

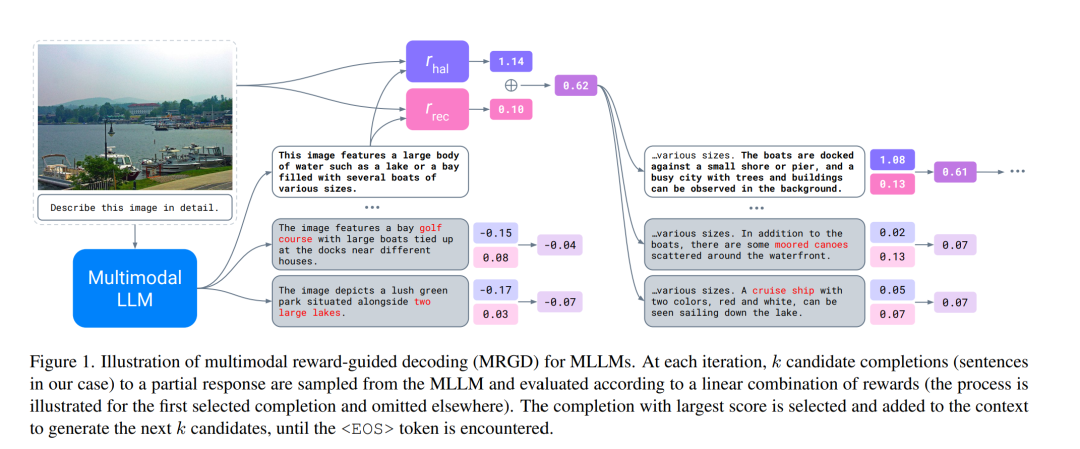
随着多模态大语言模型(Multimodal Large Language Models, MLLMs)的广泛应用,使其能够适配多样化的用户需求变得愈发重要。本文研究了通过受控解码(controlled decoding)对 MLLMs 进行适配。为此,我们提出了首个用于 MLLMs 的奖励引导解码(reward-guided decoding)方法,并展示了其在改进视觉对齐(visual grounding)方面的应用。 我们的方法核心是为视觉对齐构建奖励模型,并利用这些模型来引导 MLLM 的解码过程。具体而言,我们构建了两个独立的奖励模型,分别控制模型输出中的目标精度(object precision)与目标召回率(recall)。该方法使 MLLM 的推理过程能够在推理时(on-the-fly)实现可控性,主要体现在两方面: 1. 允许用户在解码过程中动态调整各奖励函数的重要性,从而在图像描述任务中实现目标精度与召回率之间的权衡; 1. 允许用户控制解码时的搜索广度,从而在测试时计算量与视觉对齐程度之间实现权衡。
我们在标准的目标幻觉(object hallucination)基准上评估了该方法,结果表明:该方法不仅显著提升了对 MLLM 推理过程的可控性,还在性能上持续优于现有的幻觉缓解方法。
成为VIP会员查看完整内容