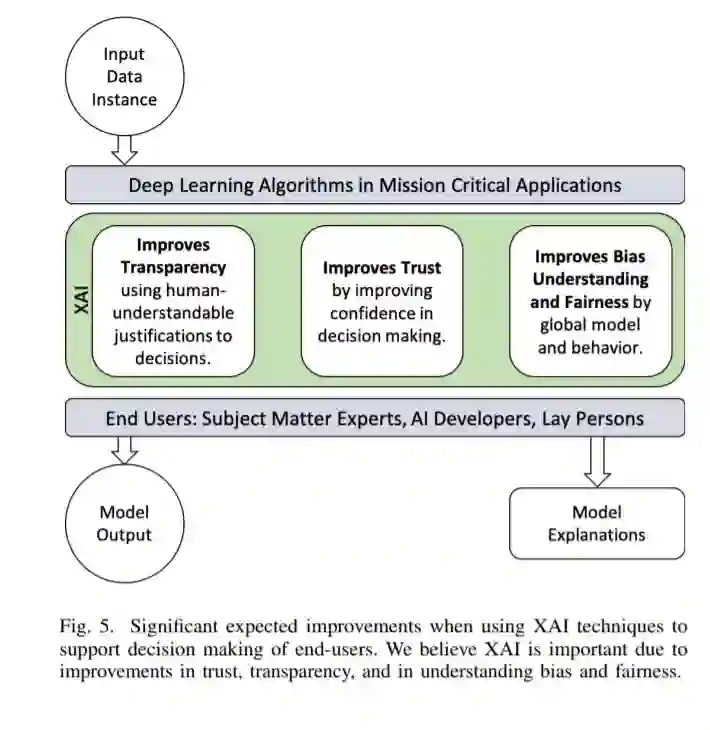
目前,深度神经网络广泛应用于医疗、自动驾驶汽车、军事等直接影响人类生活的关键任务系统。然而,深度神经网络的黑箱特性对其在关键任务应用中的应用提出了挑战,引发了道德和司法方面的担忧,导致信任缺失。可解释人工智能(XAI)是人工智能(AI)的一个领域,它促进了一套工具、技术和算法,可以生成高质量的可解释的、直观的、人类可以理解的人工智能决策解释。除了在深度学习中提供当前XAI景观的整体视图外,本文还提供了开创性工作的数学总结。首先,我们根据XAI技术的解释范围、算法背后的方法论以及有助于构建可信、可解释和自解释的深度学习模型的解释级别或用法,提出了一种分类和分类方法。然后,我们描述了在XAI研究中使用的主要原则,并给出了2007年至2020年XAI里程碑式研究的历史时间表。在详细解释了每一类算法和方法之后,我们对8种XAI算法在图像数据上生成的解释图进行了评估,讨论了该方法的局限性,并为进一步改进XAI评估提供了潜在的方向。
基于人工智能(AI)的算法,尤其是使用深度神经网络的算法,正在改变人类完成现实任务的方式。近年来,机器学习(ML)算法在科学、商业和社会工作流的各个方面的自动化应用出现了激增。这种激增的部分原因是ML领域(被称为深度学习(DL))研究的增加,在深度学习中,数千(甚至数十亿)个神经元参数被训练用于泛化执行特定任务。成功使用DL算法在医疗(Torres2018, Lee2019, Chen2020)、眼科(Sayres2019、Das2019 Son2020],发育障碍(MohammadianRad2018、Heinsfeld2018 Silva2020Temporal],在自主机器人和车辆(You2019、Grigorescu2019 Feng2020],在图像处理的分类和检测[Sahba2018 Bendre2020Human], 在语音和音频处理(Boles2017, Panwar2017),网络安全(Parra2020Detecting, Chacon2019Deep), 还有更多DL算法在我们日常生活中被成功应用。
深度神经网络中大量的参数使其理解复杂,不可否认地更难解释。不管交叉验证的准确性或其他可能表明良好学习性能的评估参数如何,深度学习(DL)模型可能天生就能从人们认为重要的数据中学习表示,也可能无法从这些数据中学习表示。解释DNNs所做的决策需要了解DNNs的内部运作,而非人工智能专家和更专注于获得准确解决方案的最终用户则缺乏这些知识。因此,解释人工智能决策的能力往往被认为是次要的,以达到最先进的结果或超越人类水平的准确性。
对XAI的兴趣,甚至来自各国政府,特别是欧洲通用数据保护条例(GDPR) [AIHLEG2019]的规定,显示出AI的伦理[Cath2017, Keskinbora2019, Etzioni2017, Bostrom2014, stahl2018ethics], trust [Weld2019, Lui2018, Hengstler2016], bias [Chen2019Hidden, Challen2019, Sinz2019, Osoba2017]的重要实现,以及对抗性例子[Kurakin2016, Goodfellow2015, Su2019, Huang2017]在欺骗分类器决策方面的影响。在[Miller2019], Miller等人描述了好奇心是人们要求解释具体决策的主要原因之一。另一个原因可能是为了促进更好的学习——重塑模型设计并产生更好的结果。每种解释都应该在相似的数据点上保持一致,并且随着时间的推移对同一数据点产生稳定或相似的解释[Sokol2020]。解释应该使人工智能算法表达,以提高人类的理解能力,提高决策的信心,并促进公正和公正的决策。因此,为了在ML决策过程中保持透明度、信任和公平性,ML系统需要一个解释或可解释的解决方案。
解释是一种验证人工智能代理或算法的输出决策的方法。对于一个使用显微图像的癌症检测模型,解释可能意味着一个输入像素的地图,这有助于模型输出。对于语音识别模型,解释可能是特定时间内的功率谱信息对当前输出决策的贡献较大。解释也可以基于参数或激活的训练模型解释或使用代理,如决策树或使用梯度或其他方法。在强化学习算法的背景下,一个解释可能会给出为什么一个代理做了一个特定的决定。然而,可解释和可解释的人工智能的定义通常是通用的,可能会引起误解[Rudin2019],应该整合某种形式的推理[Doran2018]。
AI模型的集合,比如决策树和基于规则的模型,本质上是可解释的。但是,与深度学习模型相比,存在可解释性与准确性权衡的缺点。本文讨论了研究人员解决深度学习算法可解释性问题的不同方法和观点。如果模型参数和体系结构是已知的,方法可以被有效地使用。然而,现代基于api的人工智能服务带来了更多的挑战,因为该问题的相对“黑箱”(Castelvecchi2016)性质,即终端用户只掌握提供给深度学习模型的输入信息,而不是模型本身。
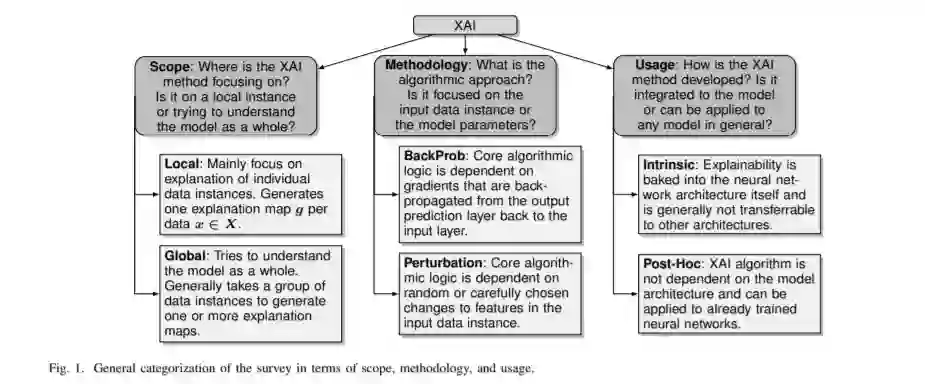
在这个综述中,我们提供了一个可解释算法的全面概述,并将重要事件的时间轴和研究出版物划分为三个定义完好的分类,如图1所示。不像许多其他的综述,只分类和总结在一个高水平上发表的研究,我们提供额外的数学概述和算法的重大工作在XAI领域。调查中提出的算法被分成三个定义明确的类别,下面将详细描述。文献中提出的各种评价XAI的技术也进行了讨论,并讨论了这些方法的局限性和未来的发展方向。
我们的贡献可以概括如下:
-
为了系统地分析深度学习中可解释和可解释的算法,我们将XAI分类为三个定义明确的类别,以提高方法的清晰度和可访问性。
-
我们审查,总结和分类的核心数学模型和算法,最近XAI研究提出的分类,并讨论重要工作的时间。
-
我们生成并比较了八种不同XAI算法的解释图,概述了这种方法的局限性,并讨论了使用深度神经网络解释来提高信任、透明度、偏差和公平的未来可能的方向。