CVPR 2018 | Spotlight论文:变分U-Net,可按条件独立变换目标的外观和形状
来源:机器之心
论文链接:https://arxiv.org/abs/1804.04694
作者:Patrick Esser等
简介
最近用于图像合成的生成模型备受关注 [7, 12, 18, 24, 49, 51, 32]。生成目标的图像需要对它们的外观和空间布局的详细理解。因此,我们必须分辨基本的目标特征。
一方面,有观察者视角相关的有目标的形状和几何轮廓(例如,一个人坐着、站着、躺着或者拎着包)。
另一方面,还有由颜色和纹理为特征的本质外观属性(例如棕色长卷发、黑色短平头,或者毛茸茸的样式)。
很明显,目标可以自然地改变其形状,同时保留本质外观(例如,将鞋子弄弯曲也不会改变它的样式)。然而,由于变换或者自遮挡等原因,目标的图像特征会在这个过程中发生显著变化。相反,衣服的颜色或者面料的变化对其形状是没有影响的,但是,它还是很清晰地改变了衣服的图像特征。

图 1:变分 U-Net 模型学习从左边的查询中进行推理,然后生成相同外观的目标在第一行所示的不同姿态下的图像。
由于深度学习的使用,生成模型最近有很大的进展,尤其是生成对抗网络 (GAN) [1, 8, 10, 27, 38]、变分自编码器 [16],以及它们的组合 [2, 17]。尽管有着引人注目的结果,但是这些模型在有着较大空间变化的图像分布上还是面临着性能较差的问题:
尽管在完美注册的人脸数据集(例如对齐的 CelebA 数据集 [22])上能够生成高分辨率的图像 [19,13],然而从像 COCO[20] 多样化的数据集中合成整个人体仍然是一个开放性的问题。
导致这个问题的主要原因是,虽然这些生成模型能够直接合成一个目标的图片,但是它无法对生成图像的外观和形状之间复杂的相互影响进行建模。所以,它们可以容易地向一张人脸添加胡须和眼镜,因为这相当于给那些图像区域重新着色。
将这个与人物移动胳膊相比,后者相当于给旧的位置的胳膊用背景颜色着色,并且将新位置的背景转变为一只胳膊。我们所缺失的就是一个能够改变物体形状,而不是仅能够调整颜色的生成模型。
所以,在生成图像的过程中,我们要对外观、形状以及两者之间的复杂影响进行建模。对于通用的适用性,我们希望能够仅从静态的图像数据集中进行学习,而不需要展示同一目标不同形状的一系列图片。
为此,研究者提出了条件 U-Net[30] 架构,这个架构用于从形状到目标图像的映射,以及将关于外观的变分自编码器的潜在表征条件化。为了解耦形状和外貌,我们允许利用与形状相关的简单可用信息,例如边缘或者身体关节位置的自动估计。
然后该方法能实现条件图像生成和转换:为了合成不同的几何轮廓或者或者改变目标的外观,一个查询图片的外观或者形状会被保留,同时未被保留的那一部分就会被自由改变,甚至从其他图像导入。此外,模型也允许在不改变形状的情况下对外观分布进行采样。
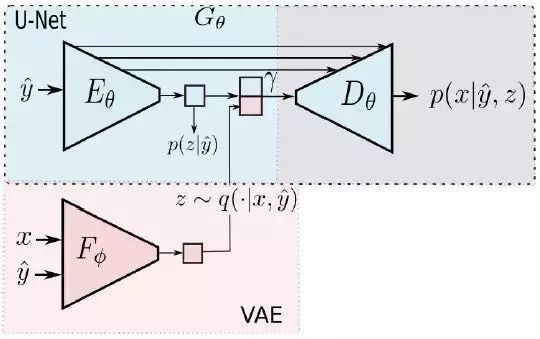
图 2: 条件 U-Net 与变分自编码器相结合。x:查询图像,y hat:形状估计,z:外观。

图 3: 仅仅将边缘图像作为输入时的生成图像(左侧的 GT 图像被保留了)。研究者在鞋子数据集 [43] 和挎包数据集 [49] 上将本文的方法与 pix2pix 进行了对比。在图的右侧是从变分 U-Net 的潜在外观分布中的采样。

表 1: 在 DeepFashion 和 Market1501 数据集上重建图像的结构相似性(SSIM)和 Inception score(IS)。本文的方法要比 pix2pix[12] 和 PG^2[24] 具有更好的 SSIM 性能,至于 IS 性能,本文的方法要比 pix2pix 好一些,并且和 PG^2 有着相当的结果。


图 4:仅仅将曲棍球击球手作为输入的生成图像(GT 图像被保留)。在 Deepfashion 和 Market-1501 数据集上将本文的方法与 pix2pix[12] 进行比较。图像右侧是从潜在外观分布中所得的采样。

图 5: 草图着色:比较 pix2pix[12] 和本文的模型的生成能力,本文的模型是在实际图像上进行的训练。任务是为鞋子和挎包的手绘草图生成合理的外观 [9]。

图 6: Market-1501 数据集上的外观转换。外观由左侧底部的图像提供。yˆ(中间)是从顶部图像中自动提取,并向底部进行转换。

图 7: DeepFashion 数据集上外观转换的稳定性。每一行都是使用最左侧图像的外观信息合成的,每一列都是对应于第一行的姿态的合成。需要注意的是,推理得到的外观在很多视角上都是不变的。

图 8:图像转换与 PG^2 的比较。左侧:Market 数据集上的结果。右侧:DeepFashion 数据集上的结果。外观是从条件图像中推理得到的,姿态是从目标图像中推理的得到的。要注意,本文的方法不需要关于人物身份的标签。
论文:A Variational U-Net for Conditional Appearance and Shape Generation(用于条件式生成外貌和形状的变分 U-Net)

深度生成模型在图像合成领域展现了优异的性能。然而,由于它们是直接生成目标的图像,而没有对其本质形状和外观之间的复杂相互影响进行建模,所以在空间转换时就会存在性能退化。
我们针对形状指导图像生成提出了条件 U-Net,将变分自编码器输出的外观条件化。这个方法在图像数据集上进行端到端的训练,不需要同一个物体在不同的姿态或者外观下的采样。
实验证明,这个模型能够完成条件图像生成和转换。所以,查询图像的外观或者形状能够被保留,同时能够自由地改变未被保留的另一个。
此外,在保留形状的时候,由于外观的随机潜在表征,它可以被采样。在 COCO、 DeepFashion,、shoes、 Market-1501 以及 handbags 数据集上进行的定性和定量实验表明,我们的方法比目前最先进的方法都有所提升。
*推荐文章*
《DA Sequence Labeling using Hierarchical encoder with CRF》阅读笔记
IEEE2018|An Accurate and Real-time 3D Tracking System for Robots





