选自arXiv
作者:Jizhizi Li、Dacheng Tao等
相比于人像抠图,长相各异、浑身毛茸茸的动物似乎难度更大。
IEEE 会士 Jizhizi Li、陶大程等人开发了一个专门处理动物抠图的端到端抠图技术 GFM。
在这个图像和视频逐渐成为主流媒介的时代,大家早已对「抠图」习以为常,说不定还看过几部通过「抠图」拍摄的电视剧呢。然而,相比于人像抠图,长相各异、浑身毛茸茸的动物似乎难度更大。
那么,是否有专用于动物的抠图技术呢?IEEE 会士 Jizhizi Li、陶大程等人就开发了一个专门处理动物抠图的端到端抠图技术。
![]()
动物的外观和毛皮特征给现有的方法带来了挑战,这些方法通常要求额外的用户输入(如 trimap)。
为了解决这些问题,陶大程等人研究了语义和抠图细节,将
任务分解为两个并行的子任务:高级语义分割和低级细节抠图
。具体而言,该研究提出了新型方法——Glance and Focus Matting network (GFM),使用共享编码器和两个单独的解码器以协作的方式学习两项子任务,完成端到端动物图像抠图。
研究人员还创建了一个新型动物抠图数据集 AM-2k,它包含 20 个类别的 2000 张高分辨率自然动物图像,并且具备手动标注的前景蒙版。
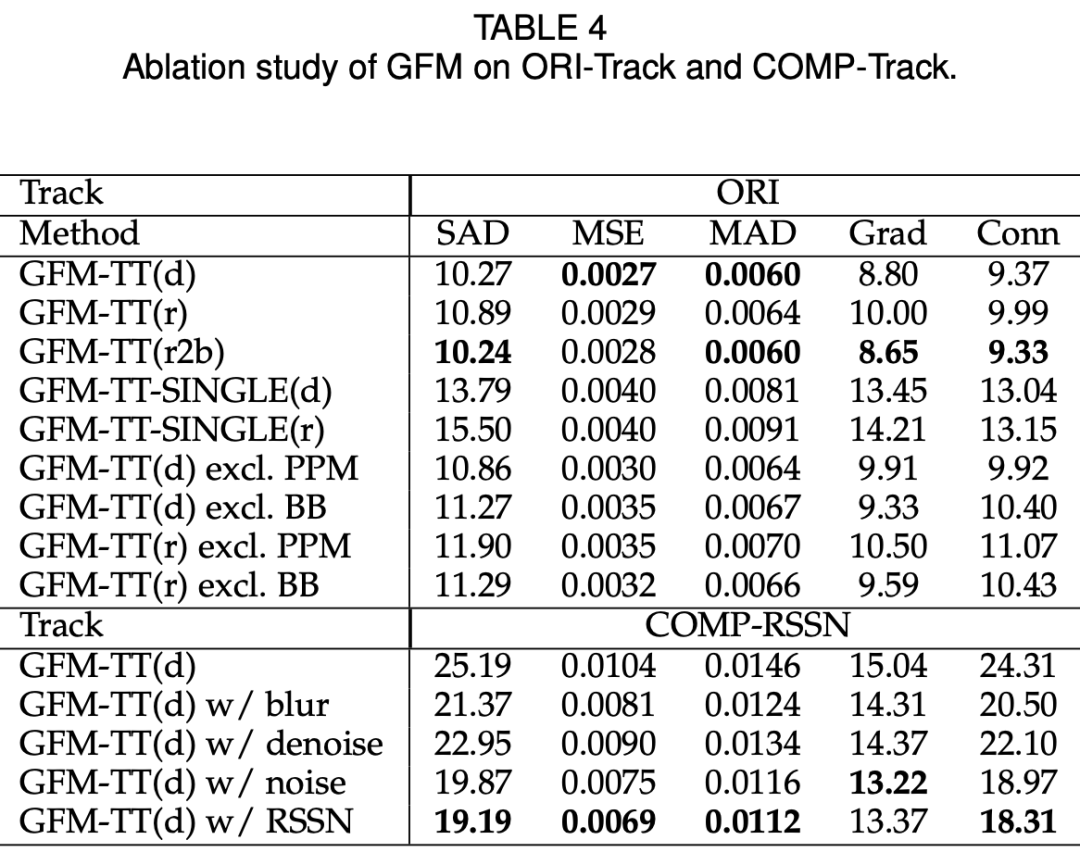
此外,该研究通过对前景和背景图像之间的不同差异进行综合分析,来研究合成图像和自然图像之间的领域差距(domain gap)问题。研究人员发现,其精心设计的合成流程 RSSN 能够降低差异,带来更好的、泛化能力更强的模型。在 AM-2k 数据集上的实验表明,GFM 超过当前最优方法,并且有效降低了泛化误差。
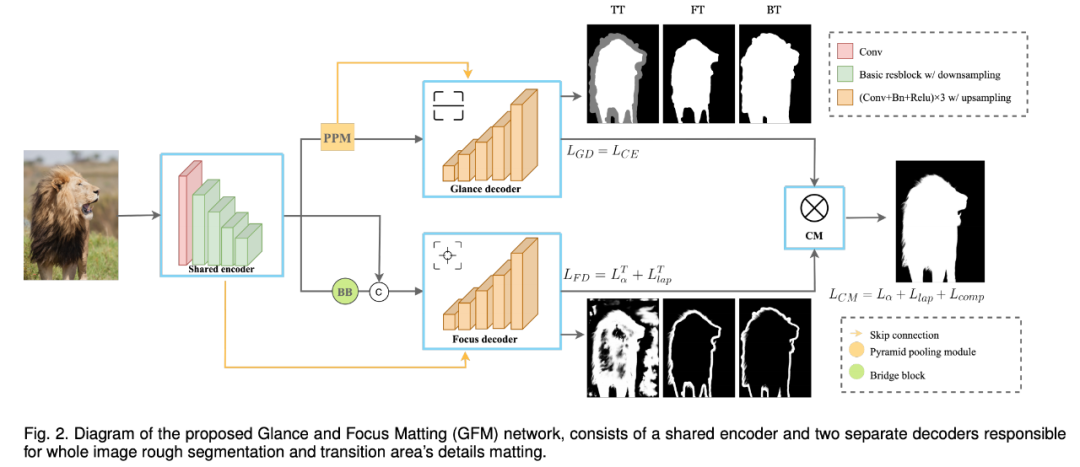
在给动物图像抠图时,人类首先会浏览一下图像,快速识别出大致的前景或背景区域,然后聚焦于过渡区域,将动物细节与背景区分开来。这可以大致形式化为分割阶段和抠图阶段。注意,这两个阶段可能会出现交叉,因为第二阶段的反馈信息可以纠正第一阶段错误的决策。
为了模仿人类经验,使抠图模型具备处理这两个阶段的能力,有必要将其合并进一个模型,并显式地建模二者之间的协作。因此,研究者提出了新型 GFM 网络,进行端到端的自然动物图像抠图,模型架构参见下图:
![]()
图 2:GFM 网络架构图示。它包含一个共享编码器和两个单独的解码器,解码器分别负责图像分割和细节抠图。
为自然图像标注前景蒙版费时费力且成本高昂,常见的操作是基于一些前景图像和成对前景蒙版生成大规模合成图像。
目前常见的蒙版合成流程是通过蒙版混合(alpha blending)将一个前景粘贴至不同的背景。但由于前景图像和背景图像通常采样自不同的分布,合成图像会出现大量合成伪影,从而导致合成图像和自然图像之间出现较大的领域差距。合成伪影可能会被模型误以为是 cheap feature,从而导致在合成图像上过拟合,在自然图上出现较大的泛化误差。
该研究系统地分析了引起合成伪影的因素:分辨率差异、语义模糊、锐度差异和噪声差异,并提出了解决方案——
一套新的合成流程 RSSN 和大规模高分辨率背景数据集 BG-20k
。
![]()
下图对比了不同合成图像方法,其中 c 和 d 使用的背景图像来自 BG-20k 数据集:
![]()
![]()
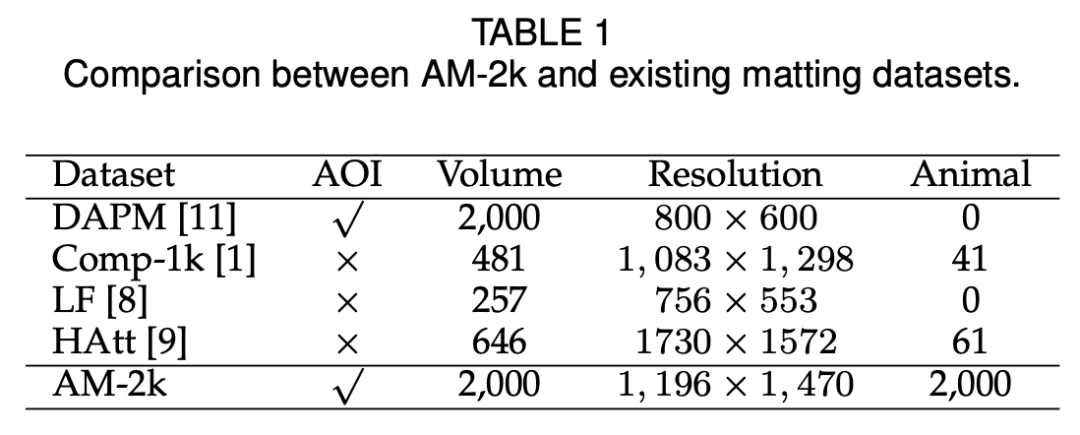
AM-2k 数据集包含 20 个类别的 2000 张高分辨率自然动物图像,并且具备手动标注的前景蒙版。研究者将该数据集分割为训练集和验证集,并设置了两个评估 track:ORI-Track (Original Images Based Track) 和 COMP-Track (Composite Images Based Track)。
下表展示了 AM-2k 数据集与现有抠图数据集的对比情况:
![]()
![]()
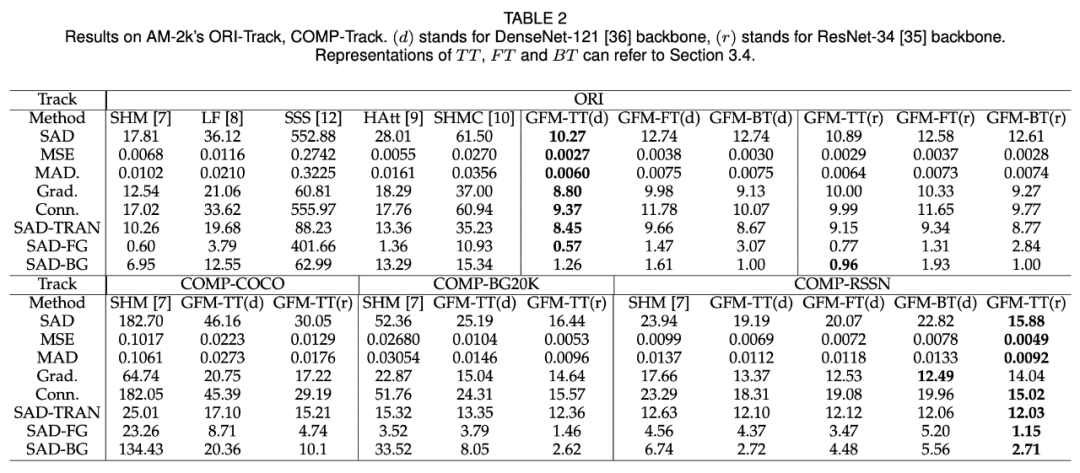
下表 2 展示了多种 SOTA 方法在 AM-2k ORI-Track 上的结果:
![]()
与 SOTA 方法相比,GFM 在所有评估指标上均超过它们,通过同时分割前景和背景图像以及在过渡区域抠图,取得了最优性能。
下图 6 展示了不同方法在 AM-2k ORI-Track 上的定性对比结果:
![]()
从图中可以看出,SHM、LF 和 SSS 无法分割一些前景部分,因为其分段式结构导致模型无法显式地分辨前景 / 背景和过渡区域。语义分割和抠图细节是很难平衡的,分别需要全局语义特征和局部结构特征。HAtt 和 SHMC 无法获得过渡区域的清晰细节,因为全局指引有助于识别语义区域,但对细节抠图的用户就没那么大了。
相比而言,GFM 获得了最优结果,这得益于其统一模型,使用单独的解码器处理前景 / 背景和过渡区域,并以协作的方式进行优化。
![]()
![]()
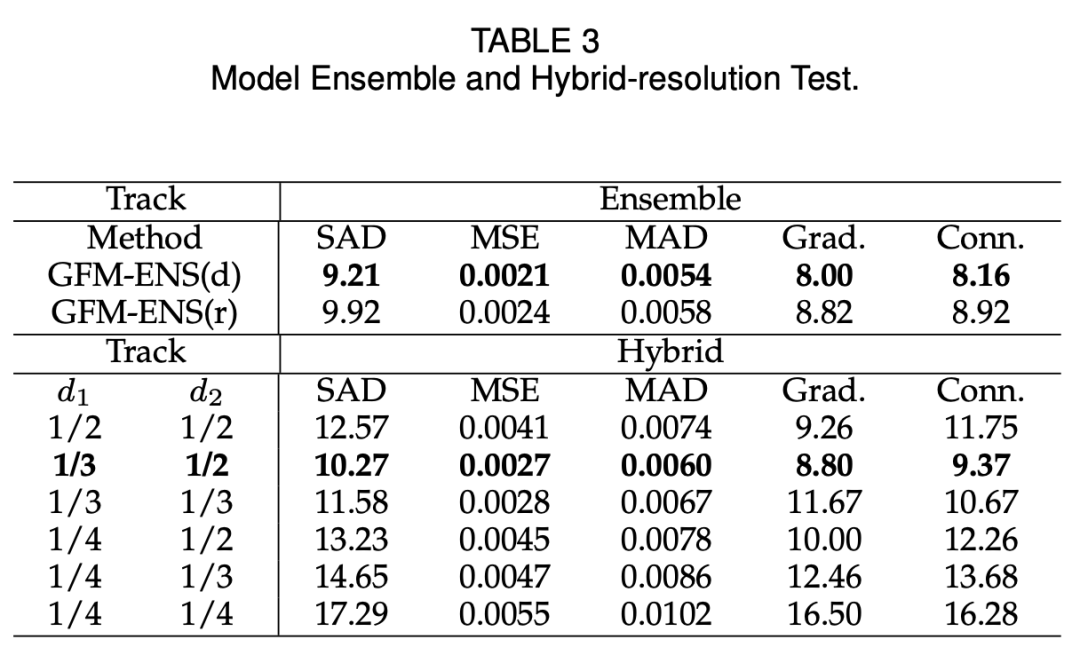
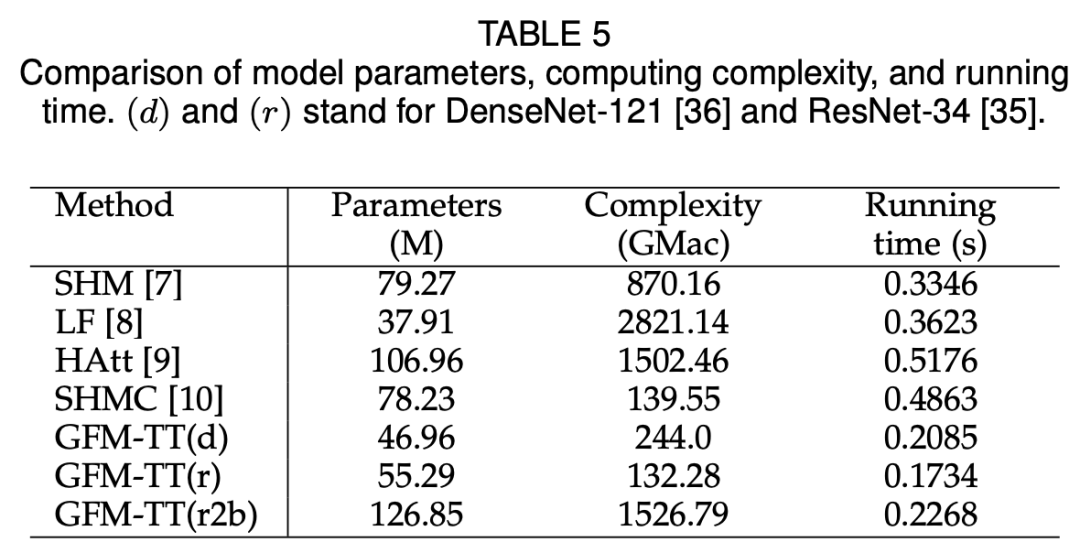
如下表 5 所示,使用 DenseNet-121 或 ResNet34 作为主干网络的 GFM 在运行速度上超过 SHM、LF、Hatt 和 SHMC,它们处理一张图像分别只需大约 0.2085s 和 0.1734s。
![]()
Amazon SageMaker 1000元大礼包
ML训练成本降90%,被全球上万家公司使用,Amazon SageMaker是全托管机器学习平台,支持绝大多数机器学习框架与算法,并且用 IDE 写代码、可视化、Debug一气呵成。
现在,我们准备了
1000元
的免费额度,开发者可以亲自上手体验,让开发高质量模型变得更加轻松。
点击阅读原文,填写表单后我们将与你联系,为你完成礼包充值。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com