

1. 引言
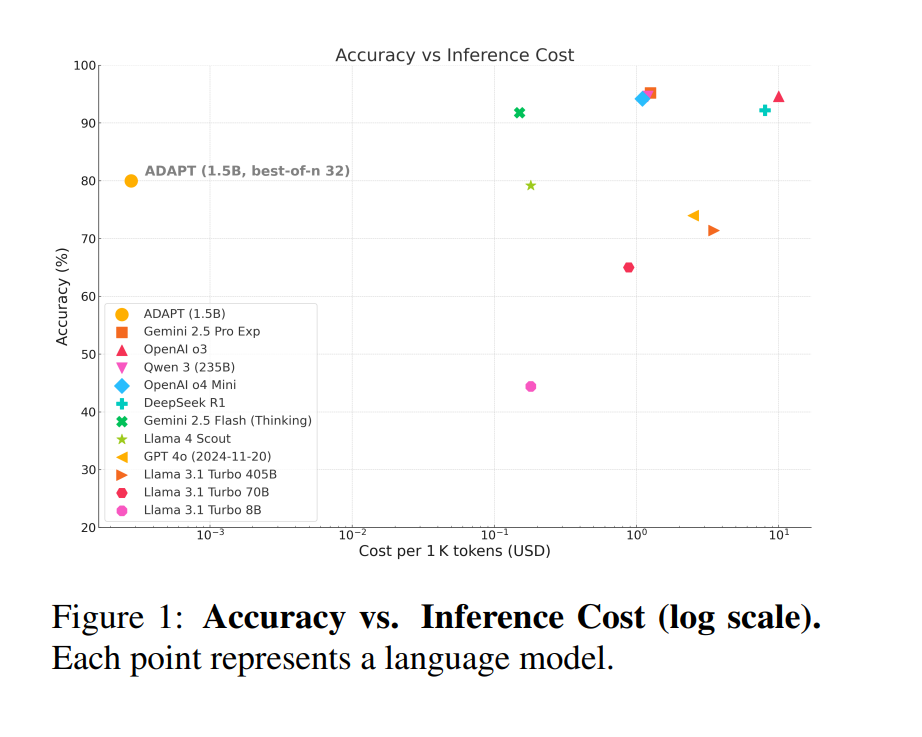
大语言模型(LLMs)(OpenAI, 2023;Chowdhery等, 2022;Touvron等, 2023)已成为现代自然语言处理(NLP)应用的核心,例如生成、翻译和问答。它们的成功主要源于基于变换器的架构(Vaswani等, 2017)和大规模预训练(Kaplan等, 2020;Hoffmann等, 2022),这赋予了模型强大的流畅性和泛化能力。然而,标准的自回归解码施加了固定的推理流程,限制了它们在复杂推理任务中的表现。 随着模型规模的增长,训练成本也随之攀升,但边际收益却在减少。为了缓解这一问题,测试时扩展(TTS)作为一个有前景的方向应运而生:它通过在推理过程中分配更多的计算资源来提升模型表现,从而使模型能够适应输入复杂性而无需重新训练(OpenAI, 2024a;Snell等, 2024;Welleck等, 2024)。尽管TTS显示出有效性,但其表现通常与模型生成多样性的内在能力密切相关,而这一因素尚未得到很好的理解或明确优化。特别是,经过推理优化的模型,如蒸馏变体,往往表现出较低的输出方差,这可能抑制TTS带来的收益。这引发了一个开放性问题:面向多样性的微调能否提升推理模型的TTS效果? 为了解决这个问题,我们首先对近期的TTS方法进行了策略导向的综述,将其分为三大类:采样(第3.1节)、搜索(第3.2节)和轨迹优化(第3.3节),并指出多样性是TTS成功的关键因素。接下来,我们提出了一种简单而有效的微调方法——ADAPT(A Diversity Aware Prefix fine-Tuning),该方法通过前缀调优采样增强了早期阶段的输出多样性。 我们在一个紧凑的推理模型上对ADAPT进行了评估,采用了最佳N采样(Best-of-N)。如图1所示,ADAPT在减少采样次数的情况下,实现了80%的准确率,在效率上超越了所有基准模型,同时保持了强大的峰值表现。 贡献
本研究做出了三项主要贡献: * 对TTS方法进行了统一综述,涵盖了采样、搜索和轨迹优化,重点讨论了生成多样性的作用。 * 设计并评估了ADAPT,一种前缀调优方法,通过增加推理中的多样性来提高效率。 * 讨论了未来的研究方向,包括对提示的鲁棒性、训练与推理的协同效应、幻觉的缓解、安全性,以及使用合成数据进行受控TTS基准测试。