为 A+I 对应的度矩阵;σ(·)为非线性函数 ReLU;
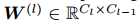
模型细节与方法
在每轮训练中,DropEdge 技术随机删除输入图中一定比例的连边,即随机将邻接矩阵 A 中的 V*p 个非零元素置为零,其中 V 为图中边的综述,p 是删除边的比例。最终得到的残缺子图的邻接矩阵 A_drop 可写作:
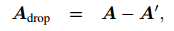
其中,A' 是通过原始边集 E 中大小为 V*p 的随机子集展开的稀疏矩阵,重归一化后的邻接矩阵为 。请注意,作者仅仅在训练阶段采用了 DropEdge,验证和测试阶段则不使用该技术。
1、防止过拟合
DropEdge 向图中的连接引入了各种各样的扰动,生成了各种输入数据的变形形式,我们可以将其看作对于图的一种数据增强技巧。
GCN 的关键之处在于对每个节点的邻居特征进行加权求和(每条边都有一定的权重),实现对邻居信息的聚合。从邻居信息聚合的角度来看,DropEdge 在 GNN 训练时使用的是随机的邻居子集进行聚合,而并非使用全部邻居。
从统计意义上说,DropEdge 仅仅会根据删除边的概率 p 改变邻居聚合的期望。实际上,在对权重进行归一化后,就不再考虑 p 了。因此,DropEdge 最终并不会改变邻居聚合的期望,它是一种用于训练 GNN 的无偏数据增强技术,类似于典型的图像增强方法(例如,旋转、剪切、抖动),可以缓解过拟合问题。
2、图卷积层级别的 DropEdge
在上述 DropEdge 的定义中,所有层都共享相同的扰动后的邻接矩阵。实际上,我们可以针对每一层都应用 DropEdge,独立地计算第 l 层的 ,每一层的
都不同。这种层级别的处理方式向原始数据中引入了更多的随机性和变形。
3、防止过平滑
过平滑现象指的是醉着网络深度增加,节点特征会收敛到一个固定点或一个子空间上,它会使得深度 GCN 的输出仅仅与网络拓扑有关,而与输入节点的特征无关,从而限制了 GCN 的表征能力。
一个足够深的 GCN 在一些温和的条件下往往会存在「ϵ-平滑」(ϵ 为任意小值)问题,即在独立于输入特征的子空间 M 中,GCN 的第 L 层的所有隐向量 之间的距离都不大于 ϵ。本文采用 DropEdge 技术从两个方面减缓了「ϵ-平滑」问题:
(1)通过减少节点间的连接,DropEdge 可以减缓过平滑的收敛速度,使用 DropEdge 可以让松弛后的 ϵ-平滑层数(即满足「ϵ-平滑」的层数的最小值)增加。
(2)原始空间和收敛子空间的维度之差(例如,N−M)衡量了信息的损失,这个差越大说明信息损失越严重。DropEdge 可以提升子空间的维度,因此具有减少信息损失的能力。
4、DropEdge 与 Dropout、DropNode、图稀疏化技术的异同
(1)DropEdge vs. Dropout:Dropout 通过随机地将某些特征维度置为零来扰动特征矩阵,可以缓解过拟合问题,但无法阻止过平滑,因为它并没有改变邻接矩阵。DropEdge 可以看做将 Dropout 扩展到了图数据上,从删除特征扩展到了删除边,同时缓解了过拟合和过平滑问题。
(2)DropEdge vs. DropNode:在这里,我们将基于节点采样的方法(例如,GraphSAGE、FastGCN、ASGCN)称为 DropNode。DropNode 旨在(通过删除节点)采样出用于 mini-batch 训练的子图,由于与被删除节点相连的边也被删除了,因此它们也可以被看做一种特殊的删除边的形式。但是 DropNode 对于删除边的影响是面向节点且无向的。然而,DropEdge 是面向边的,如果内存空间允许,它可以在训练中保留所有的节点信息,更加的灵活。此外,现有的 DropNode 方法的采样策略往往是低效的,而 DropEdge 既不会由于层数增加而增大每一层的尺寸,也不需要递归地采样(DropEdge 同时平行地对所有边的采样)。
(3)DropEdge vs. 图稀疏化:图稀疏化的优化目标是在保留输入图的大部分信息的条件下删除不必要的边,从而对图进行压缩。DropEdge 在训练时随机地删除输入图中的边,而不像图稀疏化技术需要设计优化目标并通过复杂的优化方法决定删除哪些边。
实验环境与实验结果
作者在以下 4 个图尺寸和类型都不同的对比基准测试数据集上对 DropEdge 进行了实验验证:
(1)在 Cora、Citeseer、Pubmed 三个文献引用数据集上对论文的研究主题进行分类。
(2)在 Reddit 社交网络数据集中,预测不同的博文属于哪个社区。
具体而言,作者从「DropEdge 对深度 GCN 的普遍性能提升」、「DropEdge 对过平滑的缓解」、「DropEdge 与 Dropout 的兼容性」、「图卷积层级别 DropEdge 的作用」4 个方面分析了 DropEdge 的性能。
1、DropEdge 对深度 GCN 的普遍性能提升
作者在实验中用到了 5 种主干网络:GCN、ResGCN、JKNet、IncepGCN 以及 GraphSAGE。
实验结果表明:DropEdge 在所有实验情况下均可以提升节点分类的准确率。随着层数不断加深,DropEdge 对性能的提升幅度也有加大的趋势。请注意,在 Pubmed 数据集上,未加入 DropEdge 的32 层 IncepGCN 出现了内存不足的问题,而加入了 DropEdge 之后则解决了这一问题,这说明 DropEdge 可以通过使邻接矩阵更稀疏来节省内存开销。
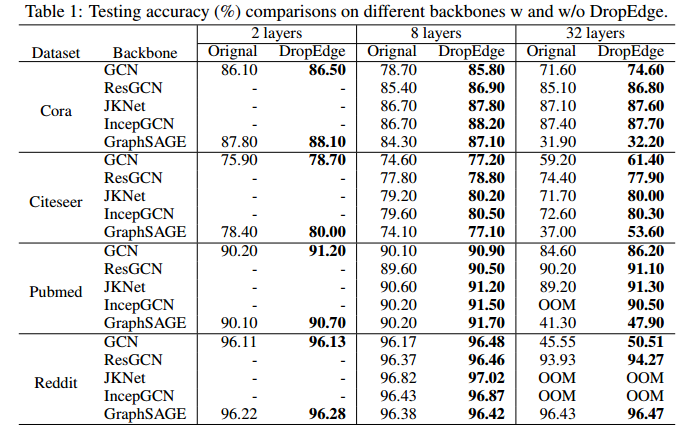
图 2:在主干网络上计入/不加入 DropEdge 的测试准确率对比结果。
如下图(b)所示,应用 DropEdge 后,验证损失曲线明显下降,这也说明了 DropEdge 有助于缓解过拟合现象。
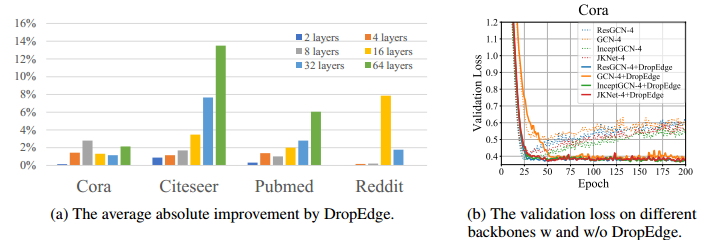
图 3:(a)DropEdge 的平均绝对性能提升(b)在各种主干网络中加入/不加入 DropEdge 时的验证损失。
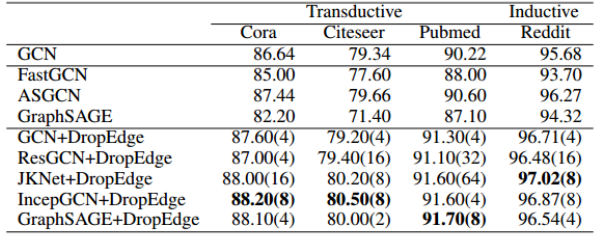
图 4:与目前最先进方法的准确率对比。括号中的数字表示使用了 DropEdge 的网络深度。
2、DropEdge 对过平滑的缓解
由于我们无法显式地求出收敛子空间,作者通过计算当前层的输出与前一层输出的欧氏距离来衡量过平滑程度,该距离越小说明过平滑程度越大。

图 5:过平滑分析。距离越小说明过平滑程度越大。
如图 5(a)所示,随着层数增加,GCN 中的过平滑现象越拉越严重。然而,向模型中加入 DropEdge(p=0.8)后,层之间的距离增大了,并且比不加入 DropEdge 时(p=0)收敛更慢。
如图 5(b)所示,在训练之后,没有加入 DropEdge 的 GCN 第 5 层和第 6 层输出的差别为零,这说明隐特征已经收敛到了一个固定点(过平滑)。另一方面,随着层数的加深,对于加入了 DropEdge 的 GCN 来说,不同层之间的差别并没有减为零,它可能已经成功学习到了节点的表征。
3、DropEdge 与 Dropout 的兼容性
如图 6 所示,尽管 Dropout 和 DropEdge 都有助于 GCN 训练,但是使用 DropEdge 的性能提升更明显,当我们同时采用这两种策略时,验证损失会进一步降低,这说明二者是兼容的。
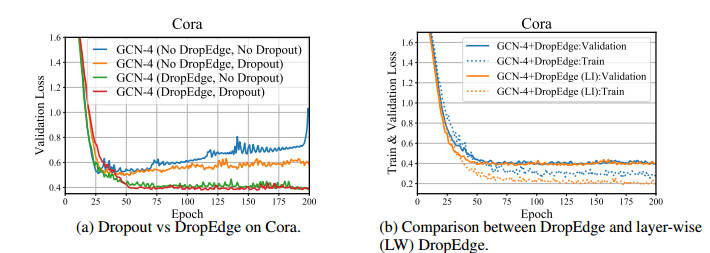
图 6:(a)Cora 数据集上使用 Dropout 与 DropEdge 的性能对比(b)使用 DropEdge 和层级别 DropEdge 的对比。
4、图卷积层级别 DropEdge 的作用
如图6(b)所示,使用层级别 DropEdge 比使用原始的 DropEdge 的模型在训练时的损失更小,而两者的验证损失相当。这表明层级别的 DropEdge 对训练的帮助更大。但是为了避免过拟合的风险,以及减小计算复杂度,作者倾向于使用原始的 DropEdge 而不是层级别的DropEdge。
AI 科技评论希望能够招聘 科技编辑/记者
办公地点:北京/深圳
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。





