成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
K-means算法
关注
221
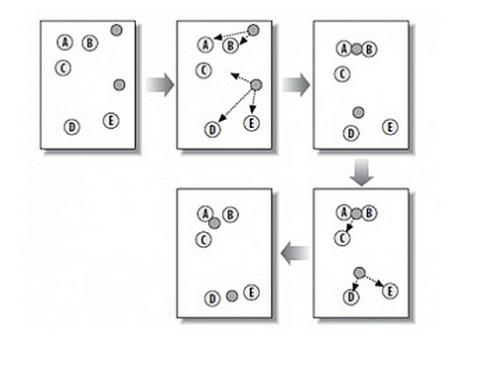
K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
综合
百科
VIP
热门
动态
论文
精华
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
AINLP
8+阅读 · 2020年7月17日
为什么聚类技术依然是数据挖掘届的泰山北斗?
AINLP
2+阅读 · 2020年4月26日
使用Python复现SIGKDD2017的PAMAE算法(并行k-medoids算法)
AINLP
0+阅读 · 2020年1月5日
一文详尽系列之K-means算法
AINLP
1+阅读 · 2019年11月23日
AI换脸技术再创新高度,DeepMind发布的VQ-VAE二代算法有多厉害?
AI100
4+阅读 · 2019年6月18日
请说说Kmeans的优化?
七月在线实验室
1+阅读 · 2019年4月19日
清华178页深度报告:一文看懂AI数据挖掘
人工智能学家
10+阅读 · 2019年2月18日
清华178页深度报告:一文看懂AI数据挖掘 | 智东西内参
智东西
0+阅读 · 2019年2月17日
R语言实现聚类kmeans
R语言中文社区
3+阅读 · 2019年2月14日
一文盘点5种聚类算法,数据科学家必备!
THU数据派
2+阅读 · 2018年12月22日
深入机器学习系列之:4-KMeans
数据猿
0+阅读 · 2018年12月12日
深入机器学习系列之:Bisecting KMeans
数据猿
0+阅读 · 2018年12月11日
如何用机器学习方法进行数据建模?(文末福利)
AI100
0+阅读 · 2018年12月4日
使用K-means算法进行客户分类
AI研习社
1+阅读 · 2018年9月25日
精选 | 2018年3月R新包推荐
R语言中文社区
0+阅读 · 2018年5月2日
参考链接
父主题
聚类分析
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top