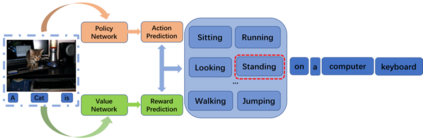
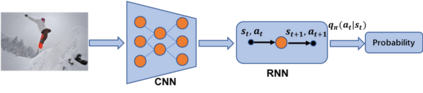
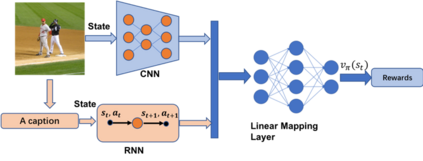
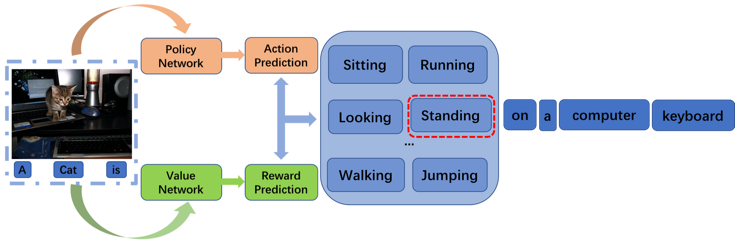
Recently it has shown that the policy-gradient methods for reinforcement learning have been utilized to train deep end-to-end systems on natural language processing tasks. What's more, with the complexity of understanding image content and diverse ways of describing image content in natural language, image captioning has been a challenging problem to deal with. To the best of our knowledge, most state-of-the-art methods follow a pattern of sequential model, such as recurrent neural networks (RNN). However, in this paper, we propose a novel architecture for image captioning with deep reinforcement learning to optimize image captioning tasks. We utilize two networks called "policy network" and "value network" to collaboratively generate the captions of images. The experiments are conducted on Microsoft COCO dataset, and the experimental results have verified the effectiveness of the proposed method.
翻译:最近,它表明,强化学习的政策梯级方法已经用于培训关于自然语言处理任务的深端端到端系统。此外,由于理解图像内容的复杂性和用自然语言描述图像内容的多种方式,图像字幕是一个棘手的问题。据我们所知,大多数最先进的方法都遵循连续模式模式,如经常性神经网络(RNN ) 。然而,在本文中,我们提出了一个新的图像标识结构,用深层强化学习来说明优化图像说明任务。我们利用两个网络“政策网络”和“价值网络”协作生成图像的字幕。实验是在微软COCO数据集上进行的,实验结果证实了拟议方法的有效性。