成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
Kafka
关注
162
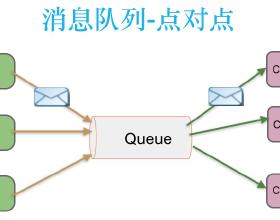
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
综合
百科
VIP
热门
动态
论文
精华
不想云厂商坐收渔翁之利,Kafka 团队修改 KSQL 开源许可
技术最前线
0+阅读 · 2018年12月16日
Kafka真的不适用于Event Sourcing
聊聊架构
2+阅读 · 2018年9月9日
基于MySQL Binlog的Elasticsearch数据同步实践
DBAplus社群
15+阅读 · 2019年9月3日
Apache Kafka 迎来了“后浪”
InfoQ
0+阅读 · 2020年5月8日
不想云厂商坐收渔翁之利,Kafka 团队修改 KSQL 开源许可
Linux爱好者
0+阅读 · 2018年12月17日
消息中间件选型分析:从Kafka与RabbitMQ的对比看全局
AI前线
0+阅读 · 2018年4月12日
必应恢复访问;苹果裁撤自动驾驶项目员工200余人;大疆因内部贪腐损失 1.5 亿美元;Kafka公司获1.5亿美元融资丨Q新闻
InfoQ
0+阅读 · 2019年1月26日
Kafka 基本原理 :15 篇热文回顾
ImportNew
2+阅读 · 2017年7月2日
浅谈分布式消息技术 Kafka
CSDN云计算
0+阅读 · 2017年7月26日
内部已使用6年!去哪儿网重磅开源消息队列QMQ
AI前线
0+阅读 · 2018年12月8日
实时流处理新选择:LinkedIn重磅发布Samza 1.0
AI前线
0+阅读 · 2018年12月3日
开源消息队列QMQ的设计与实现理念
InfoQ
1+阅读 · 2018年12月17日
LC3视角:Kubernetes下日志采集、存储与处理技术实践
云栖社区
0+阅读 · 2018年7月10日
一文追溯 ETL 的发展历程
CSDN
3+阅读 · 2020年3月30日
75%新项目都可以“无脑”选择单体架构
InfoQ
0+阅读 · 2022年2月9日
参考链接
父主题
消息队列
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top