如何使用自然语言工具包(NLTK)在Python3中执行情感分析

介绍
现如今生成的大量数据都是非结构化的,需要处理才能产生洞察力。非结构化数据的一些例子包括新闻文章、社交媒体上的帖子和搜索历史。分析自然语言并从中获得意义的过程属于自然语言处理(NLP)领域。情感分析是一项常见的NLP任务,它涉及到将文本或部分文本归类到一个预先定义的情感中。您将使用自然语言工具包(NLTK) ,Python中一个常用的NLP库,来分析文本数据。
在本教程中,您将使用不同的数据清理方法为NLP准备一个来自NLTK包的示例推文数据集。一旦该数据集准备好进行处理,您将在预先分类的推文上训练一个模型,并使用该模型将示例推文分类为负面和正面情感。
本文假设您熟悉Python的基础知识(请参阅我们发的《如何使用Python 3进行编码》系列教程),主要是数据结构、类和方法的使用。本教程假设您没有NLP和nltk方面的背景知识,但是有一些这方面的知识是一个额外的优势。
预备知识
本教程是基于 Python 3.6.5版本。如果您还没有安装Python3,这里有一个安装和设置Python3的本地编程环境的指南。
建议您对语言数据处理有一定的熟悉。如果您刚开始使用NLTK,请查看《如何使用自然语言工具包(NLTK)在Python 3中处理语言数据》指南。
步骤1 -安装NLTK并下载数据
在本教程中,您将使用Python中的NLTK包处理所有的NLP任务。在此步骤中,您将安装NLTK并下载将用于训练和测试模型的示例推文。

本教程将使用作为NLTK包一部分的示例推文。首先,通过运行以下命令启动一个Python交互式会话:

然后,在Python解释器中导入nltk模块。

从NLTK包下载示例推文:

从Python解释器中运行此命令在本地下载和存储推文。一旦下载了示例,您就可以使用它们了。
在本教程的后面部分,您将使用负面和正面的推文来对您的模型进行情感分析训练。没有情感的推文将被用来测试您的模型。
如果您想使用自己的数据集,您可以使用Twitter API收集特定时间段、用户或推文话题的推文。
既然您已经导入了NLTK并下载了示例推文,那么您就可以输入exit()来退出交互式会话。您现在已经准备好导入推文并开始处理数据了。
步骤2 -对数据进行词性标记
原始形式的语言不能被机器精确地处理,所以您需要对语言进行处理,以便机器更容易理解。理解数据的第一部分是通过一个称为词性标记的过程,或者将字符串分割成称为标记的更小的部分。
一个标记是文本中作为一个单元的字符序列。根据您创建标记的方式,它们可能由单词、表情符号、推文话题、链接甚至单个字符组成。将语言分解为标记的一种基本方法是根据空格和标点符号分割文本。
首先,创建一个新的.py文件用于保存您的脚本。本教程将使用nlp_test.py:

在这个文件中,您首先要导入twitter_samples,以便您可以处理这些数据:

这将从NLTK导入三个包含各种推文的数据集来训练和测试模型:
negative_tweets.json: 5000条带有负面情感的推文
positive_tweets.json: 5000条带有正面情感的推文
tweets.20150430 - 223406.json: 20000条没有情感的推文
接下来,创建positive_tweets、negative_tweets和text变量:
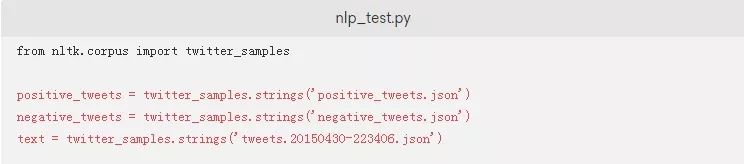
twitter_samples的strings()方法将以字符串的形式打印出一个数据集中的所有推文。将不同的推文集合设置为一个变量将使得处理和测试过程变得更容易。
在NLTK中使用标记解析器之前,您需要下载一个额外的资源——punkt。punkt模块是一个预先训练好的模型,它可以帮助您标记解析单词和句子。例如,这个模型知道一个名称可能包含一个句点(比如“S. Daityari”),并且这个句点出现在一个句子里并不一定就表示到此结束了。首先,启动一个Python交互式会话:

在会话中运行以下命令来下载punkt资源:

下载完成后,您就可以使用NLTK的标记解析器了。NLTK使用.tokenized()方法为推文提供了一个默认的标记解析器。我们添加一行代码来创建一个标记解析positive_tweets.json数据集的对象:
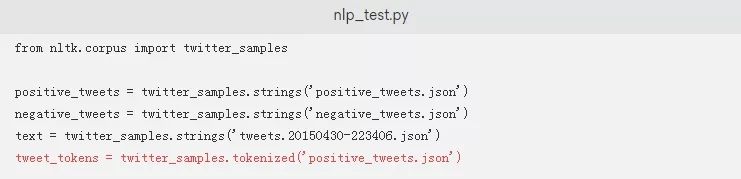
如果您想测试脚本以实际查看.tokenized方法,您只需要将突出显示的内容添加到您的nlp_test.py脚本中。这将标记解析来自positive_tweets.json数据集的一条推文:
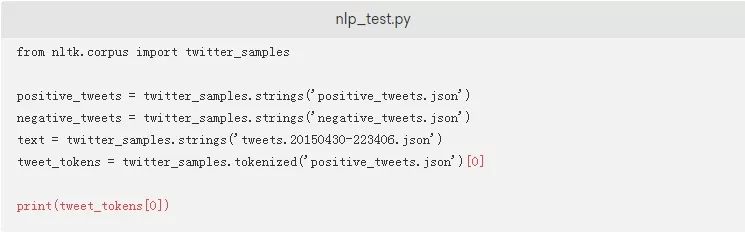
保存并关闭文件,然后运行该脚本:

标记解析过程需要一些时间,因为它不是简单地分割空格。经过几分钟的处理,您将看到以下内容:

在这里,.tokenized()方法会返回特殊字符,比如@和_。本教程稍后部分将通过正则表达式删除这些字符。
>>> 今日签到口令: gb69 <<<
既然您已经了解了.tokenized()方法的工作方式,那么请确保注释掉或删除脚本中打印标记推文的最后一行,在该行的开头添加一个#:

您的脚本现在被配置为标记解析数据了。在下一个步骤中,您将更新脚本以标准化数据。
步骤3 — 规范化数据
单词有不同的形式——例如,“ran”、“runs”和“running”是同一个动词“run”的不同形式。根据您的分析的需求,所有这些版本可能都需要被转换为相同的形式,“run”。NLP中的规范化是将一个单词转换为其简洁形式的过程。
规范化有助于将意思相同但形式不同的单词归类在一起。如果不进行规范化,“ran”、“runs”和“running”将被视为不同的单词,即使您可能希望它们被视为相同的单词。在本节中,您将探索词干提取和词性还原,它们是规范化的两种常用技术。
词干提取是去掉词缀的过程。词干提取只使用简单的动词形式,是一个删除词尾的启发式过程。
在本教程中,您将使用词形还原的过程,它通过词汇表和文本中单词的形态学分析来规范化单词。词形还原算法会分析词的结构及其上下文,并将其转换为一个规范化的形式。因此,这是以速度为代价的。词干提取和词形还原的比较最终归结为速度和准确性之间的权衡。
在开始使用词形还原之前,请在一个Python交互式会话中输入以下内容下载必要的资源:

在Python会话中运行以下命令来下载资源:

wordnet是一个英语词汇数据库,它可以帮助脚本确定词干。您需要averaged_perceptron_tagger资源来确定一个句子中单词的上下文。
下载之后,您几乎就可以使用词形还原器了。在运行词形还原器之前,您需要确定您的文本中每个单词的上下文。这是通过一个标记算法实现的,该算法会评估一个单词在句子中的相对位置。在一个Python会话中,导入pos_tag函数,并提供一个标记列表作为参数来获取标签。我们来在Python中试一下:

下面是pos_tag函数的输出。

以下是标签列表中最常见的项目及其含义:
NNP: 专有名词,单数形式
NN: 常用名词,单数形式
IN: 介词或从属连词
VBG: 动名词和现在分词
VBN: 过去分词
这里是该数据集的一个完整列表。(https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html )
一般来说,如果一个标签以NN开头,这个词就是名词,如果它以VB开头,这个词就是动词。查看这些标签之后,通过输入exit()退出Python会话。
要将其合并到一个规范化句子的函数中,您应该首先为文本中的每个标记生成标签,然后使用该标签对每个单词进行词形还原。
使用下面的函数来更新nlp_test.py文件,该函数会对一个句子进行词形还原:
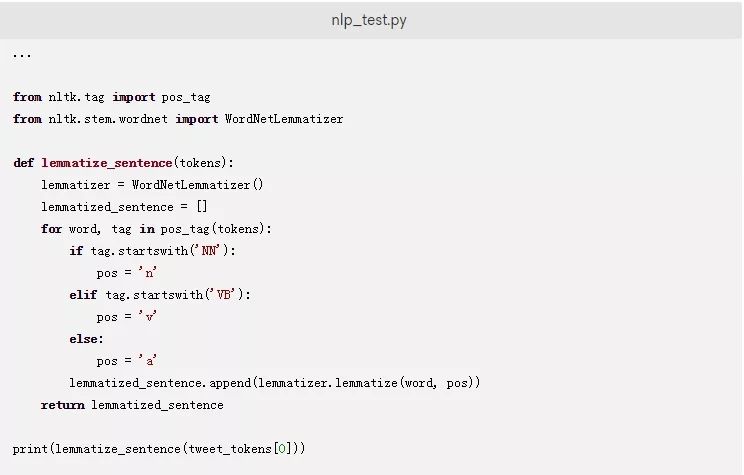
这段代码导入了WordNetLemmatizer类并将其初始化给一个变量, lemmatizer。
lemmatize_sentence函数首先获取一个推文的每个标记的位置标签。在if语句块中,如果标签以NN开头,则标记被指定为名词。类似地,如果标签以VB开头,则标记被指定为动词。
保存并关闭文件,然后运行该脚本:

下面是输出:

您会注意到动词being变成了它的词根形式,即be,名词members变成了member。在继续之前,请注释掉脚本中打印示例推文的最后一行。
现在,您已经成功地创建了一个用于规范化单词的函数,接下来就可以移除噪声了。
步骤4 -从数据中移除噪声
在此步骤中,您将从数据集中移除噪声。噪声是指文本中没有对数据添加意义或信息的任何部分。
噪声是特定于每个项目的,所以,在一个项目中构成噪声的部分可能在一个不同的项目中并不构成噪声。例如,一门语言中最常见的单词被称为停止词。停止词的例子有“is”、“the”和“a”。在处理语言时,它们通常是不相关的,除非特定的用例需要包含它们。
在本教程中,您将使用Python中的正则表达式来搜索和删除这些项:
超链接——Twitter中的所有超链接都被转换为网址缩写器t.co。因此,将它们保留在文本处理中不会给分析增加任何价值。
回复中的Twitter句柄——这些Twitter用户名前面被放置了一个@符号,它没有任何含义。
标点符号和特殊字符——虽然这些通常对文本数据提供上下文,但这种上下文通常很难处理。为了简单起见,您将从推文中删除所有标点符号和特殊字符。
要删除超链接,您需要首先搜索一个与以http://或https://开头,后面跟着字母、数字或特殊字符的URL相匹配的子字符串。一旦匹配了一个模式,.sub()方法就会用一个空字符串替换它。
因为我们将在remove_noise()函数中规范化单词形式,所以您可以从脚本中注释掉lemmatize_sentence()函数。
将以下代码添加到您的nlp_test.py文件中来从数据集中去除噪声:
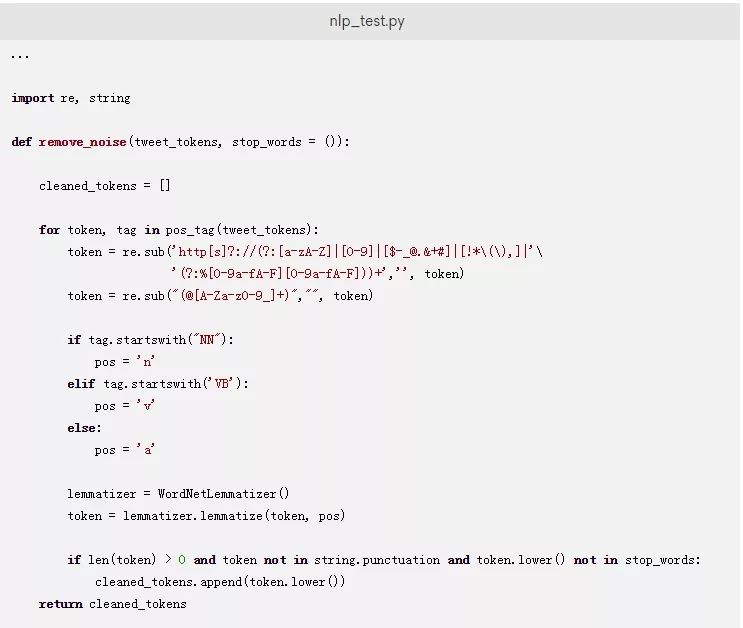
这段代码创建了一个remove_noise()函数,该函数会移除噪声并合并前一节中提到的规范化和词形还原过程。此代码接受两个参数:推文标记和停止词组成的元组。
然后,此代码会使用一个循环来从数据集中移除噪声。要删除超链接,此代码首先会搜索一个与以http://或https://开头,后跟字母、数字或特殊字符的URL相匹配的子字符串。一旦匹配到一个模式,.sub()方法就会用一个空字符串或’’替换它。
类似地,要删除@提及,该代码会使用正则表达式替换文本的相关部分。该代码会使用re库搜索@符号,后面跟着数字、字母或_,并用一个空字符串替换它们。
最后,您可以使用string库删除标点符号。
除此之外,您还将使用NLTK中内置的停止词集来删除停止词,这个停止词集需要单独下载。
在一个Python交互式会话中执行以下命令来下载这个资源:

下载该资源后,退出交互式会话。
您可以使用.words()方法来获得一个英语停止词列表。要测试这个函数,让我们在我们的示例推文上来运行它。在nlp_test.py文件的末尾添加以下行:
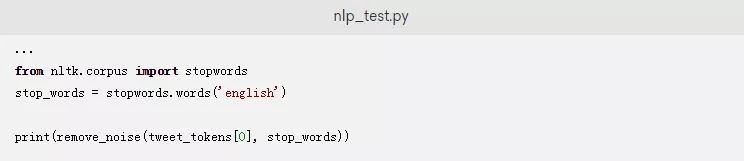
保存并关闭该文件后,再次运行脚本以收到类似如下的输出:

注意,该函数删除了所有的@提及、停止词,并将这些单词转换为小写。
在进行下一步的建模练习之前,我们使用remove_noise()函数来清理积极和消极的推文。注释掉打印示例推文上的remove_noise()输出的行,并将以下内容添加到nlp_test.py脚本中:
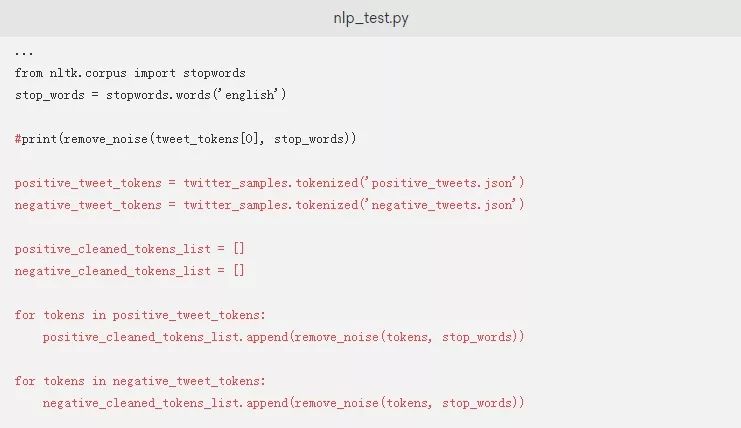
现在您已经添加了清理示例推文的代码,您可能想要比较一下一个示例推文的原始标记和清理后的标记。如果您想测试这个,将以下代码添加到脚本文件中来比较示例推文列表中第500条推文的两个版本:

保存并关闭文件,然后运行该脚本。从输出中您会看到标点符号和链接已经被删除,单词也已经被转换为小写了。

在文本预处理过程中可能会出现一些问题。例如,没有空格的单词(“iLoveYou”)将被视为一个单词,而且将这些单词分开会很困难。此外,该脚本会将“Hi”、“Hii”和“Hiiiii”当成不同的单词看待,除非您编写一些特定的东西来处理这个问题。对特定的数据的噪声去除过程进行微调是很常见的。
现在您已经用实例查看了remove_noise()函数,请一定要注释掉或者删除脚本中的最后两行,这样您就可以向它添加更多的内容:

在这一步骤中,您从数据中移除了噪声,以使分析更加有效。在下一个步骤中,您将对数据进行分析,从而找出您的示例数据集中最常见的单词。
步骤5 -确定单词密度
文本数据分析的最基本形式是提取单词频率。一个实体中的单个推文太小,无法找出单词的分布情况,因此,要对所有正面推文的单词频率进行分析。
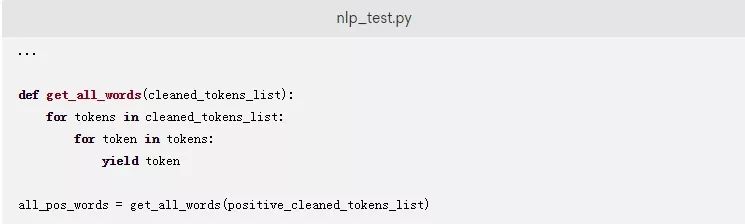
下面的代码段定义了一个名为get_all_words的生成器函数,该函数以一个推文列表作为参数,以提供一个将所有推文标记中的单词结合起来的单词列表。将以下代码添加到您的nlp_test.py文件中:
现在您已经编译了推文示例中的所有单词,您可以使用NLTK的FreqDist类找出最常见的单词。将以下代码添加到nlp_test.py文件中:

.most_common()方法会列出数据中出现频率最高的单词。完成这些更改后保存并关闭文件。
当您现在运行文件时,您将会发现数据中最常见的词语:

从这个数据中,您可以看到emoticon实体构成了正面推文的一些最常见的部分。在继续下一步骤之前,请确保您注释掉了脚本中打印前10个标记的最后一行。
总结一下就是,您从nltk中提取了推文,对其进行标记化、规范化并进行了清理,以便在模型中使用。最后,您还查看了数据中标记的频率,并检查了前10个标记的频率。
下一步,您将为情感分析准备数据。
步骤6 -为模型准备数据
情感分析是识别作者对所写主题的一个态度的过程。您将创建一个训练数据集来训练一个模型。它是一个监督学习机器学习过程,要求您将每个数据集与一个“情感”相关联来进行训练。在本教程中,您的模型将使用“正面”和“负面”情感。
情感分析可用于将文本分类为各种情感。为了训练数据集的简单性和可用性,本教程仅使用正面和负面两个类别来帮助您训练您的模型。
模型是使用规则和方程对系统的描述。它可能是一个简单的方程,根据身高预测一个人的体重。您将构建的情感分析模型将把推文与一个正面或负面情感联系起来。您需要将您的数据集分成两部分。第一部分的目的是构建模型,而下一部分的目的是测试该模型的性能。
在数据准备步骤中,您将通过将标记转换为字典形式来准备用于情绪分析的数据,然后将数据进行分割以用于训练和测试目的。
将标记转换为一个字典
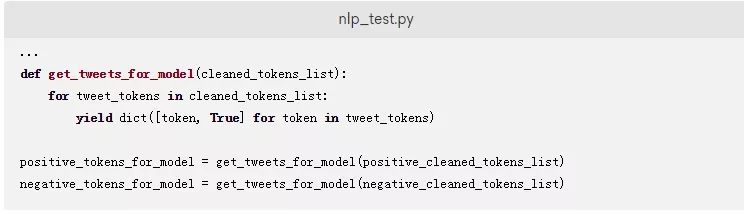
首先,您将准备要输入模型的数据。您将使用NLTK中的朴素贝叶斯分类器来执行建模练习。注意,该模型不仅需要一个推文中的单词列表,还需要一个以单词为键、以True为值的Python字典。下面的函数会创建一个生成器函数来更改已清理数据的格式。
添加以下代码,将推文从一个已清理的标记列表转换为以键作为标记、以True作为值的字典。对应的字典被存储在positive_tokens_for_model和negative_tokens_for_model中。
分割数据集以训练和测试模型
接下来,您需要准备训练NaiveBayesClassifier类的数据。添加以下代码到文件中来准备数据:
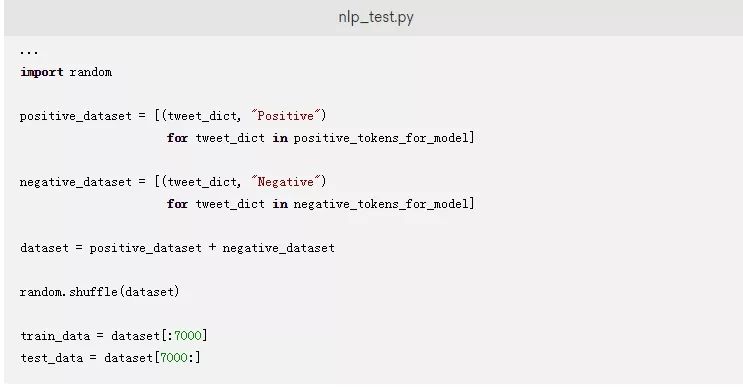
这段代码给每条推文贴上一个Positive或Negative的标签。然后,它通过连接正面和负面的推文来创建一个dataset。
默认情况下,该数据包含所有正面的推文,然后依次跟着所有负面的推文。在训练模型时,您应该提供一个不包含任何偏差的您的数据样本。为了避免偏差,您已经添加了使用random的.shuffle()方法来随机排列数据的代码。
最后,该代码将打乱的数据按70:30的比例进行分割以分别用于训练和测试。由于推文的数量是10000,您可以使用打乱的数据集的前7000条推文来训练模型,而使用最后3000条推文来测试模型。
在此步骤中,您将清理后的标记转换为一个字典形式,随机打乱该数据集,并将其分割为训练和测试数据。
步骤7 -构建和测试模型
最后,您可以使用NaiveBayesClassifier类来构建模型。使用.train()方法来训练该模型,使用.accuracy()方法在测试数据上测试该模型。
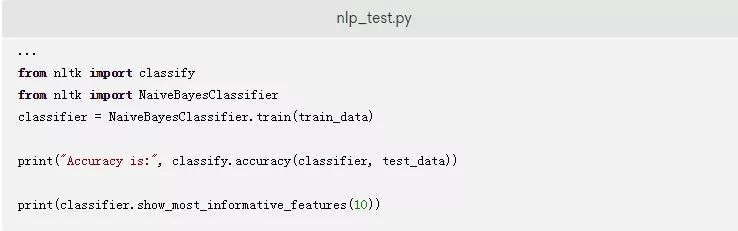
在添加代码之后保存、关闭和执行脚本文件。代码的输出如下:
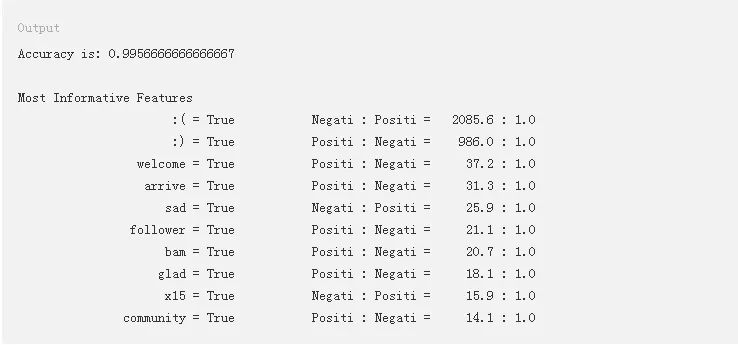
准确度被定义为该模型能够正确预测情感的测试数据集中推文的百分比。在测试集上能得到一个99.5%的准确度是相当不错的。
在显示信息性特征的表格中,输出中的每一行都显示了训练数据集中标签为正面和负面的推文中一个标记出现的比率。数据中的第一行表明所有的推文中都包含标记:(,负面推文与正面推文之比为2085.6:1)。有趣的是,正面数据集中似乎有一个带有:(的标记。您可以看到,文本中最具辨识度的两个项目是表情符号。此外,像sad这样的词会导致负面情感,而welcome和glad则与正面情感相关。
接下来,您可以检查模型对来自Twitter的随机推文的执行情况。将这段代码添加到文件中:

这段代码将允许您通过更新与custom_tweet变量相关联的字符串来测试自定义推文。完成这些更改后保存并关闭文件。
运行该脚本来分析自定义文本。下面是例子中的自定义文本的输出:

您也可以检查它是否正确地描述了正面推文:

下面是输出:

您已经测试了正面情感和负面情感,那我们再更新变量来测试更复杂的情感,比如讽刺。

下面是输出:

该模型将此示例归类为正面。这是因为训练数据不够全面,无法将讽刺推文归类为负面。如果您想要您的模型预测讽刺,您需要提供足够的训练数据来训练它。
在这一步骤中,您构建并测试了模型。您还探索了它的一些限制,比如在特定的例子中不能检测出讽刺。从本教程来说,您完成的代码仍然还有些工作要做,因此下一个步骤将指导您根据Python的最佳实践调整代码。
步骤8 -清理代码(可选)
虽然您已经完成了本教程,但还是建议您重新组织nlp_test.py文件中的代码,以遵循最佳编程实践。根据最佳实践,您的代码应该满足以下标准:
所有导入应该位于文件的顶部。来自同一个库的导入应该归类在一个单独语句块中。
所有函数应该在导入之后进行定义。
文件中的所有语句块都应放置在一个 if __name__ == "__main__":condition下面.这可以确保您在另一个文件中导入该文件中的函数时,其中的语句块不会被执行。
我们还将删除本教程中注释掉的代码和lemmatize_sentence函数,因为词形还原是由新的remove_noise函数来完成的。
下面是nlp_test.py清理后的版本:



结论
本教程指导您在Python 3中使用nltk库构建了一个基本的情感分析模型。首先,您通过标记化一条推文、对单词进行规范化并移除噪声,来对推文执行预处理。接下来,您可视化了数据中经常出现的项。最后,您构建了一个模型来将推文与一个特定的情感关联起来。
一个监督学习模型的好坏取决于它的训练数据。为了进一步强化该模型,您可以考虑添加更多的类别,如兴奋和愤怒。在本教程中,通过构建一个基本模型,您只了解了一些皮毛。这里有一个指南,详细介绍了在进行情感分析时必须注意的各种注意事项。(地址:https://monkeylearn.com/sentiment-analysis/ )
英文原文:https://www.digitalocean.com/community/tutorials/how-to-perform-sentiment-analysis-in-python-3-using-the-natural-language-toolkit-nltk
译者:Nothing