成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
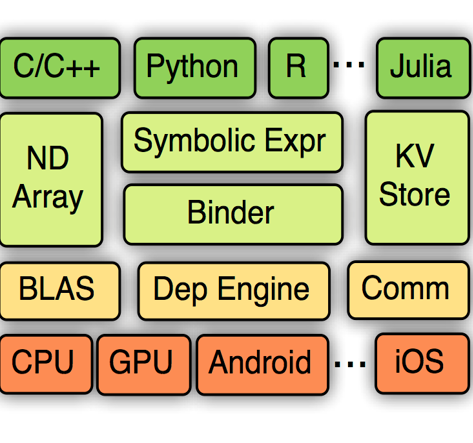
MXNet
关注
17
mxnet
综合
百科
VIP
热门
动态
论文
精华
精品内容
没有数据了, 换个别的吧!
参考链接
父主题
深度学习框架
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top