
两年前普遍认为受边缘硬件算力、内存与功耗限制,在商用设备实现GPT-4级性能绝无可能。EdgeRunner人工智能突破这些限制——完全在终端设备实现GPT-5级能力——成为全球首个在军事及"拒止、降级、间歇与受限"(DDIL)场景投入应用的系统。推出EdgeRunner 20B模型,该模型由EdgeRunner AI团队研发,在四项军事测试集达到GPT-5任务性能,并可在边缘设备完全物理隔离环境下运行。这些成果验证了核心论点:通过深度军事定制化,能够将基础模型参数量从数千亿乃至数万亿压缩至200亿量化参数以下,同时保持对作战人员关键能力的任务性能不衰减。
四大新型军事测试集构建
建模的关键环节是创建经资深军事专业人员审核的高质量军事测试集。缺乏优质测试数据,行业将如同在黑暗中射击不可见目标。EdgeRunner设立三级测试集标准:(a)金牌测试集:由至少一名军事领域专家在无人工智能辅助条件下从头创建;(b)银牌测试集:经领域专家审核但采用人工智能辅助(包括示例生成、筛选或创建);(c)铜牌测试集:由研发团队为开发目的创建但未经军事专家审核。
研究推出四个新测试集:
• 战斗兵种:180示例银牌数据集,覆盖以步兵为重点的战斗兵种专业领域
• 战斗医护:446示例银牌数据集,覆盖战斗医疗兵专业领域
• 网络攻防:142示例金牌数据集,涵盖(a)合规性(b)训练(c)事件响应(d)任务规划(e)安全流程(f)威胁情报(g)工具链
• 军事基准5千:5000示例银牌数据集,源自官方军事出版物的多领域军事主题
网络数据集由美国陆军网络作战专家从头创建,其余三个数据集经三名累计服役超45年(含20年特战经验)的美国陆军军官审核。
训练方法论
采用EdgeRunner监督微调数据生成流水线,构建包含160万训练示例的高质量数据集。流水线第一阶段使用大语言模型对海量军事文献进行摘要生成;第二阶段借助摘要上下文,通过另一大语言模型从文档分块生成问答对;最终阶段由不同模型评估生成问答对质量——高质量样本采纳,中质量样本返工,低质量样本弃用。 以gpt-oss-20b为基础模型开展训练实验,涵盖axolotl、TRL等训练库与TensorRT模型优化器的量化感知训练技术,调整学习率与批大小参数,采用gpt-oss-120b生成的合成推理数据,并测试多种对话模板。论文中提供了gpt-oss-20b高效微调的关键实验结论。
结果分析
经与GPT-5对比发现,除个别双向异常值外,模型在军事任务性能上可比肩GPT-5,同时具备可在用户本地设备运行的轻量化特性。最新GPT模型支持用户配置推理强度参数以控制答案生成前的思考时长。
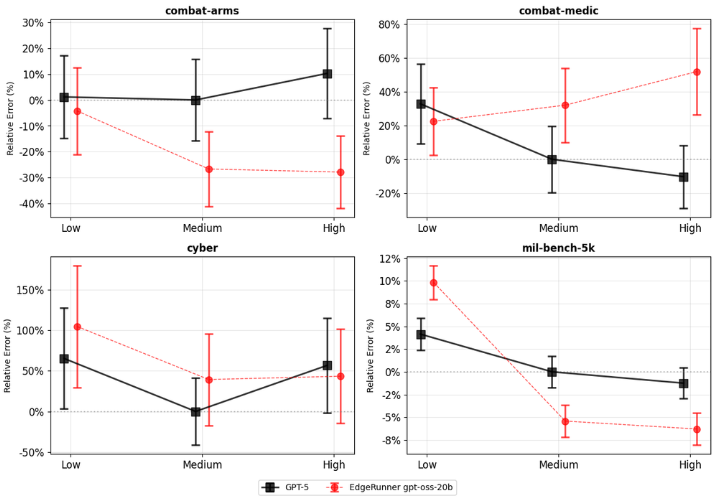
图1展示相对于GPT-5中等推理设置的错误率对比(数值越低性能越优)。鉴于测试集规模有限,需同步考察衡量统计相似性的p值(仅当p值低于0.05时认为差异显著)。

表1呈现具体p值数据:EdgeRunner 20B在12项对比中取得3胜2平7负,综合判定两款模型在四项任务性能表现相当。
未来展望
正在开发包括战斗医疗、战术级战斗兵种、战役级战斗兵种、车辆维护与航空维护等金牌测试集,将逐步建立完善的评估体系与排行榜。同时正在设计用于衡量请求驳回率与解决率的测试指标,并研发基于这些标准提升模型性能的创新方法。
模型实验覆盖多规模架构与终端用户场景,包括移动端轻量模型、笔电端中量模型(如EdgeRunner 20B)及专用服务器重型模型。一系列创新技术正在研发中,期待尽快分享更多成果。
本地化人工智能模型不仅具备强韧性,更构成最安全的系统架构。此外,本地处理能力可持续降低长期成本,从而提升技术部署效率,为部队创造更显著的非对称优势。

