导读 随着人工智能技术的快速进步,特别是在视频和图像生成领域,新技术的出现正在不断地推动行业的发展边界。本次讨论聚焦于 Sora 技术以及其在视频生成中的应用,探讨了文生视频中我们会面临的难点,以及腾讯在这些方面的努力与解决思路。同时,文章给出了一些文生视频的典型案例,以及对该领域未来的畅想和讨论。今天的介绍会围绕下面五点展开:
- 快速发展的文生视频
- 视频生成的主要难点
- 视频生成的应用实践
- 一些不太长远的展望
- 问答环节 分享嘉宾|刘孟洋博士 腾讯 算法工程师 编辑整理|罗锦波 内容校对|李瑶 出品社区|DataFun
01****快速发展的文生视频
在当前的人工智能领域,文生视频技术有着引人注目的进展。该技术的核心任务非常明确,就是利用文本指令来控制视频内容的生成。具体而言,用户可以输入特定文本,系统则根据这段文本生成相应的视觉画面。这一过程并不局限于单一的输出,相同的文本可能会引导生成多种不同的视觉场景,显示出该技术的灵活性和多样性。
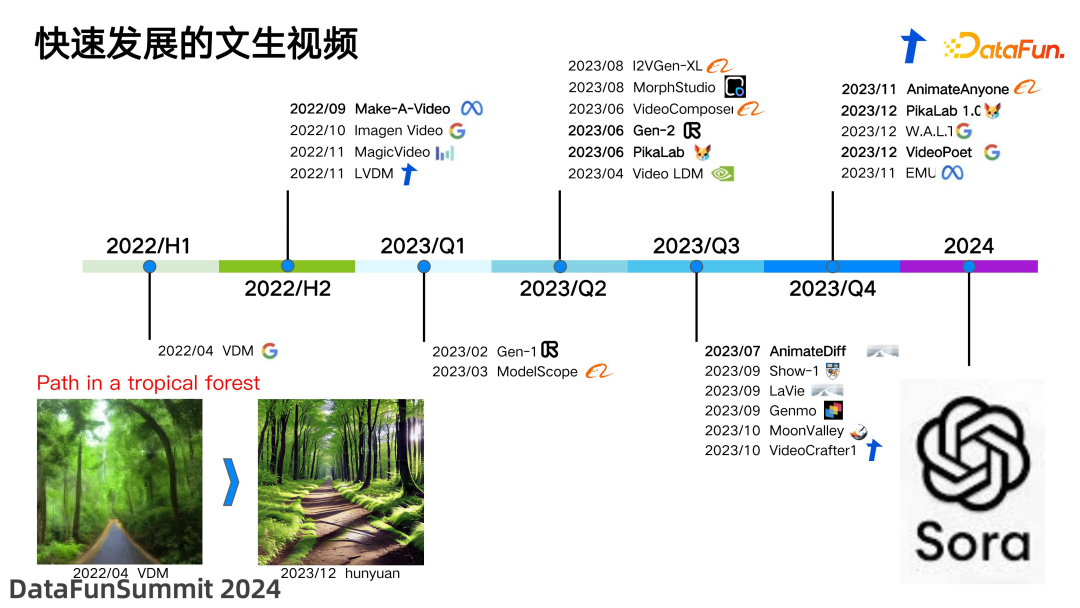
![]() 基于扩散模型模式的视频生成技术,是从 2022 年上半年才开始出现的。在两年的时间里,这一技术取得了显著的进步。由上图中可以看到,从 Google 在2022 年 4 月发布的文章所展示的效果,到腾讯在 2023 年 12 月发布的 hunyuan 的效果,无论在画质、光影的重建,还是整个画面的连续性上,都实现了显著的提升。在过去两年间,这一领域吸引了众多参与者,包括各大公司和研究机构,比如上海人工智能研究院,以及一些高校。在这个赛道中,诞生了许多引人注目的成果。从最初的 VDM 模型,到我们常听到的老玩家 Runway Gen1 和 Gen2 的工作,以及去年备受关注的 PikaLab。PikaLab 由两位华人女性科学家创立,它的上市甚至引发了中国 A 股市场上某些股票的剧烈波动。此外,还有腾讯之前的 VideoCrafter 系列,以及阿里的 ModelScope 系列等。当然,最让人印象深刻的是在今年 2 月 15 日,OpenAI 发布了颇具影响力的 Sora 模型。这款 Sora 模型的出现,使得其它模型相比之下显得普通了许多。我们当时还在纠结于生成 4 秒到 8 秒的视频,而 Sora 模型直接将视频生成的时长扩展到了 1 分钟。这一突破显著提升了视频生成技术的能力。
基于扩散模型模式的视频生成技术,是从 2022 年上半年才开始出现的。在两年的时间里,这一技术取得了显著的进步。由上图中可以看到,从 Google 在2022 年 4 月发布的文章所展示的效果,到腾讯在 2023 年 12 月发布的 hunyuan 的效果,无论在画质、光影的重建,还是整个画面的连续性上,都实现了显著的提升。在过去两年间,这一领域吸引了众多参与者,包括各大公司和研究机构,比如上海人工智能研究院,以及一些高校。在这个赛道中,诞生了许多引人注目的成果。从最初的 VDM 模型,到我们常听到的老玩家 Runway Gen1 和 Gen2 的工作,以及去年备受关注的 PikaLab。PikaLab 由两位华人女性科学家创立,它的上市甚至引发了中国 A 股市场上某些股票的剧烈波动。此外,还有腾讯之前的 VideoCrafter 系列,以及阿里的 ModelScope 系列等。当然,最让人印象深刻的是在今年 2 月 15 日,OpenAI 发布了颇具影响力的 Sora 模型。这款 Sora 模型的出现,使得其它模型相比之下显得普通了许多。我们当时还在纠结于生成 4 秒到 8 秒的视频,而 Sora 模型直接将视频生成的时长扩展到了 1 分钟。这一突破显著提升了视频生成技术的能力。
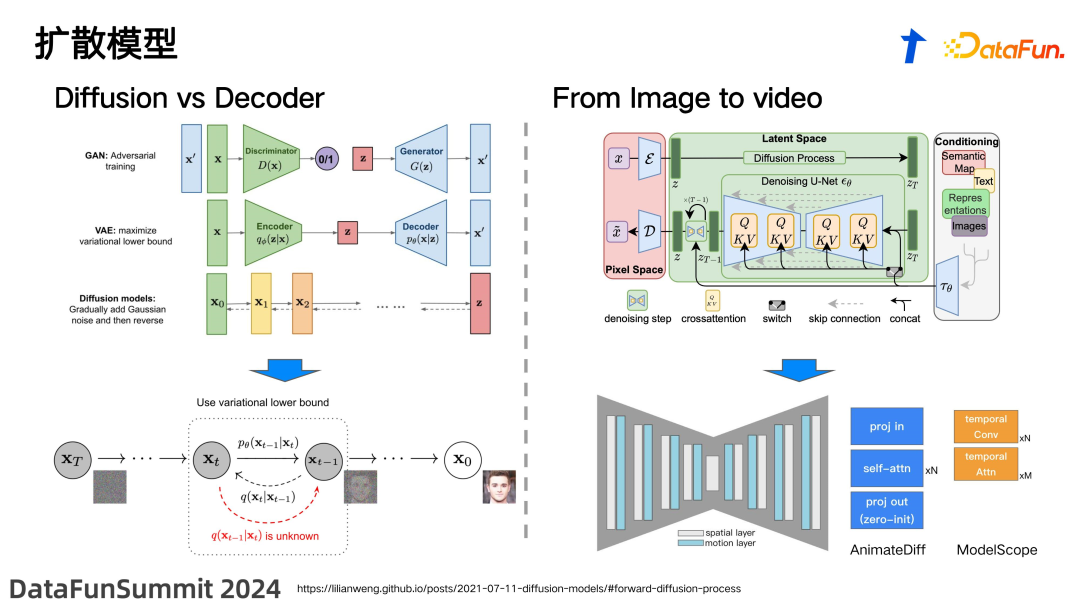
![]() 在视频生成领域,我们主要依赖于 diffusion model。为什么这种模型能够相对于之前的 GAN 生成或者 VAE 生成技术实现显著的效果提升呢?关键的区别在于,以往的模型通常采用单步生成或称为 decoder 的方法,直接从隐空间一步生成最终的数据 x。这种单步从隐空间映射到数据空间的生成过程,建模非常复杂,过去的模型往往难以实现有效的建模。然而,diffusion model 的独特之处在于它采用多步骤过程。为什么称之为“diffusion”呢?“扩散”的概念类似于一滴墨水滴入水杯中,墨水缓缓扩散开来,最终均匀分布,使我们难以区分它与其他水的不同。这种自然界中广泛存在的扩散过程被用来模拟数据生成:假设一个人脸图像或任何信号,通过 n 步加噪声的迭代,最终变为纯噪声。这就是 diffusion 的过程,它极大地增强了模型处理复杂数据的能力。与 diffusion 相对应的,在 diffusion model 中核心学习的任务是 denoising,通过逐步去除噪声最终生成我们所需的图像信号。从无序的噪声中重建有序的信号,这个过程被称为 denoising。具体来说,diffusion model 主要包括两个过程:一个是加噪过程,称为 diffusion;另一个是降噪过程,称为 denoising。在加噪的过程中,通过每一步的计算添加高斯噪声,从而实现加噪。相比之下,denoising 过程更为复杂,也就是模型训练去拟合的过程,旨在使模型学会在每一个单步上,即从 t 步到 t-1 中的噪声预测。因此,在每一步的噪声预测中,生成的模型会生成高斯噪声,并将整个预测的域限定在高斯分布上,这样可以使整个 diffusion model 更有效地学习这个过程。相对于以前的 VAE 的 encoder-decoder 架构,或者是基于 GAN 的通过discriminator 去修正 generator 生成的模式,diffusion model 能够实现更优的生成效果。Diffusion 模型最初主要应用于图像生成,原因在于图像数据更容易收集,而且相对于视频,图像生成所需注入的信息量较少。在众多突出的研究中,stable diffusion 是最著名的一项工作。这个框架的设计主要基于三个模块:encoder和 decoder 模块、unet 模块以及 condition 模块。使用 encoder 和 decoder 模块的原因在于,这种设计复用了之前 VAE 模型的架构。这样做的好处是能够将真实图像映射到隐空间,实现图像的下采样和数据压缩,从而在后续过程中减少所需的计算量。此外,在隐空间中,像 VAE 模型那样对 z 的约束形成高斯分布,使得 latent space 的分布较为标准。这种设置使得在隐空间中进行 denoising 学习变得相对容易。这就是第一个主要模块,即 VAE 模块。第二个介绍的是 condition 模块,它在生成过程中起着至关重要的作用。例如,在文生视频的应用中,我们通常提到的是从文本到视频的转换,这里的 condition 即为文本,也就是对画面的描述性文本提示(prompt)。除此之外,condition 模块还可以包含其他多种形式的条件输入,如图像本身、代表特定特征的向量,以及如语义分割图这类的图像等。这些条件的引入,允许模型根据不同的输入信息产生定制化的输出,从而增强生成内容的相关性和准确性。中间核心部分是 unet 模块,这是实际进行 denoising 预测的模块。上图中展示的流程是从第 t 步到第 t-1 步的过程。整个生成流程是通过迭代 T 步迭代到第 0 步,但每个模块的构成是一致的。在 unet 模块中,通过 down sampling 和 up sampling 恢复到与输入相同的尺寸,核心包含一个 convolutional layer,其后加入了 transformer layer,通过 attention 机制将 condition 的 embedding 注入进来。例如,文本通过一个 text encoder 转换成text embedding,然后以 KV 形式与 latent space 进行 cross attention 计算,以实现条件的注入。经过这样的模型设计,就可以预测出一步的 epsilon(噪声),下一个 ZT-1 就是 ZT 减去预测出的噪声。基于这样的逻辑,通过 t 步的迭代 denoising 最终会生成一个与目标 x 相关的 z,通过 decoder 就可以还原出最终的图像。这就是 text to image 的框架。与图像相比,视频数据更难收集,视频中的时间信息和动态信息建模难度更大,数据标注的成本也非常高。因此,现在基于text video 的模型多是在 text image 模型基础上,进行时空建模的设计来实现视频生成。即在原有的 spatial layer 上加入 motion layer,通过这种结合实现生成视频的模型。其中两个较为著名的方法包括 AnimateDiff,由上海人工智能实验室提出,在时间轴上使用 self-attention,以及 ModelScope 系列,使用基于 3D convolution layer 的 temporal 建模。这种框架实际上保留了模型由文本生成静态图像的能力,并且通过引入 motion layer,实现了在时间轴上的平滑过渡。这相当于在每一帧图片生成的基础上,通过将这些帧相互连接生成一个连续动态的视频。这种方法可以有效地将单帧的静态图像转变为展现动态序列的视频,使得生成的内容不仅限于静态画面,而是展现出时间维度上的连贯动态。
在视频生成领域,我们主要依赖于 diffusion model。为什么这种模型能够相对于之前的 GAN 生成或者 VAE 生成技术实现显著的效果提升呢?关键的区别在于,以往的模型通常采用单步生成或称为 decoder 的方法,直接从隐空间一步生成最终的数据 x。这种单步从隐空间映射到数据空间的生成过程,建模非常复杂,过去的模型往往难以实现有效的建模。然而,diffusion model 的独特之处在于它采用多步骤过程。为什么称之为“diffusion”呢?“扩散”的概念类似于一滴墨水滴入水杯中,墨水缓缓扩散开来,最终均匀分布,使我们难以区分它与其他水的不同。这种自然界中广泛存在的扩散过程被用来模拟数据生成:假设一个人脸图像或任何信号,通过 n 步加噪声的迭代,最终变为纯噪声。这就是 diffusion 的过程,它极大地增强了模型处理复杂数据的能力。与 diffusion 相对应的,在 diffusion model 中核心学习的任务是 denoising,通过逐步去除噪声最终生成我们所需的图像信号。从无序的噪声中重建有序的信号,这个过程被称为 denoising。具体来说,diffusion model 主要包括两个过程:一个是加噪过程,称为 diffusion;另一个是降噪过程,称为 denoising。在加噪的过程中,通过每一步的计算添加高斯噪声,从而实现加噪。相比之下,denoising 过程更为复杂,也就是模型训练去拟合的过程,旨在使模型学会在每一个单步上,即从 t 步到 t-1 中的噪声预测。因此,在每一步的噪声预测中,生成的模型会生成高斯噪声,并将整个预测的域限定在高斯分布上,这样可以使整个 diffusion model 更有效地学习这个过程。相对于以前的 VAE 的 encoder-decoder 架构,或者是基于 GAN 的通过discriminator 去修正 generator 生成的模式,diffusion model 能够实现更优的生成效果。Diffusion 模型最初主要应用于图像生成,原因在于图像数据更容易收集,而且相对于视频,图像生成所需注入的信息量较少。在众多突出的研究中,stable diffusion 是最著名的一项工作。这个框架的设计主要基于三个模块:encoder和 decoder 模块、unet 模块以及 condition 模块。使用 encoder 和 decoder 模块的原因在于,这种设计复用了之前 VAE 模型的架构。这样做的好处是能够将真实图像映射到隐空间,实现图像的下采样和数据压缩,从而在后续过程中减少所需的计算量。此外,在隐空间中,像 VAE 模型那样对 z 的约束形成高斯分布,使得 latent space 的分布较为标准。这种设置使得在隐空间中进行 denoising 学习变得相对容易。这就是第一个主要模块,即 VAE 模块。第二个介绍的是 condition 模块,它在生成过程中起着至关重要的作用。例如,在文生视频的应用中,我们通常提到的是从文本到视频的转换,这里的 condition 即为文本,也就是对画面的描述性文本提示(prompt)。除此之外,condition 模块还可以包含其他多种形式的条件输入,如图像本身、代表特定特征的向量,以及如语义分割图这类的图像等。这些条件的引入,允许模型根据不同的输入信息产生定制化的输出,从而增强生成内容的相关性和准确性。中间核心部分是 unet 模块,这是实际进行 denoising 预测的模块。上图中展示的流程是从第 t 步到第 t-1 步的过程。整个生成流程是通过迭代 T 步迭代到第 0 步,但每个模块的构成是一致的。在 unet 模块中,通过 down sampling 和 up sampling 恢复到与输入相同的尺寸,核心包含一个 convolutional layer,其后加入了 transformer layer,通过 attention 机制将 condition 的 embedding 注入进来。例如,文本通过一个 text encoder 转换成text embedding,然后以 KV 形式与 latent space 进行 cross attention 计算,以实现条件的注入。经过这样的模型设计,就可以预测出一步的 epsilon(噪声),下一个 ZT-1 就是 ZT 减去预测出的噪声。基于这样的逻辑,通过 t 步的迭代 denoising 最终会生成一个与目标 x 相关的 z,通过 decoder 就可以还原出最终的图像。这就是 text to image 的框架。与图像相比,视频数据更难收集,视频中的时间信息和动态信息建模难度更大,数据标注的成本也非常高。因此,现在基于text video 的模型多是在 text image 模型基础上,进行时空建模的设计来实现视频生成。即在原有的 spatial layer 上加入 motion layer,通过这种结合实现生成视频的模型。其中两个较为著名的方法包括 AnimateDiff,由上海人工智能实验室提出,在时间轴上使用 self-attention,以及 ModelScope 系列,使用基于 3D convolution layer 的 temporal 建模。这种框架实际上保留了模型由文本生成静态图像的能力,并且通过引入 motion layer,实现了在时间轴上的平滑过渡。这相当于在每一帧图片生成的基础上,通过将这些帧相互连接生成一个连续动态的视频。这种方法可以有效地将单帧的静态图像转变为展现动态序列的视频,使得生成的内容不仅限于静态画面,而是展现出时间维度上的连贯动态。
02****
视频生成的主要难点下面介绍开发过程中的主要难点,以及我们为优化模型生成图像的效率和最终性能所设计的解决方案。
![]()
1. 难点 1:动作建模合理我们发现在一些模型中会出现问题,例如在模拟鼓掌动作的图像中,手部可能会融合在一起,或者大臂与小臂的比例和运动不符合机械原理,导致动作看起来不自然。此外,由于每一帧的时空建模是独立进行的,若没有通过 motion layer 有效地串联这些帧,就可能出现动作不连贯的现象。例如,一帧中狗可能朝左,而下一帧突然朝右,造成观感上的剧烈变化。这些问题都需要在模型的动作建模方面进行优化,以确保生成的视频动作连贯且自然。
2. 难点 2:语义对齐准确当我们的 condition 仅有文字时,在实际工业应用中,需要模型对这些文字描述有更好的响应能力。例如,控制生成的数量,比如是四只还是五只,以及对特定局部区域的空间控制。用户可能希望生成的背景是黄色或白色,或者想要白色的潜艇、白色的狗等特定对象。因此,对语义的准确理解和响应在整个生成框架中是影响生成效果的一个关键点,对提高模型的实用性和用户满意度至关重要。
3. 难点 3:画质细节精美第三个难点是对画质的进一步雕琢。考虑到当前互联网统计数据显示,大约七八十甚至九十以上的网络流量来自视频,因此用户对视频的画质、分辨率以及帧率有着更高的期望。在生成模型中,我们面临的挑战是如何在生成速度和画质之间找到平衡。因此,我们必须对模型进行优化,以确保在满足实时生成的同时,也能够提供高质量的视频输出。针对这些难点,我们设计了一些解决方案。
4. 方案 1:运动质量提升
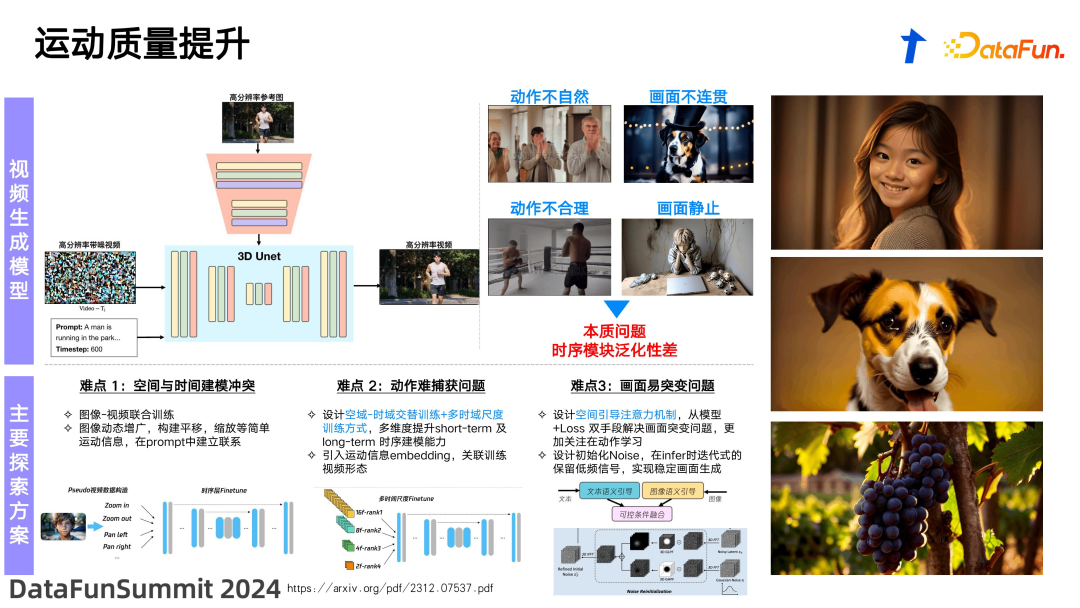
![]() 为了提升运动质量,我们设计了一个整体的模型框架,在 text condition 的基础上,注入 image condition。这种 image condition 为模型提供了一个生成时的基准,可以理解为一个锚点(anchor)。通常这个锚点是视频的第一帧,基于这一帧,模型会在后续帧的生成中保持人物和背景的基本分布,以及大致的运动空间。这样的设计使得训练过程中视频的生成结构更稳定,运动更加合理。这样相当于降低了模型在训练时对整个视频画面的理解难度,从而优化了生成过程的效率和质量。这种方法不仅提升了视频的视觉连贯性,还确保了生成内容的动态自然性和逼真度。为了训练这种模型,我们在数据集的增广方面进行了一些探索。图片数据远多于视频数据,一般来说,训练一个图像模型可能会使用到 10 亿条数据,而视频数据可能只有千万到亿级别。为了弥补这种差距,第一,我们通过对图片进行增广处理,比如缩放、左移、右移、上移、下移等操作,使图片模拟简单的运动视频,从而扩大训练集。第二,我们在多分辨率的环境下设计了一种训练框架,可以同时处理不同帧率、帧数和视频分辨率的数据,这样可以实现更丰富的数据样态,提高模型的效果。第三,我们在图像和文本的控制(condition)上进行了有条件的融合,通过数据学习拟合条件的权重和参数。另外,还借鉴了南洋理工大学 ziwei liu 教授的研究,采用多轮生成的方法构建模型,利用上一轮生成的低频信号信息指导下一轮的生成。我们可以将低频信号理解为在运动中相对保持固定的一些特征,例如一个人跑步时背景相对固定,而跑步动作则是有节奏的规律运动。基于这样的低频信号指导,最终生成的视频信号将更加稳定。
为了提升运动质量,我们设计了一个整体的模型框架,在 text condition 的基础上,注入 image condition。这种 image condition 为模型提供了一个生成时的基准,可以理解为一个锚点(anchor)。通常这个锚点是视频的第一帧,基于这一帧,模型会在后续帧的生成中保持人物和背景的基本分布,以及大致的运动空间。这样的设计使得训练过程中视频的生成结构更稳定,运动更加合理。这样相当于降低了模型在训练时对整个视频画面的理解难度,从而优化了生成过程的效率和质量。这种方法不仅提升了视频的视觉连贯性,还确保了生成内容的动态自然性和逼真度。为了训练这种模型,我们在数据集的增广方面进行了一些探索。图片数据远多于视频数据,一般来说,训练一个图像模型可能会使用到 10 亿条数据,而视频数据可能只有千万到亿级别。为了弥补这种差距,第一,我们通过对图片进行增广处理,比如缩放、左移、右移、上移、下移等操作,使图片模拟简单的运动视频,从而扩大训练集。第二,我们在多分辨率的环境下设计了一种训练框架,可以同时处理不同帧率、帧数和视频分辨率的数据,这样可以实现更丰富的数据样态,提高模型的效果。第三,我们在图像和文本的控制(condition)上进行了有条件的融合,通过数据学习拟合条件的权重和参数。另外,还借鉴了南洋理工大学 ziwei liu 教授的研究,采用多轮生成的方法构建模型,利用上一轮生成的低频信号信息指导下一轮的生成。我们可以将低频信号理解为在运动中相对保持固定的一些特征,例如一个人跑步时背景相对固定,而跑步动作则是有节奏的规律运动。基于这样的低频信号指导,最终生成的视频信号将更加稳定。
5. 方案 2:语义对齐准确
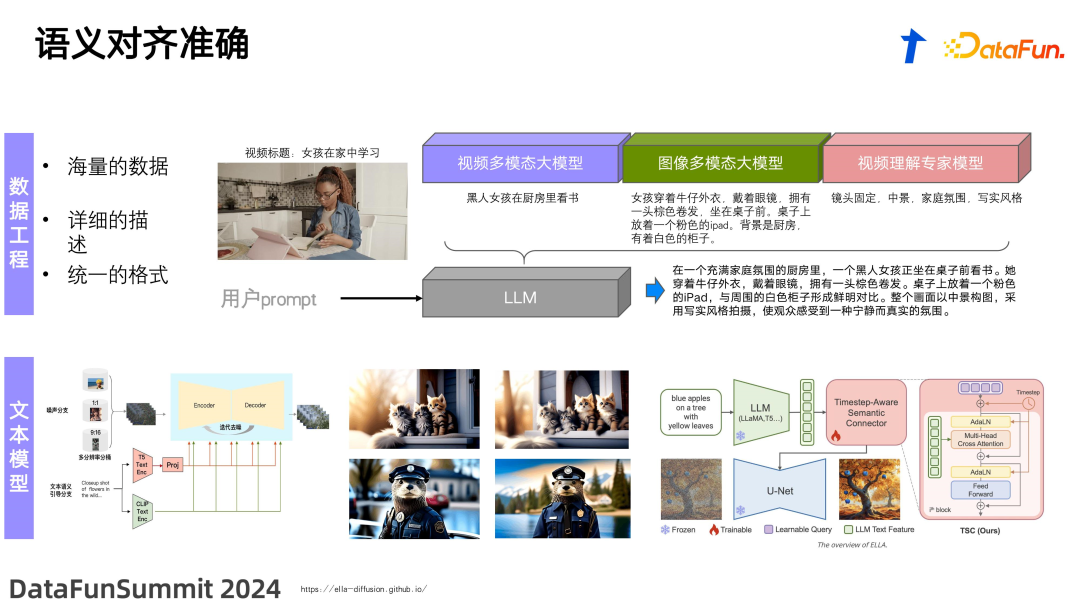
![]() 关于语义对齐,我们发现开源的数据集通常比较简单,对画面的描述仅是一个笼统的概念,例如“女孩在家中学习”。然而,在生成模型的预训练中,我们需要精确地对齐画面中的各种元素。例如,不仅要描述“女孩在家中学习”,还要包括更具体的场景和元素,如“她在厨房里用 iPad 学习,穿着牛仔衬衫,她是一位黑人女孩”。为了提高对这种复杂场景的理解,我们尝试使用过去的视频理解专家模型和现在较多使用的视频基础模型(video foundation model),来实现对视频的多维度描述生成。最后,再通过大型语言模型进行融合。在这个大模型的时代,研究方向的一个新范式是需要团队合作。因此,我们使用腾讯内部的多模态包括语言文本模型的资源进行组合,最终生成了一个对画面更优质的理解。通过这种深入的理解,就能够训练出更好的生成模型。这也是对“更好的理解带来更好的生成”这一理念的实践。未来,我们可能还会探索基于知识图谱的画面描述,以通过知识图谱的结构更好地生成最终的视频效果。在模型中对文本的理解至关重要。我们之前通常使用的开源模型是 CLIP 的 text encoder。CLIP 主要学习文本与图像数据之间的关联,它本质上是一个二分类模型。这样的关联可能导致对细节和不同区域下的表征不充分。因此会出现一些问题,例如,当我们输入描述为“四只猫”的时候,结果可能只显示三只猫的情况,或者在需要生成镜头运动的场景时,模型表现不佳。因此,我们发现对于文本的响应,CLIP 的 text encoder 是不够的。一个直观的方法是替换掉对文本的 encoder 模型。我们尝试使用 T5 模型进行简单的 projection,并在 unet 上训练。但由于 unet 本身基于 CLIP 训练得非常充分,整个分布依赖于 CLIP 的 text encoder,直接加入 T5 可能反而会对整个系统产生一定的影响。最近,腾讯进行了一个尝试,使用类似多模态模型中的 q-former 形式,通过cross attention 的方式将 T5 的 text embedding 注入到网络中。我们最终注入网络的长度是固定的。这样可以有效地将 T5 或其他大型语言模型如 LLAMA 的 embedding 提取出来,与 unet 中的 Query 进行匹配并注入。通过这种形式,可以对具体细节的文本描述响应更加充分,从而提高模型对文本的理解和生成的质量。
关于语义对齐,我们发现开源的数据集通常比较简单,对画面的描述仅是一个笼统的概念,例如“女孩在家中学习”。然而,在生成模型的预训练中,我们需要精确地对齐画面中的各种元素。例如,不仅要描述“女孩在家中学习”,还要包括更具体的场景和元素,如“她在厨房里用 iPad 学习,穿着牛仔衬衫,她是一位黑人女孩”。为了提高对这种复杂场景的理解,我们尝试使用过去的视频理解专家模型和现在较多使用的视频基础模型(video foundation model),来实现对视频的多维度描述生成。最后,再通过大型语言模型进行融合。在这个大模型的时代,研究方向的一个新范式是需要团队合作。因此,我们使用腾讯内部的多模态包括语言文本模型的资源进行组合,最终生成了一个对画面更优质的理解。通过这种深入的理解,就能够训练出更好的生成模型。这也是对“更好的理解带来更好的生成”这一理念的实践。未来,我们可能还会探索基于知识图谱的画面描述,以通过知识图谱的结构更好地生成最终的视频效果。在模型中对文本的理解至关重要。我们之前通常使用的开源模型是 CLIP 的 text encoder。CLIP 主要学习文本与图像数据之间的关联,它本质上是一个二分类模型。这样的关联可能导致对细节和不同区域下的表征不充分。因此会出现一些问题,例如,当我们输入描述为“四只猫”的时候,结果可能只显示三只猫的情况,或者在需要生成镜头运动的场景时,模型表现不佳。因此,我们发现对于文本的响应,CLIP 的 text encoder 是不够的。一个直观的方法是替换掉对文本的 encoder 模型。我们尝试使用 T5 模型进行简单的 projection,并在 unet 上训练。但由于 unet 本身基于 CLIP 训练得非常充分,整个分布依赖于 CLIP 的 text encoder,直接加入 T5 可能反而会对整个系统产生一定的影响。最近,腾讯进行了一个尝试,使用类似多模态模型中的 q-former 形式,通过cross attention 的方式将 T5 的 text embedding 注入到网络中。我们最终注入网络的长度是固定的。这样可以有效地将 T5 或其他大型语言模型如 LLAMA 的 embedding 提取出来,与 unet 中的 Query 进行匹配并注入。通过这种形式,可以对具体细节的文本描述响应更加充分,从而提高模型对文本的理解和生成的质量。
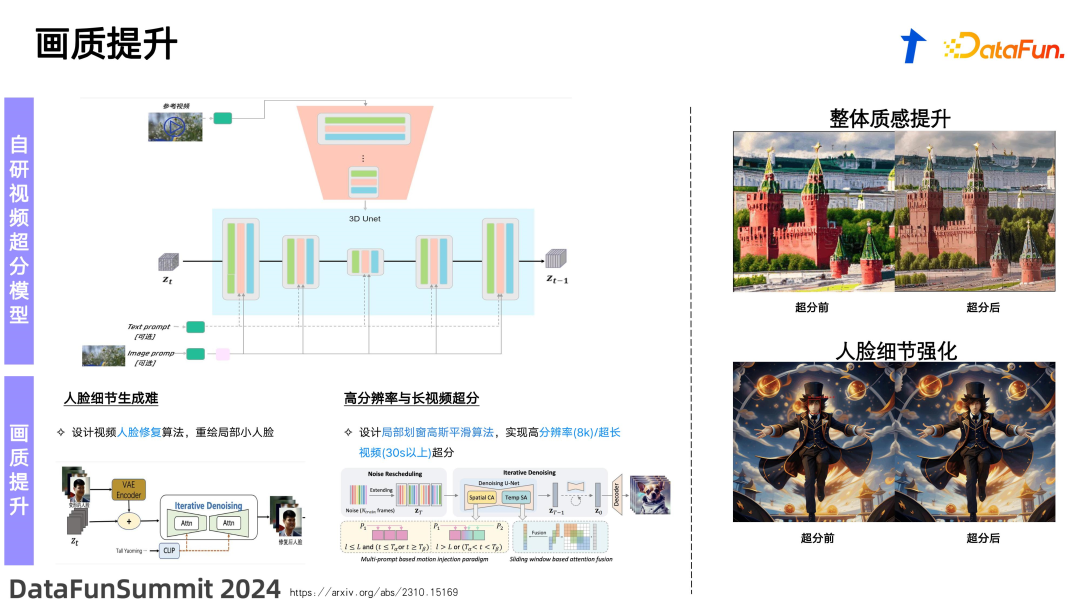
6. 方案 3:画质提升
![]() 在画质提升方面,看起来类似于传统的画质提升任务,但在生成模型中的应用实际上有所不同。在生成模型中的画质提升,包括超分辨率(super resolution)或超帧率(frame interpolation)提升,不仅仅是对原视频的简单修正,更多地是具有修复功能,需要模型具备重新生成的能力。在生成模型的第一阶段,视频的生成可能主要集中在画面的布局,决定视频主体的位置和大致的动作形式。而在第二阶段,则需要对一些具体的区域进行修复和生成。我们借鉴了基于图片 condition 的模型,设计了基于视频的 condition 模型。通过类似于 control net 的方式将条件注入到原先的 unet 中。这样,基于第一阶段生成的视频,进行有条件的、可控的生成,最终实现二阶段的超分辨率后的视频模型。通过这种方法,我们不仅简单地提高了分辨率,而且通过有目的的修复和精细化生成,提升了整个视频的视觉质量,使得最终输出的视频更加清晰且细节更加丰富。在基于人脸的生成中,用户对人脸的瑕疵更加敏感,特别是当人脸在画面中占比较小时,很容易出现生成效果的崩坏。我们分析原因,可能是由于 VAE 的 encoder 在较小区域进行了 8 倍的下采样,导致响应极小。这种情况下,decoder 在处理特别是人脸这种复杂 pattern 的小区域时,其内容表达和恢复能力不足。为了优化这一问题,我们发现在生成后对人脸区域单独进行放大和重绘可以显著优化人脸的生成效果,然后通过高斯模糊的方式将其无缝融合回原图,即可实现人脸的有效修复。此外,关于提升分辨率和处理长视频,我们也借鉴了学术界的一些方法,通过对噪声的控制实现快速的多阶段生成,同时确保生成内容之间的连续性。上图中展示了超分前后的画质对比以及人脸的修复效果。在腾讯内部进行的人工主观评测中,这种人脸修复方法可以解决 90% 以上的人脸问题,显著提高了人脸生成的质量和实用性。
在画质提升方面,看起来类似于传统的画质提升任务,但在生成模型中的应用实际上有所不同。在生成模型中的画质提升,包括超分辨率(super resolution)或超帧率(frame interpolation)提升,不仅仅是对原视频的简单修正,更多地是具有修复功能,需要模型具备重新生成的能力。在生成模型的第一阶段,视频的生成可能主要集中在画面的布局,决定视频主体的位置和大致的动作形式。而在第二阶段,则需要对一些具体的区域进行修复和生成。我们借鉴了基于图片 condition 的模型,设计了基于视频的 condition 模型。通过类似于 control net 的方式将条件注入到原先的 unet 中。这样,基于第一阶段生成的视频,进行有条件的、可控的生成,最终实现二阶段的超分辨率后的视频模型。通过这种方法,我们不仅简单地提高了分辨率,而且通过有目的的修复和精细化生成,提升了整个视频的视觉质量,使得最终输出的视频更加清晰且细节更加丰富。在基于人脸的生成中,用户对人脸的瑕疵更加敏感,特别是当人脸在画面中占比较小时,很容易出现生成效果的崩坏。我们分析原因,可能是由于 VAE 的 encoder 在较小区域进行了 8 倍的下采样,导致响应极小。这种情况下,decoder 在处理特别是人脸这种复杂 pattern 的小区域时,其内容表达和恢复能力不足。为了优化这一问题,我们发现在生成后对人脸区域单独进行放大和重绘可以显著优化人脸的生成效果,然后通过高斯模糊的方式将其无缝融合回原图,即可实现人脸的有效修复。此外,关于提升分辨率和处理长视频,我们也借鉴了学术界的一些方法,通过对噪声的控制实现快速的多阶段生成,同时确保生成内容之间的连续性。上图中展示了超分前后的画质对比以及人脸的修复效果。在腾讯内部进行的人工主观评测中,这种人脸修复方法可以解决 90% 以上的人脸问题,显著提高了人脸生成的质量和实用性。 ![]() 这里展示的是截至 2023 年年底的一些效果。上半部分是基于文生视频的示例,由文字描述控制视频内容的生成。下半部分是基于单张图片控制的“图生视频”,不再需要文本控制,可以直接从一张静态图片生成动态的视频。
这里展示的是截至 2023 年年底的一些效果。上半部分是基于文生视频的示例,由文字描述控制视频内容的生成。下半部分是基于单张图片控制的“图生视频”,不再需要文本控制,可以直接从一张静态图片生成动态的视频。
03****
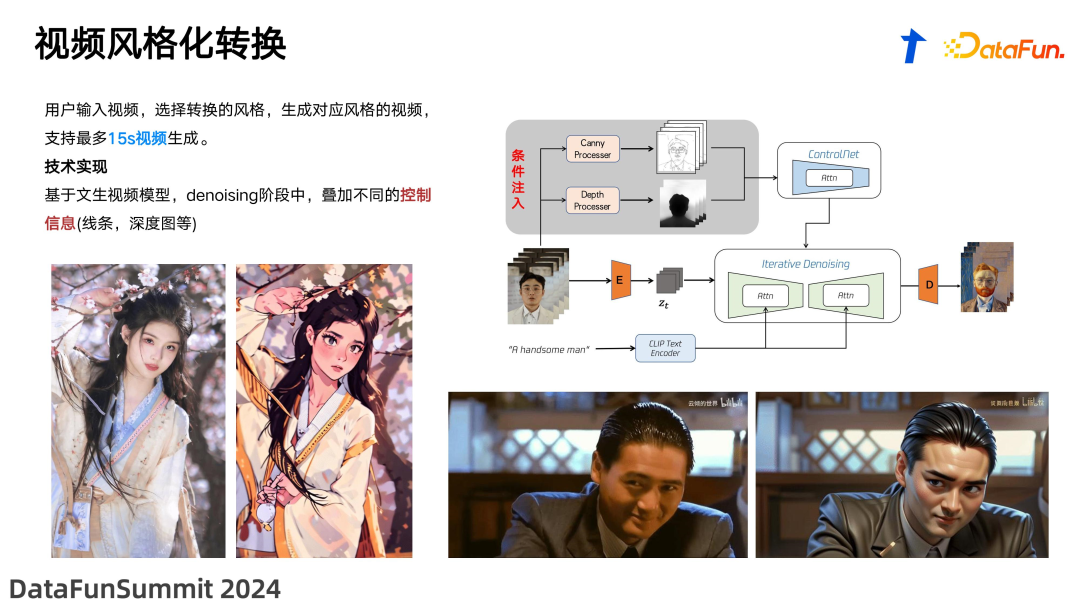
视频生成的应用实践******接下来将分享我们在工业界应用方面的一些实践。******1. 视频风格化转换
![]() 视频风格化是将真实视频或动画视频转化成其他风格视频的过程。这里展示的示例包括将真实视频转化成日本动漫风格,以及将真实视频转化成 3D 动画风格。这种转化不仅可以应用于模特拍摄的视频生成对应的动画画面,还可以用于风景视频的风格迁移。例如,我们曾与人民日报合作制作了一系列名为“江山如此多娇”的短片,其中包括对风景进行风格化处理,效果非常引人注目,大家可以在微信视频号中搜索观看。具体的实现方法包括将视频作为 condition 输入,这里的 condition 不仅包括常规的 RGB 信号,还包括 Canny 边缘检测信号、深度信息和人物骨架控制等信号序列。这些信号通过 ControlNet 的形式注入到 unet 中,从而生成相应的风格化视频。之所以能够生成特定风格的视频,是因为我们对 unet 进行了针对该独立风格的微调,使其成为一个只能生成动漫风格视频的网络。因此,基于原始视频的控制信号,加上专门生成动漫风格的模型,我们可以生成与原视频内容对齐的动漫风格视频。这种技术不仅提升了视频的视觉效果,也增加了内容的多样性和趣味性。
视频风格化是将真实视频或动画视频转化成其他风格视频的过程。这里展示的示例包括将真实视频转化成日本动漫风格,以及将真实视频转化成 3D 动画风格。这种转化不仅可以应用于模特拍摄的视频生成对应的动画画面,还可以用于风景视频的风格迁移。例如,我们曾与人民日报合作制作了一系列名为“江山如此多娇”的短片,其中包括对风景进行风格化处理,效果非常引人注目,大家可以在微信视频号中搜索观看。具体的实现方法包括将视频作为 condition 输入,这里的 condition 不仅包括常规的 RGB 信号,还包括 Canny 边缘检测信号、深度信息和人物骨架控制等信号序列。这些信号通过 ControlNet 的形式注入到 unet 中,从而生成相应的风格化视频。之所以能够生成特定风格的视频,是因为我们对 unet 进行了针对该独立风格的微调,使其成为一个只能生成动漫风格视频的网络。因此,基于原始视频的控制信号,加上专门生成动漫风格的模型,我们可以生成与原视频内容对齐的动漫风格视频。这种技术不仅提升了视频的视觉效果,也增加了内容的多样性和趣味性。
2. 人体姿态控制
![]() 这里的输入是单独的人物图片,可以是真人也可以是动漫形象。接着,我们将使用人体动作骨架的控制序列,包括人的手、腿、头部等关键点的骨架图。有了这些骨架图之后,我们设计了一个 condition 融合模块,将之前提到的 noise 与 condition 融合后,注入到 unet 网络中。这样就可以生成动态的人物图像,让参考图像中的人物动起来。这项技术的应用非常广泛,一方面可以用于创造有趣的互动体验,例如让图中的人物跳舞;另一方面,它也可以用于从单一动漫图像直接生成动作视频,极大提高了动漫制作和短视频制作的效率。尽管这个模型未在动物数据上进行训练,但它展示了一定的泛化能力,甚至能使图中的小猫跳舞,增添了一份趣味性。
这里的输入是单独的人物图片,可以是真人也可以是动漫形象。接着,我们将使用人体动作骨架的控制序列,包括人的手、腿、头部等关键点的骨架图。有了这些骨架图之后,我们设计了一个 condition 融合模块,将之前提到的 noise 与 condition 融合后,注入到 unet 网络中。这样就可以生成动态的人物图像,让参考图像中的人物动起来。这项技术的应用非常广泛,一方面可以用于创造有趣的互动体验,例如让图中的人物跳舞;另一方面,它也可以用于从单一动漫图像直接生成动作视频,极大提高了动漫制作和短视频制作的效率。尽管这个模型未在动物数据上进行训练,但它展示了一定的泛化能力,甚至能使图中的小猫跳舞,增添了一份趣味性。
3. 视频运动笔刷
![]() 视频运动笔刷可以让视频中的局部区域动起来,这对于工业应用中提高效率非常有用。具体操作是,通过用户的控制让画面中某个局部区域进行动态表现,控制方式包括选择特定区域以及输入相关文本。例如,用户可以点击图中某个区域,如让画中的女神开始哭泣,或让皮卡丘显得更加开心而笑起来。在技术实现上,我们在输入的 condition 中加入了一些特定功能来实现这样的效果。首先,用户的点击会触发对该区块的实例分割,产生一个 mask。这个 mask 随后会被用于 cross attention 过程中,与输出即 denoise 的输入一起工作。在 attention 过程中,加入的 mask 将增强被选区域的动态效果,同时抑制 mask 之外的区域动作,从而使得指定区域的运动更加丰富和明显。这种技术不仅增加了视频内容的互动性和动态表现,还提高了制作过程的灵活性和效率。
视频运动笔刷可以让视频中的局部区域动起来,这对于工业应用中提高效率非常有用。具体操作是,通过用户的控制让画面中某个局部区域进行动态表现,控制方式包括选择特定区域以及输入相关文本。例如,用户可以点击图中某个区域,如让画中的女神开始哭泣,或让皮卡丘显得更加开心而笑起来。在技术实现上,我们在输入的 condition 中加入了一些特定功能来实现这样的效果。首先,用户的点击会触发对该区块的实例分割,产生一个 mask。这个 mask 随后会被用于 cross attention 过程中,与输出即 denoise 的输入一起工作。在 attention 过程中,加入的 mask 将增强被选区域的动态效果,同时抑制 mask 之外的区域动作,从而使得指定区域的运动更加丰富和明显。这种技术不仅增加了视频内容的互动性和动态表现,还提高了制作过程的灵活性和效率。
04****
一些不太长远的展望
![]() Sora 的出现无疑极大地推动了文生视频技术的推广,引起了广泛关注。当行业内还在讨论如何处理 4 秒或 8 秒的视频时,Sora 已经能够生成长达 1 分钟的视频,这无疑震惊到了整个行业的从业人员。Sora 的出现将视频生成技术分成了两个阵营:“Sora”与“其他”。这种划分突显了 Sora 与现有技术之间的根本区别。首先要讲的一个区别是关于 scaling up 的概念,OpenAI 非常推崇这一策略,他们坚信通过增大数据量和模型规模可以解决各种问题。同时,他们设计的 Sara 模型也是为了模拟物理世界,所有动机和设计都基于 scaling up 的理念。为了实现模型规模的扩大,他们将unet 中的 CNN 替换为了 Transformer,因为相比于 CNN,Transformer 更易于进行模型的并行优化。此外,他们还利用了之前大型语言模型(LLM)的工程技术。关于如何做出更长的视频,他们首先在 encoder 的 VAE 阶段对视频进行了压缩。这种压缩不仅仅发生在单帧的分辨率空间,还包括在时间轴上的大幅压缩。这样做使得在一个较小的 latent 空间中进行 denoise 成为可能,同时也能通过这个 denoise 过程或 latent 生成相对较长的视频。这里有三个例子展示了 Sora 模型的效果,这些例子来自 Sora 的官方网站。第一个例子是基于 0-scale 的模型效果,第二个是 8 倍 scale 的效果,最后一个是 32 倍 scale 的效果。可以明显看到,随着模型规模的增加,生成的视频效果有了显著提升。同时,我也推荐大家关注中国的两个开源 Sora 项目。一个是潞晨科技的项目,另一个是北京大学袁粒老师领导的团队开发的 Open Sora Plan。这些团队对开源社区的贡献值得敬佩,他们投入了大量精力。腾讯也在积极进行类似的工作,我们正在探索基于 Transformer 架构的技术。希望在不久的将来,我们能够展示更好的效果,并预计会有一个重要的版本更新。欢迎大家积极体验这一新技术。
Sora 的出现无疑极大地推动了文生视频技术的推广,引起了广泛关注。当行业内还在讨论如何处理 4 秒或 8 秒的视频时,Sora 已经能够生成长达 1 分钟的视频,这无疑震惊到了整个行业的从业人员。Sora 的出现将视频生成技术分成了两个阵营:“Sora”与“其他”。这种划分突显了 Sora 与现有技术之间的根本区别。首先要讲的一个区别是关于 scaling up 的概念,OpenAI 非常推崇这一策略,他们坚信通过增大数据量和模型规模可以解决各种问题。同时,他们设计的 Sara 模型也是为了模拟物理世界,所有动机和设计都基于 scaling up 的理念。为了实现模型规模的扩大,他们将unet 中的 CNN 替换为了 Transformer,因为相比于 CNN,Transformer 更易于进行模型的并行优化。此外,他们还利用了之前大型语言模型(LLM)的工程技术。关于如何做出更长的视频,他们首先在 encoder 的 VAE 阶段对视频进行了压缩。这种压缩不仅仅发生在单帧的分辨率空间,还包括在时间轴上的大幅压缩。这样做使得在一个较小的 latent 空间中进行 denoise 成为可能,同时也能通过这个 denoise 过程或 latent 生成相对较长的视频。这里有三个例子展示了 Sora 模型的效果,这些例子来自 Sora 的官方网站。第一个例子是基于 0-scale 的模型效果,第二个是 8 倍 scale 的效果,最后一个是 32 倍 scale 的效果。可以明显看到,随着模型规模的增加,生成的视频效果有了显著提升。同时,我也推荐大家关注中国的两个开源 Sora 项目。一个是潞晨科技的项目,另一个是北京大学袁粒老师领导的团队开发的 Open Sora Plan。这些团队对开源社区的贡献值得敬佩,他们投入了大量精力。腾讯也在积极进行类似的工作,我们正在探索基于 Transformer 架构的技术。希望在不久的将来,我们能够展示更好的效果,并预计会有一个重要的版本更新。欢迎大家积极体验这一新技术。
05****
**问答环节Q1:文生图或视频过程中的语义保真如何理解?如何衡量生成的质量?******A1:这是一个很好的问题。首先,我们可以从两个方面来衡量:主观的和客观的。从客观角度来说,我们会使用一些模型来评估,比如对于语义保真度,我们常用 CLIP 的相关性作为一个重要的衡量标准。另外,我们腾讯的某些系列产品也通过语义相关性、运动感、画质、清晰度以及内容的丰富度等方面,使用专家模型来评估生成内容的综合效果。从主观角度来看,我们通过人来评估。我们内部有一个专门的评测团队,超过 1000 人,他们通过对比两个模型的输出来评估效果优劣。评估形式通常是进行模型对比,例如将混元和 Pika 的结果相比较,评估团队会判断哪一个更好,或者两者是否相当。评估人员都经过专业训练,在多个维度上进行评估,并进行加权判断。
Q2**:Sora 背后到底有没有它的护城河,到底在哪里?是数据量,技术框架,还是都有?****A2:我觉得显然是两者都有。在技术框架方面,网络模型的护城河可能相对较低。但是在大规模训练的基建方面,我认为有相当大的护城河。OpenAI 在千卡甚至万卡级的 GPU 联合训练上有非常深厚的积累,这在其他公司,尤其是国内的一些公司中可能相对欠缺。另外,正如我之前提到的,团队协作方面,OpenAI 的 LLM 和其 GP4-V 等多模态模型也表现出显著的优势,这些模型对于理解产生的数据极为关键,对生成模型的训练也会有很大影响。我们在数据构建方面落后于他们,在训练的最终结果上也有较大的差距。,所以这构成了一个非常深的护城河,我们需要在各个方面实现追赶和超越。Q3:您刚刚提到数据层面,只是原始收集的数据量比我们大,还是他借助的这些工具做得更好、质量更好呢?******A3:我之前听说过 OpenAI 在下载全互联网的视频数据,具体数据量他们没有公开,我也不好猜测。另外,也有分析指出他们使用了 UE 引擎来造数据。考虑到他们对 Scaling Up 的崇拜,我觉得他们的数据量应该是非常巨大的,可能超出我们的想象。 在数据质量上,如我之前所述,对视频的描述能力会产生很大的影响。即使我们拥有相同的数据,如果我们对其描述存在缺陷或差距,那么训练出来的生成模型也会有显著的性能差异。所以,不仅是数据的数量,其质量和处理方式同样关键。
Q4**:您认为 Sora 这种机制,或者这种数据驱动的方式,是否真的能够理解这个物理世界?因为关于这个的争论很多,到底能不能真正地实现所谓的世界模型呢?**A4:我个人觉得这还是比较困难的。我认为我们现有的数据可能还不够。在这种扩大模型和训练的方式下,对于算力来说,数据的利用率是非常低的。例如,一个人不需要看几十亿、上百亿的数据视频就能理解影子是由物体遮挡光线产生的,但是 AI 模型可能就需要极大量的数据才能学会这一点。当然,如果有足够多的数据,也许 AI 真的能够学会,但是暂时来看,我们可能在有生之年都达不到这样的数据规模,所以我认为实现真正的物理世界理解是非常难的。同时,也有人讨论说生成模型是否一定需要对物理有强制性约束,因为我们实际上看到的世界有时也会因为我们自己的视觉系统产生误判。比如,两个相同大小和颜色的正方形放在不同的背景下,我们也可能会判断它们的亮度不同。所以,最终如果 AI 模型能够符合我们人类的视觉偏好,也是可以接受的。以上就是本次分享的内容,谢谢大家。
![]()
分享嘉宾
INTRODUCTION ![]()
刘孟洋博士![]()
腾讯![]()
算法工程师![]()
香港城市大学博士学位,腾讯高级算法工程师,5 年计算机视觉从业经验,现从事文生视频算法研究工作。研究方向包括视频生成,图像生成,多模态,视频表征学习,大规模视频检索系统等。曾参与构建十亿级视觉检索系统,服务于视频去重,版权保护等。****