
自监督学习(Self-Supervised Learning)是一种介于无监督和监督学习之间的一种新范式,旨在减少对大量带注释数据的挑战性需求。它通过定义无注释(annotation-free)的前置任务(pretext task),为特征学习提供代理监督信号。jason718整理了关于自监督学习最新的论文合集,非常值得查看!
A curated list of awesome Self-Supervised Learning resources. Inspired by awesome-deep-vision, awesome-adversarial-machine-learning, awesome-deep-learning-papers, and awesome-architecture-search
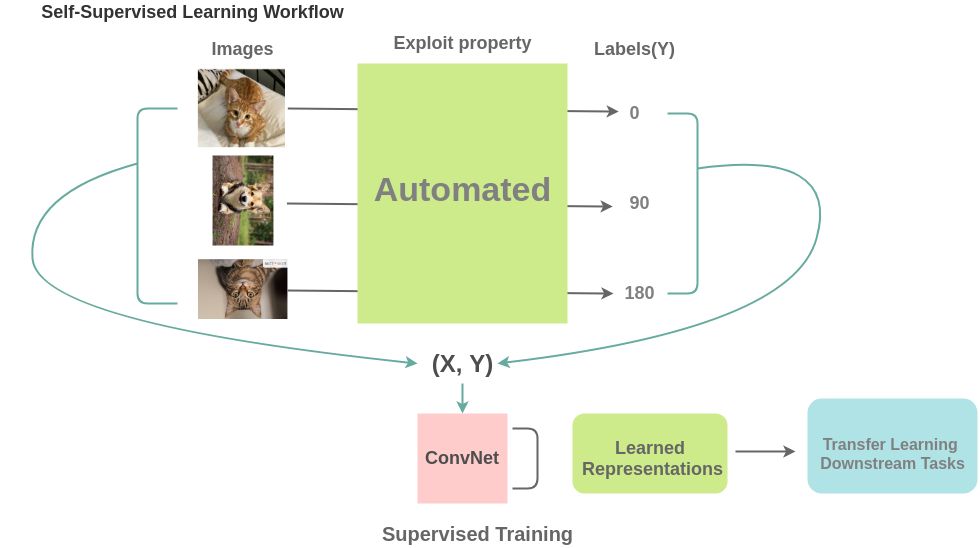
Why Self-Supervised?
Self-Supervised Learning has become an exciting direction in AI community.
- Jitendra Malik: "Supervision is the opium of the AI researcher"
- Alyosha Efros: "The AI revolution will not be supervised"
- Yann LeCun: "self-supervised learning is the cake, supervised learning is the icing on the cake, reinforcement learning is the cherry on the cake"
Contributing

Please help contribute this list by contacting me or add pull request
Markdown format:
- Paper Name.
[[pdf]](link)
[[code]](link)
- Author 1, Author 2, and Author 3. *Conference Year*
Table of Contents
- Computer Vision (CV)
- Machine Learning
- Robotics
- Natural Language Processing (NLP)
- Automatic Speech Recognition (ASR)
- Talks
- Thesis
- Blog
Computer Vision
Survey
- Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. [pdf]
- Longlong Jing and Yingli Tian.
Image Representation Learning
Benchmark code
FAIR Self-Supervision Benchmark [repo]: various benchmark (and legacy) tasks for evaluating quality of visual representations learned by various self-supervision approaches.
2015
-
Unsupervised Visual Representation Learning by Context Prediction. [pdf] [code]
- Doersch, Carl and Gupta, Abhinav and Efros, Alexei A. ICCV 2015
-
Unsupervised Learning of Visual Representations using Videos. [pdf] [code]
- Wang, Xiaolong and Gupta, Abhinav. ICCV 2015
-
Learning to See by Moving. [pdf] [code]
- Agrawal, Pulkit and Carreira, Joao and Malik, Jitendra. ICCV 2015
-
Learning image representations tied to ego-motion. [pdf] [code]
- Jayaraman, Dinesh and Grauman, Kristen. ICCV 2015
2016
-
Joint Unsupervised Learning of Deep Representations and Image Clusters. [pdf] [code-torch] [code-caffe]
- Jianwei Yang, Devi Parikh, Dhruv Batra. CVPR 2016
-
Unsupervised Deep Embedding for Clustering Analysis. [pdf] [code]
- Junyuan Xie, Ross Girshick, and Ali Farhadi. ICML 2016
-
Slow and steady feature analysis: higher order temporal coherence in video. [pdf]
- Jayaraman, Dinesh and Grauman, Kristen. CVPR 2016
-
Context Encoders: Feature Learning by Inpainting. [pdf] [code]
- Pathak, Deepak and Krahenbuhl, Philipp and Donahue, Jeff and Darrell, Trevor and Efros, Alexei A. CVPR 2016
-
Colorful Image Colorization. [pdf] [code]
- Zhang, Richard and Isola, Phillip and Efros, Alexei A. ECCV 2016
-
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. [pdf] [code]
- Noroozi, Mehdi and Favaro, Paolo. ECCV 2016
-
Ambient Sound Provides Supervision for Visual Learning. [pdf] [code]
- Owens, Andrew and Wu, Jiajun and McDermott, Josh and Freeman, William and Torralba, Antonio. ECCV 2016
-
Learning Representations for Automatic Colorization. [pdf] [code]
- Larsson, Gustav and Maire, Michael and Shakhnarovich, Gregory. ECCV 2016
-
Unsupervised Visual Representation Learning by Graph-based Consistent Constraints. [pdf] [code]
- Li, Dong and Hung, Wei-Chih and Huang, Jia-Bin and Wang, Shengjin and Ahuja, Narendra and Yang, Ming-Hsuan. ECCV 2016
2017
-
Adversarial Feature Learning. [pdf] [code]
- Donahue, Jeff and Krahenbuhl, Philipp and Darrell, Trevor. ICLR 2017
-
Self-supervised learning of visual features through embedding images into text topic spaces. [pdf] [code]
- L. Gomez* and Y. Patel* and M. Rusiñol and D. Karatzas and C.V. Jawahar. CVPR 2017
-
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. [pdf] [code]
- Zhang, Richard and Isola, Phillip and Efros, Alexei A. CVPR 2017
-
Learning Features by Watching Objects Move. [pdf] [code]
- Pathak, Deepak and Girshick, Ross and Dollar, Piotr and Darrell, Trevor and Hariharan, Bharath. CVPR 2017
-
Colorization as a Proxy Task for Visual Understanding. [pdf] [code]
- Larsson, Gustav and Maire, Michael and Shakhnarovich, Gregory. CVPR 2017
-
DeepPermNet: Visual Permutation Learning. [pdf] [code]
- Cruz, Rodrigo Santa and Fernando, Basura and Cherian, Anoop and Gould, Stephen. CVPR 2017
-
Unsupervised Learning by Predicting Noise. [pdf] [code]
- Bojanowski, Piotr and Joulin, Armand. ICML 2017
-
Multi-task Self-Supervised Visual Learning. [pdf]
- Doersch, Carl and Zisserman, Andrew. ICCV 2017
-
Representation Learning by Learning to Count. [pdf]
- Noroozi, Mehdi and Pirsiavash, Hamed and Favaro, Paolo. ICCV 2017
-
Transitive Invariance for Self-supervised Visual Representation Learning. [pdf]
- Wang, Xiaolong and He, Kaiming and Gupta, Abhinav. ICCV 2017
-
Look, Listen and Learn. [pdf]
- Relja, Arandjelovic and Zisserman, Andrew. ICCV 2017
-
Unsupervised Representation Learning by Sorting Sequences. [pdf] [code]
- Hsin-Ying Lee, Jia-Bin Huang, Maneesh Kumar Singh, and Ming-Hsuan Yang. ICCV 2017
2018
-
Unsupervised Feature Learning via Non-parameteric Instance Discrimination [pdf] [code]
- Zhirong Wu, Yuanjun Xiong and X Yu Stella and Dahua Lin. CVPR 2018
-
Learning Image Representations by Completing Damaged Jigsaw Puzzles. [pdf]
- Kim, Dahun and Cho, Donghyeon and Yoo, Donggeun and Kweon, In So. WACV 2018
-
Unsupervised Representation Learning by Predicting Image Rotations. [pdf] [code]
- Spyros Gidaris and Praveer Singh and Nikos Komodakis. ICLR 2018
-
Learning Latent Representations in Neural Networks for Clustering through Pseudo Supervision and Graph-based Activity Regularization. [pdf] [code]
- Ozsel Kilinc and Ismail Uysal. ICLR 2018
-
Improvements to context based self-supervised learning. [pdf]
- Terrell Mundhenk and Daniel Ho and Barry Chen. CVPR 2018
-
Self-Supervised Feature Learning by Learning to Spot Artifacts. [pdf] [code]
- Simon Jenni and Universität Bern and Paolo Favaro. CVPR 2018
-
Boosting Self-Supervised Learning via Knowledge Transfer. [pdf]
- Mehdi Noroozi and Ananth Vinjimoor and Paolo Favaro and Hamed Pirsiavash. CVPR 2018
-
Cross-domain Self-supervised Multi-task Feature Learning Using Synthetic Imagery. [pdf] [code]
- Zhongzheng Ren and Yong Jae Lee. CVPR 2018
-
ShapeCodes: Self-Supervised Feature Learning by Lifting Views to Viewgrids. [pdf]
- Dinesh Jayaraman*, UC Berkeley; Ruohan Gao, University of Texas at Austin; Kristen Grauman. ECCV 2018
-
Deep Clustering for Unsupervised Learning of Visual Features [pdf]
- Mathilde Caron, Piotr Bojanowski, Armand Joulin, Matthijs Douze. ECCV 2018
-
Cross Pixel Optical-Flow Similarity for Self-Supervised Learning. [pdf]
- Aravindh Mahendran, James Thewlis, Andrea Vedaldi. ACCV 2018
2019
-
Representation Learning with Contrastive Predictive Coding. [pdf]
- Aaron van den Oord, Yazhe Li, Oriol Vinyals.
-
Self-Supervised Learning via Conditional Motion Propagation. [pdf] [code]
- Xiaohang Zhan, Xingang Pan, Ziwei Liu, Dahua Lin, and Chen Change Loy. CVPR 2019
-
Self-Supervised Representation Learning by Rotation Feature Decoupling. [pdf] [code]
- Zeyu Feng; Chang Xu; Dacheng Tao. CVPR 2019
-
Revisiting Self-Supervised Visual Representation Learning. [pdf] [code]
- Alexander Kolesnikov; Xiaohua Zhai; Lucas Beye. CVPR 2019
-
AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data. [pdf] [code]
- Liheng Zhang, Guo-Jun Qi, Liqiang Wang, Jiebo Luo. CVPR 2019
-
Unsupervised Deep Learning by Neighbourhood Discovery. [pdf]. [code].
- Jiabo Huang, Qi Dong, Shaogang Gong, Xiatian Zhu. ICML 2019
-
Contrastive Multiview Coding. [pdf] [code]
- Yonglong Tian and Dilip Krishnan and Phillip Isola.
-
Large Scale Adversarial Representation Learning. [pdf]
- Jeff Donahue, Karen Simonyan.
-
Learning Representations by Maximizing Mutual Information Across Views. [pdf] [code]
- Philip Bachman, R Devon Hjelm, William Buchwalter
-
Selfie: Self-supervised Pretraining for Image Embedding. [pdf]
- Trieu H. Trinh, Minh-Thang Luong, Quoc V. Le
-
Data-Efficient Image Recognition with Contrastive Predictive Coding [pdf]
- Olivier J. He ́naff, Ali Razavi, Carl Doersch, S. M. Ali Eslami, Aaron van den Oord
-
Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty [pdf] [code]
- Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, Dawn Song. NeurIPS 2019
-
Boosting Few-Shot Visual Learning with Self-Supervision [pdf]
- pyros Gidaris, Andrei Bursuc, Nikos Komodakis, Patrick Pérez, and Matthieu Cord. ICCV 2019
-
Self-Supervised Generalisation with Meta Auxiliary Learning [pdf] [code]
- Shikun Liu, Andrew J. Davison, Edward Johns. NeurIPS 2019
-
Wasserstein Dependency Measure for Representation Learning [pdf] [code]
- Sherjil Ozair, Corey Lynch, Yoshua Bengio, Aaron van den Oord, Sergey Levine, Pierre Sermanet. NeurIPS 2019
-
Scaling and Benchmarking Self-Supervised Visual Representation Learning [pdf] [code]
- Priya Goyal, Dhruv Mahajan, Abhinav Gupta, Ishan Misra. ICCV 2019
2020
-
A critical analysis of self-supervision, or what we can learn from a single image [pdf] [code]
- Yuki M. Asano, Christian Rupprecht, Andrea Vedaldi. ICLR 2020
-
On Mutual Information Maximization for Representation Learning [pdf] [code]
- Michael Tschannen, Josip Djolonga, Paul K. Rubenstein, Sylvain Gelly, Mario Lucic. ICLR 2020
-
Understanding the Limitations of Variational Mutual Information Estimators [pdf] [code]
- Jiaming Song, Stefano Ermon. ICLR 2020
-
Automatic Shortcut Removal for Self-Supervised Representation Learning [pdf]
- Matthias Minderer, Olivier Bachem, Neil Houlsby, Michael Tschannen
-
Momentum Contrast for Unsupervised Visual Representation Learning [pdf]
- Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick. FAIR
-
A Simple Framework for Contrastive Learning of Visual Representations [pdf]
- Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
-
ClusterFit: Improving Generalization of Visual Representations [pdf]
- Xueting Yan*, Ishan Misra*, Abhinav Gupta, Deepti Ghadiyaram**, Dhruv Mahajan**. CVPR 2020
-
Self-Supervised Learning of Pretext-Invariant Representations [pdf]
- Ishan Misra, Laurens van der Maaten. CVPR 2020
Video Representation Learning
-
Unsupervised Learning of Video Representations using LSTMs. [pdf] [code]
- Srivastava, Nitish and Mansimov, Elman and Salakhudinov, Ruslan. ICML 2015
-
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification. [pdf] [code]
- Ishan Misra, C. Lawrence Zitnick and Martial Hebert. ECCV 2016
-
LSTM Self-Supervision for Detailed Behavior Analysis [pdf]
- Biagio Brattoli*, Uta Büchler*, Anna-Sophia Wahl, Martin E. Schwab, and Björn Ommer. CVPR 2017
-
Self-Supervised Video Representation Learning With Odd-One-Out Networks. [pdf]
- Basura Fernando and Hakan Bilen and Efstratios Gavves and Stephen Gould. CVPR 2017
-
Unsupervised Learning of Long-Term Motion Dynamics for Videos. [pdf]
- Luo, Zelun and Peng, Boya and Huang, De-An and Alahi, Alexandre and Fei-Fei, Li. CVPR 2017
-
Geometry Guided Convolutional Neural Networks for Self-Supervised Video Representation Learning. [pdf]
- Chuang Gan and Boqing Gong and Kun Liu and Hao Su and Leonidas J. Guibas. CVPR 2018
-
Improving Spatiotemporal Self-Supervision by Deep Reinforcement Learning. [pdf]
- Biagio Brattoli*, Uta Büchler*, and Björn Ommer. ECCV 2018
-
Self-supervised learning of a facial attribute embedding from video. [pdf]
- Wiles, O., Koepke, A.S., Zisserman, A. BMVC 2018
-
Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles. [pdf]
- Kim, Dahun and Cho, Donghyeon and Yoo, Donggeun and Kweon, In So. AAAI 2019
-
Self-Supervised Spatio-Temporal Representation Learning for Videos by Predicting Motion and Appearance Statistics. [pdf]
- Jiangliu Wang; Jianbo Jiao; Linchao Bao; Shengfeng He; Yunhui Liu; Wei Liu. CVPR 2019
-
DynamoNet: Dynamic Action and Motion Network. [pdf]
- Ali Diba; Vivek Sharma, Luc Van Gool, Rainer Stiefelhagen. ICCV 2019
-
Learning Correspondence from the Cycle-consistency of Time. [pdf] [code]
- Xiaolong Wang*, Allan Jabri* and Alexei A. Efros. CVPR 2019
-
Joint-task Self-supervised Learning for Temporal Correspondence. [pdf] [code]
- Xueting Li*, Sifei Liu*, Shalini De Mello, Xiaolong Wang, Jan Kautz, and Ming-Hsuan Yang. NIPS 2019
Geometry
-
Self-supervised Learning of Motion Capture. [pdf] [code] [web]
- Tung, Hsiao-Yu and Tung, Hsiao-Wei and Yumer, Ersin and Fragkiadaki, Katerina. NIPS 2017
-
Unsupervised Learning of Depth and Ego-Motion from Video. [pdf] [code] [web]
- Zhou, Tinghui and Brown, Matthew and Snavely, Noah and Lowe, David G. CVPR 2017
-
Active Stereo Net: End-to-End Self-Supervised Learning for Active Stereo Systems. [project]
- Yinda Zhang*, Sean Fanello, Sameh Khamis, Christoph Rhemann, Julien Valentin, Adarsh Kowdle, Vladimir Tankovich, Shahram Izadi, Thomas Funkhouser. ECCV 2018
-
Self-Supervised Relative Depth Learning for Urban Scene Understanding. [pdf] [project]
- Huaizu Jiang*, Erik Learned-Miller, Gustav Larsson, Michael Maire, Greg Shakhnarovich. ECCV 2018
-
Geometry-Aware Learning of Maps for Camera Localization. [pdf] [code]
- Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. CVPR 2018
-
Self-supervised Learning of Geometrically Stable Features Through Probabilistic Introspection. [pdf] [web]
- David Novotny, Samuel Albanie, Diane Larlus, Andrea Vedaldi. CVPR 2018
-
Self-Supervised Learning of 3D Human Pose Using Multi-View Geometry. [pdf]
- Muhammed Kocabas; Salih Karagoz; Emre Akbas. CVPR 2019
-
SelFlow: Self-Supervised Learning of Optical Flow. [pdf]
- Jiangliu Wang; Jianbo Jiao; Linchao Bao; Shengfeng He; Yunhui Liu; Wei Liu. CVPR 2019
-
Unsupervised Learning of Landmarks by Descriptor Vector Exchange. [pdf] [code] [web]
- James Thewlis, Samuel Albanie, Hakan Bilen, Andrea Vedaldi. ICCV 2019
Audio
-
Audio-Visual Scene Analysis with Self-Supervised Multisensory Features. [pdf] [code]
- Andrew Owens, Alexei A. Efros. ECCV 2018
-
Objects that Sound. [pdf]
- R. Arandjelović, A. Zisserman. ECCV 2018
-
Learning to Separate Object Sounds by Watching Unlabeled Video. [pdf] [project]
- Ruohan Gao, Rogerio Feris, Kristen Grauman. ECCV 2018
-
The Sound of Pixels. [pdf] [project]
- Zhao, Hang and Gan, Chuang and Rouditchenko, Andrew and Vondrick, Carl and McDermott, Josh and Torralba, Antonio. ECCV 2018
-
Learnable PINs: Cross-Modal Embeddings for Person Identity. [pdf] [web]
- Arsha Nagrani, Samuel Albanie, Andrew Zisserman. ECCV 2018
-
Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization. [pdf]
- Bruno Korbar,Dartmouth College, Du Tran, Lorenzo Torresani. NIPS 2018
-
Self-Supervised Generation of Spatial Audio for 360° Video. [pdf]
- Pedro Morgado, Nuno Nvasconcelos, Timothy Langlois, Oliver Wang. NIPS 2018
-
TriCycle: Audio Representation Learning from Sensor Network Data Using Self-Supervision [pdf]
- Mark Cartwright, Jason Cramer, Justin Salamon, Juan Pablo Bello. WASPAA 2019
Others
- Self-learning Scene-specific Pedestrian Detectors using a Progressive Latent Model. [pdf]
- Qixiang Ye, Tianliang Zhang, Qiang Qiu, Baochang Zhang, Jie Chen, Guillermo Sapiro. CVPR 2017
- Free Supervision from Video Games. [pdf] [project+code]
- Philipp Krähenbühl. CVPR 2018
- Fighting Fake News: Image Splice Detection via Learned Self-Consistency [pdf] [code]
- Minyoung Huh*, Andrew Liu*, Andrew Owens, Alexei A. Efros. ECCV 2018
- Self-supervised Tracking by Colorization (Tracking Emerges by Colorizing Videos). [pdf]
- Carl Vondrick*, Abhinav Shrivastava, Alireza Fathi, Sergio Guadarrama, Kevin Murphy. ECCV 2018
- High-Fidelity Image Generation With Fewer Labels. [pdf]
- Mario Lucic*, Michael Tschannen*, Marvin Ritter*, Xiaohua Zhai, Olivier Bachem, Sylvain Gelly.
- Self-supervised Fitting of Articulated Meshes to Point Clouds.
- Chun-Liang Li, Tomas Simon, Jason Saragih, Barnabás Póczos and Yaser Sheikh. CVPR 2019
- SCOPS: Self-Supervised Co-Part Segmentation.
- Wei-Chih Hung, Varun Jampani, Sifei Liu, Pavlo Molchanov, Ming-Hsuan Yang, and Jan Kautz. CVPR 2019
- Self-Supervised GANs via Auxiliary Rotation Loss.
- Ting Chen; Xiaohua Zhai; Marvin Ritter; Mario Lucic; Neil Houlsby. CVPR 2019
- Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking.
- Jae Shin Yoon; Takaaki Shiratori; Shoou-I Yu; Hyun Soo Park. CVPR 2019
- Multi-Task Self-Supervised Object Detection via Recycling of Bounding Box Annotations.
- Wonhee Lee; Joonil Na; Gunhee Kim. CVPR 2019
- Self-Supervised Convolutional Subspace Clustering Network.
- Junjian Zhang; Chun-Guang Li; Chong You; Xianbiao Qi; Honggang Zhang; Jun Guo; Zhouchen Lin. CVPR 2019
- Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation.
- Xin Wang; Qiuyuan Huang; Asli Celikyilmaz; Jianfeng Gao; Dinghan Shen; Yuan-Fang Wang; William Yang Wang; Lei Zhang. CVPR 2019
- Unsupervised 3D Pose Estimation With Geometric Self-Supervision.
- Ching-Hang Chen; Ambrish Tyagi; Amit Agrawal; Dylan Drover; Rohith MV; Stefan Stojanov; James M. Rehg. CVPR 2019
- Learning to Generate Grounded Image Captions without Localization Supervision. [pdf]
- Chih-Yao Ma; Yannis Kalantidis; Ghassan AlRegib; Peter Vajda; Marcus Rohrbach; Zsolt Kira.
- VideoBERT: A Joint Model for Video and Language Representation Learning [pdf]
- Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid. ICCV 2019
- S4L: Self-Supervised Semi-Supervised Learning [pdf]
- Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, Lucas Beyer
- Countering Noisy Labels By Learning From Auxiliary Clean Labels [pdf]
- Tsung Wei Tsai, Chongxuan Li, Jun Zhu
Machine Learning
-
Self-taught Learning: Transfer Learning from Unlabeled Data. [pdf]
- Raina, Rajat and Battle, Alexis and Lee, Honglak and Packer, Benjamin and Ng, Andrew Y. ICML 2007
-
Representation Learning: A Review and New Perspectives. [pdf]
- Bengio, Yoshua and Courville, Aaron and Vincent, Pascal. TPAMI 2013.
Reinforcement Learning
-
Curiosity-driven Exploration by Self-supervised Prediction. [pdf] [code]
- Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. ICML 2017
-
Large-Scale Study of Curiosity-Driven Learning. [pdf]
- Yuri Burda*, Harri Edwards*, Deepak Pathak*, Amos Storkey, Trevor Darrell and Alexei A. Efros
-
Playing hard exploration games by watching YouTube. [pdf]
- Yusuf Aytar, Tobias Pfaff, David Budden, Tom Le Paine, Ziyu Wang, Nando de Freitas. NIPS 2018
-
Unsupervised State Representation Learning in Atari. [pdf] [code]
- Ankesh Anand, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, R Devon Hjelm. NeurIPS 2019
Robotics
2006
-
Improving Robot Navigation Through Self-Supervised Online Learning [pdf]
- Boris Sofman, Ellie Lin, J. Andrew Bagnell, Nicolas Vandapel, and Anthony Stentz
-
Reverse Optical Flow for Self-Supervised Adaptive Autonomous Robot Navigation [pdf]
- A. Lookingbill, D. Lieb, J. Rogers and J. Curry
2009
- Learning Long-Range Vision for Autonomous Off-Road Driving [pdf]
- Raia Hadsell, Pierre Sermanet, Jan Ben, Ayse Erkan, Marco Scoffier, Koray Kavukcuoglu, Urs Muller, Yann LeCun
2012
- Self-supervised terrain classification for planetary surface exploration rovers [pdf]
- Christopher A. Brooks, Karl Iagnemma
2014
- Terrain Traversability Analysis Using Multi-Sensor Data Correlation by a Mobile Robot [pdf]
- Mohammed Abdessamad Bekhti, Yuichi Kobayashi and Kazuki Matsumura
2015
-
Online self-supervised learning for dynamic object segmentation [pdf]
- Vitor Guizilini and Fabio Ramos, The International Journal of Robotics Research
-
Self-Supervised Online Learning of Basic Object Push Affordances [pdf]
- Barry Ridge, Ales Leonardis, Ales Ude, Miha Denisa, and Danijel Skocaj
-
Self-supervised learning of grasp dependent tool affordances on the iCub Humanoid robot [pdf]
- Tanis Mar, Vadim Tikhanoff, Giorgio Metta, and Lorenzo Natale
2016
-
Persistent self-supervised learning principle: from stereo to monocular vision for obstacle avoidance [pdf]
- Kevin van Hecke, Guido de Croon, Laurens van der Maaten, Daniel Hennes, and Dario Izzo
-
The Curious Robot: Learning Visual Representations via Physical Interactions. [pdf]
- Lerrel Pinto and Dhiraj Gandhi and Yuanfeng Han and Yong-Lae Park and Abhinav Gupta. ECCV 2016
-
Learning to Poke by Poking: Experiential Learning of Intuitive Physics. [pdf]
- Agrawal, Pulkit and Nair, Ashvin V and Abbeel, Pieter and Malik, Jitendra and Levine, Sergey. NIPS 2016
-
Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours. [pdf]
- Pinto, Lerrel and Gupta, Abhinav. ICRA 2016
2017
-
Supervision via Competition: Robot Adversaries for Learning Tasks. [pdf]
- Pinto, Lerrel and Davidson, James and Gupta, Abhinav. ICRA 2017
-
Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge. [pdf] [Project]
- Andy Zeng, Kuan-Ting Yu, Shuran Song, Daniel Suo, Ed Walker Jr., Alberto Rodriguez, Jianxiong Xiao. ICRA 2017
-
Combining Self-Supervised Learning and Imitation for Vision-Based Rope Manipulation. [pdf] [Project]
- Ashvin Nair*, Dian Chen*, Pulkit Agrawal*, Phillip Isola, Pieter Abbeel, Jitendra Malik, Sergey Levine. ICRA 2017
-
Learning to Fly by Crashing [pdf]
- Dhiraj Gandhi, Lerrel Pinto, Abhinav Gupta IROS 2017
-
Self-supervised learning as an enabling technology for future space exploration robots: ISS experiments on monocular distance learning [pdf]
- K. van Hecke, G. C. de Croon, D. Hennes, T. P. Setterfield, A. Saenz- Otero, and D. Izzo
-
Unsupervised Perceptual Rewards for Imitation Learning. [pdf] [project]
- Sermanet, Pierre and Xu, Kelvin and Levine, Sergey. RSS 2017
-
Self-Supervised Visual Planning with Temporal Skip Connections. [pdf]
- Frederik Ebert, Chelsea Finn, Alex X. Lee, Sergey Levine. CoRL2017
2018
-
CASSL: Curriculum Accelerated Self-Supervised Learning. [pdf]
- Adithyavairavan Murali, Lerrel Pinto, Dhiraj Gandhi, Abhinav Gupta. ICRA 2018
-
Time-Contrastive Networks: Self-Supervised Learning from Video. [pdf] [Project]
- Pierre Sermanet and Corey Lynch and Yevgen Chebotar and Jasmine Hsu and Eric Jang and Stefan Schaal and Sergey Levine. ICRA 2018
-
Self-Supervised Deep Reinforcement Learning with Generalized Computation Graphs for Robot Navigation. [pdf]
- Gregory Kahn, Adam Villaflor, Bosen Ding, Pieter Abbeel, Sergey Levine. ICRA 2018
-
Learning Actionable Representations from Visual Observations. [pdf] [Project]
- Dwibedi, Debidatta and Tompson, Jonathan and Lynch, Corey and Sermanet, Pierre. IROS 2018
-
Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning. [pdf] [Project]
- Andy Zeng, Shuran Song, Stefan Welker, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser. IROS 2018
-
Visual Reinforcement Learning with Imagined Goals. [pdf] [Project]
- Ashvin Nair*, Vitchyr Pong*, Murtaza Dalal, Shikhar Bahl, Steven Lin, Sergey Levine.NeurIPS 2018
-
Grasp2Vec: Learning Object Representations from Self-Supervised Grasping. [pdf] [Project]
- Eric Jang*, Coline Devin*, Vincent Vanhoucke, Sergey Levine. CoRL 2018
-
Robustness via Retrying: Closed-Loop Robotic Manipulation with Self-Supervised Learning. [pdf] [Project]
- Frederik Ebert, Sudeep Dasari, Alex X. Lee, Sergey Levine, Chelsea Finn. CoRL 2018
2019
-
Learning Long-Range Perception Using Self-Supervision from Short-Range Sensors and Odometry. [pdf]
- Mirko Nava, Jerome Guzzi, R. Omar Chavez-Garcia, Luca M. Gambardella, Alessandro Giusti. Robotics and Automation Letters
-
Learning Latent Plans from Play. [pdf] [Project]
- Corey Lynch, Mohi Khansari, Ted Xiao, Vikash Kumar, Jonathan Tompson, Sergey Levine, Pierre Sermanet
2020
- Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video. [pdf] [Project]
- Oier Mees, Markus Merklinger, Gabriel Kalweit, Wolfram Burgard ICRA 2020
NLP
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. [pdf] [link]
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. NAACL 2019 Best Long Paper
-
Self-Supervised Dialogue Learning [pdf]
- Jiawei Wu, Xin Wang, William Yang Wang. ACL 2019
-
Self-Supervised Learning for Contextualized Extractive Summarization [pdf]
- Hong Wang, Xin Wang, Wenhan Xiong, Mo Yu, Xiaoxiao Guo, Shiyu Chang, William Yang Wang. ACL 2019
-
A Mutual Information Maximization Perspective of Language Representation Learning [pdf]
- Lingpeng Kong, Cyprien de Masson d'Autume, Lei Yu, Wang Ling, Zihang Dai, Dani Yogatama. ICLR 2020
-
VL-BERT: Pre-training of Generic Visual-Linguistic Representations [pdf] [code]
- Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. ICLR 2020
ASR
-
Learning Robust and Multilingual Speech Representations [pdf]
- Kazuya Kawakami, Luyu Wang, Chris Dyer, Phil Blunsom, Aaron van den Oord
-
Unsupervised pretraining transfers well across languages [pdf] [code]
- Morgane Riviere, Armand Joulin, Pierre-Emmanuel Mazare, Emmanuel Dupoux
-
wav2vec: Unsupervised Pre-Training for Speech Recognition [pdf] [code]
- Steffen Schneider, Alexei Baevski, Ronan Collobert, Michael Auli. INTERSPEECH 2019
-
vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations [pdf]
- Alexei Baevski, Steffen Schneider, Michael Auli. ICLR 2020
-
Effectiveness of self-supervised pre-training for speech recognition [pdf]
- Alexei Baevski, Michael Auli, Abdelrahman Mohamed
-
Towards Unsupervised Speech Recognition and Synthesis with Quantized Speech Representation Learning [pdf]
- Alexander H. Liu, Tao Tu, Hung-yi Lee, Lin-shan Lee
-
Self-Training for End-to-End Speech Recognition [pdf]
- Jacob Kahn, Ann Lee, Awni Hannun. ICASSP 2020
-
Generative Pre-Training for Speech with Autoregressive Predictive Coding [pdf] [code]
- Yu-An Chung, James Glass. ICASSP 2020
Talks
- The power of Self-Learning Systems. Demis Hassabis (DeepMind). [link]
- Supersizing Self-Supervision: Learning Perception and Action without Human Supervision. Abhinav Gupta (CMU). [link]
- Self-supervision, Meta-supervision, Curiosity: Making Computers Study Harder. Alyosha Efros (UCB) [link]
- Unsupervised Visual Learning Tutorial. CVPR 2018 [part 1] [part 2]
- Self-Supervised Learning. Andrew Zisserman (Oxford & Deepmind). [pdf]
- Graph Embeddings, Content Understanding, & Self-Supervised Learning. Yann LeCun. (NYU & FAIR) [pdf] [video]
- Self-supervised learning: could machines learn like humans? Yann LeCun @EPFL. [video]
- Week 9 (b): CS294-158 Deep Unsupervised Learning(Spring 2019). Alyosha Efros @UC Berkeley. [video]
Thesis
- Supervision Beyond Manual Annotations for Learning Visual Representations. Carl Doersch. [pdf].
- Image Synthesis for Self-Supervised Visual Representation Learning. Richard Zhang. [pdf].
- Visual Learning beyond Direct Supervision. Tinghui Zhou. [pdf].
- Visual Learning with Minimal Human Supervision. Ishan Misra. [pdf].
Blog
- Self-Supervised Representation Learning. Lilian Weng. [link].
- The Illustrated Self-Supervised Learning. Amit Chaudhary. [link]
License
To the extent possible under law, Zhongzheng Ren has waived all copyright and related or neighboring rights to this work.
