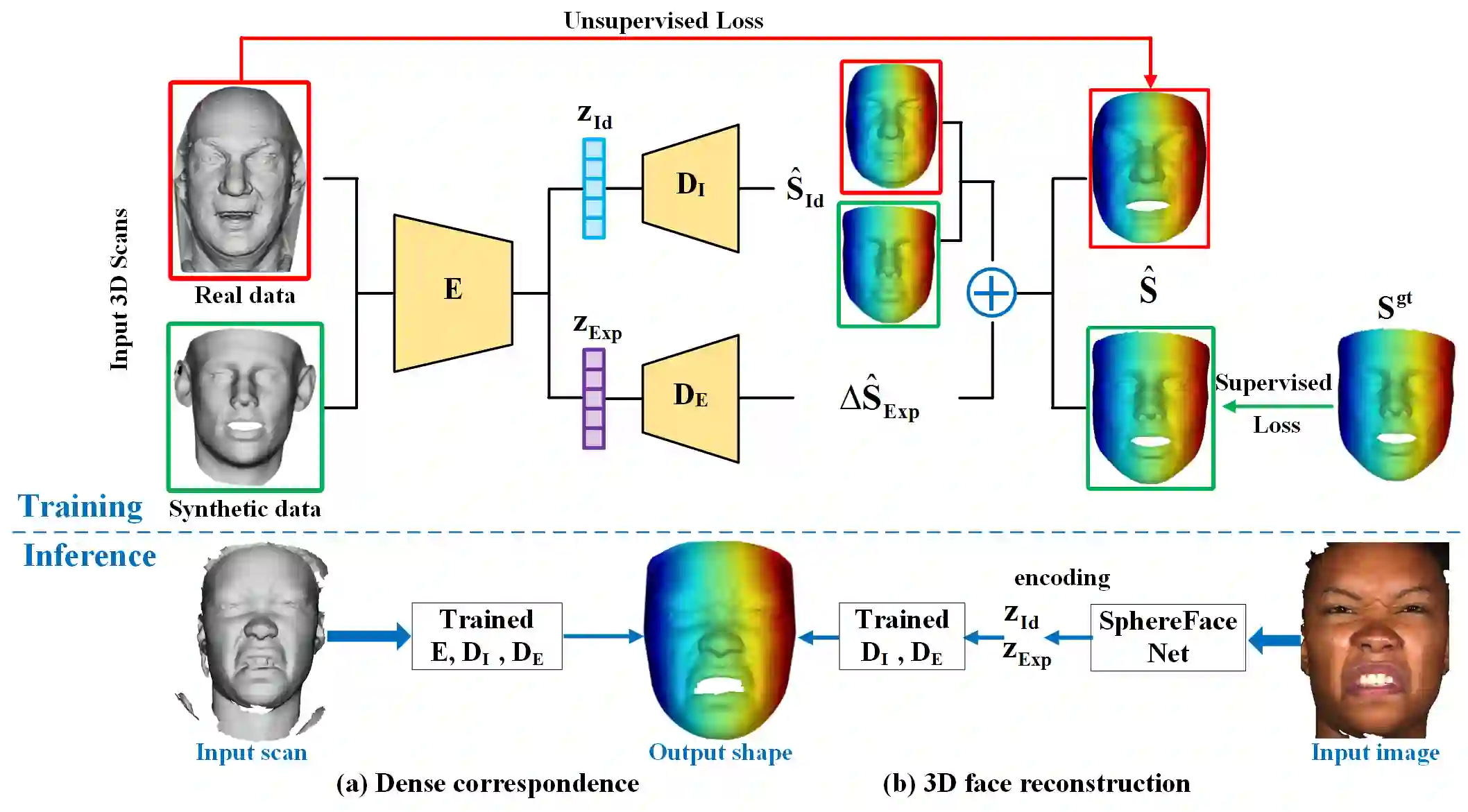
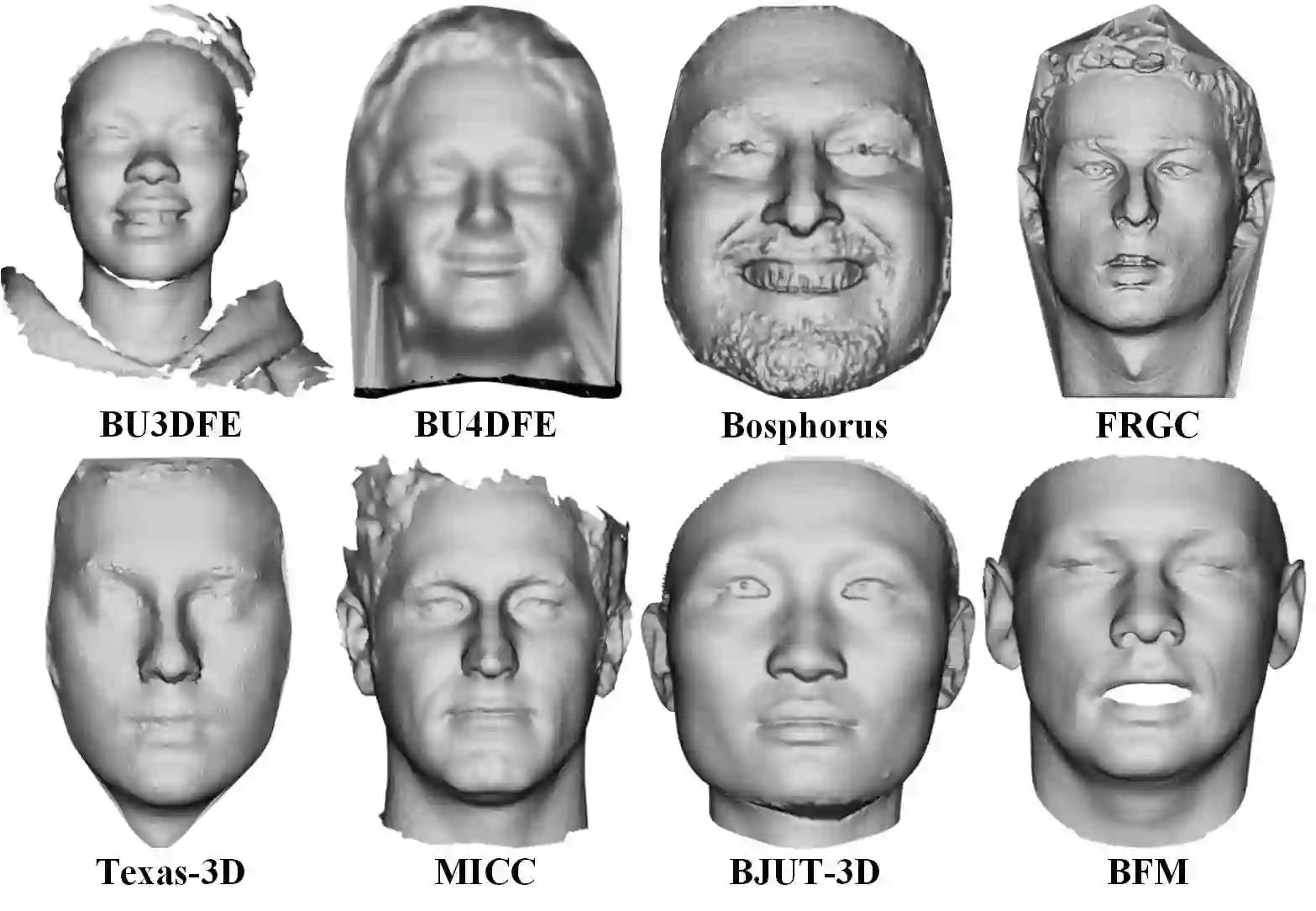
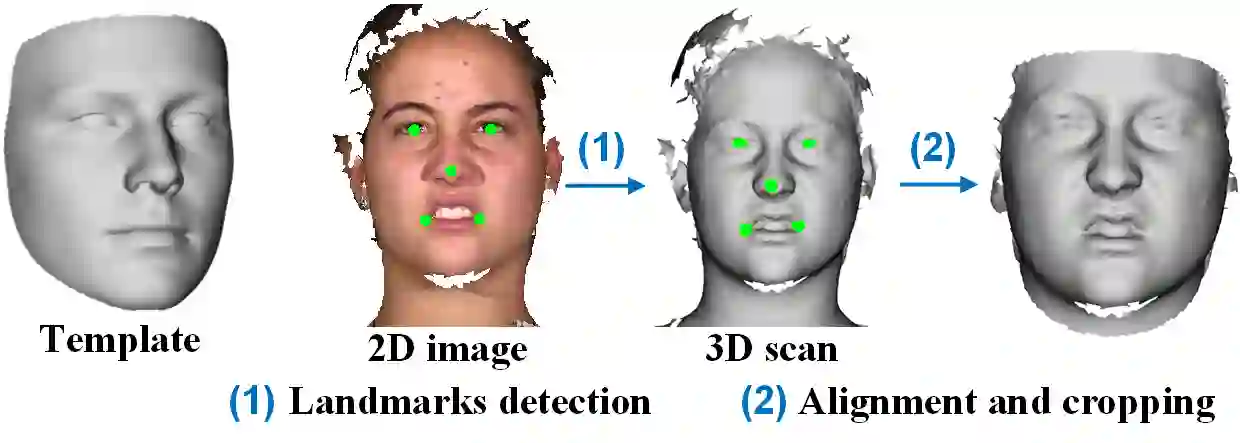
Traditional 3D models learn a latent representation of faces using linear subspaces from no more than 300 training scans of a single database. The main roadblock of building a large-scale face model from diverse 3D databases lies in the lack of dense correspondence among raw scans. To address these problems, this paper proposes an innovative framework to jointly learn a nonlinear face model from a diverse set of raw 3D scan databases and establish dense point-to-point correspondence among their scans. Specifically, by treating input raw scans as unorganized point clouds, we explore the use of PointNet architectures for converting point clouds to identity and expression feature representations, from which the decoder networks recover their 3D face shapes. Further, we propose a weakly supervised learning approach that does not require correspondence label for the scans. We demonstrate the superior dense correspondence and representation power of our proposed method in shape and expression, and its contribution to single-image 3D face reconstruction.
翻译:传统的三维模型从不超过300个单一数据库的培训扫描中,从不超过300个单一数据库的线性子空间中学习面部的潜在表现。从不同的三维数据库中建立大型面部模型的主要障碍在于原始扫描之间缺乏密集的通信。为解决这些问题,本文件提出一个创新框架,共同从多样化的一组原始三维扫描数据库中学习非线性面部模型,并在扫描中建立密集的点对点通信。具体地说,通过将输入的原始扫描作为无组织点云处理,我们探索使用点网结构将点云转换为身份和表达特征显示,使解码网络从中恢复其三维面形。此外,我们提议了一种不要求扫描需要通信标签的薄弱监督学习方法。我们展示了我们拟议方法在形状和表达上的高度密集通信和代表力,及其对单一图像3D面重建的贡献。