

机器学习模型经过大量数据训练后,在各种应用中取得了显著的成功。然而,它们在现实世界的高风险领域部署时也带来了新的挑战和风险。深度学习模型做出的决策往往难以解释,其背后的机制仍然理解不足,而且大规模的基础模型可能记住并泄露私人个人信息。鉴于深度学习模型作为黑盒操作,理解当前机器学习系统中各种类型的故障,更不用说解决这些故障,是非常具有挑战性的。在本论文中,我们通过表示学习的视角,展示了构建可靠机器学习系统的研究。第一部分关注透明的表示学习。我们首先提出了一个原理性且有效的目标函数,称为编码率降低,用于衡量表示的优良性,并提出了一种白盒方法来理解Transformer模型。接着,我们展示了如何通过最大化学习到的表示的信息增益,派生出一系列数学上可解释的类Transformer深度网络架构。第二部分关注隐私保护的表示学习。我们首先介绍了使用联合优化方法理解学到的表示的有效性的研究,并介绍了在联邦设置中训练深度、非凸模型时克服数据异构性的方法。接下来,我们描述了我们在训练第一套具有严格差分隐私保证的视觉基础模型的工作,并展示了具有高效用性的差分隐私表示学习的前景。


引言
近年来,机器学习实践——尤其是在巨大规模上训练的深度学习模型——通过其在学习来自现实世界的高维和多模态数据中有用表示的经验性成功,捕获了人们的想象【145, 100, 250, 201】。这些成功很大程度上归功于深度网络在有效学习数据分布中的可压缩低维结构并将其转换为紧凑且结构化的表示的能力。这样的表示随后促进了许多下游任务,例如,分类【145, 100, 61, 63, 26】,识别和分割【77, 168, 76, 29, 140】,以及生成【81, 136, 108, 201, 212, 214】。 1.1 表示学习为了更正式地陈述所有这些实践背后的共同问题,人们可以将给定数据集视为高维空间中随机向量x的样本,例如 R^D。通常,x的分布的内在维度远低于周围空间。一般来说,通过学习表示,我们通常指的是学习一个由θ参数化的连续映射,比如 f(·; θ),它将x转换为另一个(通常是低维的)空间中的所谓特征向量z,例如 R^d。通过这样的映射,我们寄希望于:
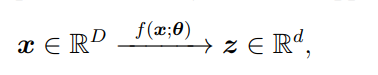
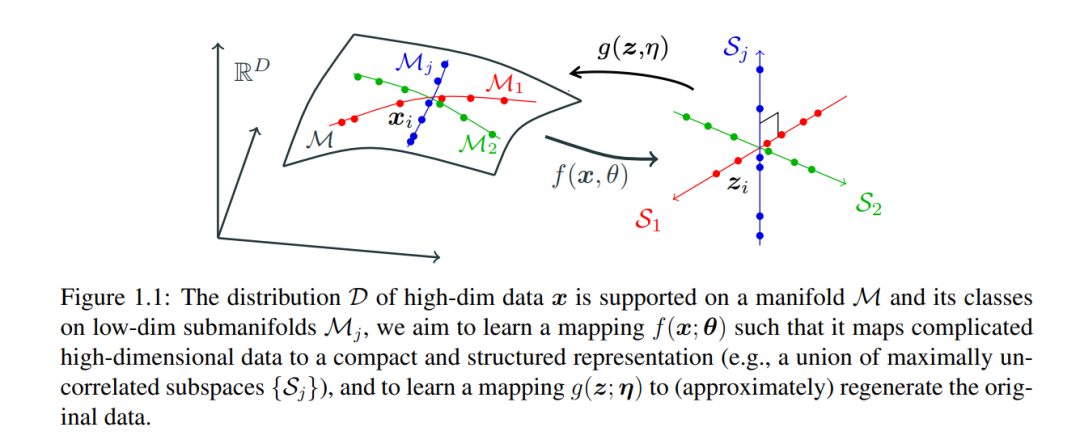
x的低维内在结构被z以更紧凑和结构化的方式识别和表示,以便于促进后续任务如分类或生成。特征z可以被视为原始数据x的(学习得到的)紧凑代码,因此映射f也被称为编码器。在最近的发展中,主要的做法已经变成了通过预训练一个大型深度神经网络先学习一个与任务无关的表示,有时这被称为基础模型【21】。所学到的表示随后可以为多个特定任务进行微调。这已被证明在许多实际任务中更有效和高效,涵盖了多种数据模态,包括语音【203】、语言【26】、自然图像【190】和视觉-语言【201】。注意,在这种情况下的表示学习与其他情况的表示学习大相径庭。在任务不可知的环境下,所学习到的表示z需要对数据x的分布几乎包含所有关键信息。即,所学到的表示z不仅是x内在结构的一个更紧凑和结构化的表示,而且在一定程度上还能恢复x。从概念上讲,验证表示z是否包含了关于x的足够信息的一个有效方法是查看我们能否通过一个(逆)映射g(·;η),通常称为解码器(或生成器),从z恢复x:
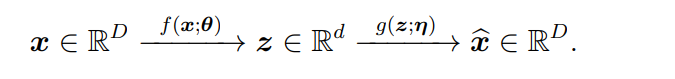
由于编码器f通常是有压缩性和损失性的,我们不应期望逆映射能完全精确恢复x,但是可以近似地通过
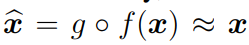
来恢复。我们通常寻求最佳的编码和解码映射,使得解码后的𝑥^x^尽可能接近x,无论是样本层面上,比如通过最小化期望的均方误差,还是在一个放松的分布层面上。我们将上述过程称为压缩编码和解码,或压缩自动编码,如图1.1所示。这一概念与自动编码器的原始目标高度兼容,可以视为经典的主成分分析的一个推广,适用于x的低维结构是线性的情况。 通过过去十一年的巨大实证努力,已经明显地看到深度网络在建模非线性编码和解码映射方面非常有效。深度学习的广泛应用,包括上述提到的,依赖于通过学习f或g的部分或全部来实现这样的编码或解码方案。 1.2 挑战
尽管深度表示学习取得了很多经验性的成功,它们也带来了新的挑战和风险,这些挑战和风险在其在现实世界高风险领域的部署中是关键的。研究人员已经表明:(1)深度模型做出的决策难以解释【167】;(2)大规模基础模型能够记忆并泄露私人个人信息【51】;(3)模型在轻微的对抗性攻击或分布变化下可能会不可预测地失败【240, 206】;(4)模型的校准性很差,特别是在复杂的环境下【86, 191】。在这篇论文中,我们主要关注透明度和隐私。 透明度和可解释性。随着深度学习的发展,许多深度网络架构被提出并用于f或g,从经典的LeNet【150】到AlexNet【146】,再到ResNet【99】,然后是最近的Transformer【250】。尽管这些网络很受欢迎,它们大多是基于经验设计的,并且作为“黑箱”功能逼近器进行训练和使用。设计和训练深度网络的许多流行技术和方法是通过启发式和经验手段开发的,而不是严格的数学原理、建模和分析。从业者在面对任何新数据和任务时不断遇到一系列挑战:应该使用什么架构或特定组件?网络应该有多宽或多深?哪些部分的网络需要训练,哪些可以提前确定?最后但同样重要的是,在网络被训练、学习和测试之后:如何解释操作符的功能;Transformer架构中的多个注意力头和多层感知机(MLP)块的角色和关系是什么【250】?因此,学到的特征表示z的期望属性并没有明确指定或证明,许多启发式措施或损失函数已被提出并用于训练这些模型的与任务无关的表示。 隐私风险。尽管大规模深度学习模型已广泛部署,但在敏感数据上训练这些模型存在重大的隐私和法律风险,这些数据常常包含个人信息或受版权保护的材料【51】。研究表明,如GPT-3这样的生成性基础模型有时可以在被提示时吐露出关于个人和受许可内容的记忆化信息【31】;【177】显示非生成性视觉SSL模型也可以被探测以揭示其训练数据中个别样本的敏感信息;【227, 30】展示了可以提示文本到图像扩散模型生成几乎完美复制某些训练样本。即使在大多数情况下这些模型的训练数据被认为是公开的,一些数据可能是敏感的;此外,还有一些隐私和版权法律适用于即使在这样的公开数据上的模型训练【102】。鉴于这些风险,迫切需要训练能够遵守相关隐私和版权法律的基础模型。
1.3 概述
1.3.1 第一部分:透明的表示学习
表示学习的基本问题和我们将在这部分解决的核心问题是:什么是衡量表示好坏的原理性和有效的指标?从概念上讲,表示z的质量取决于它识别x中对后续任务最相关且充分的信息的能力,以及它表示这些信息的效率。在第二章中,我们提出最大编码率降低(MCR2)的原理,这是一个信息论度量,通过最大化整个数据集与每个个别类别之和的编码率差异,来学习最能区分类别的高维数据中的内在低维结构。 在第三章中,我们介绍了一个广义的编码率函数,并提出了一个称为稀疏率降低的统一目标函数,可以用来无监督地衡量学习到的表示的质量。此外,我们展示了一个类似于变压器的深度架构可以从交替最小化方案的展开中导出,用于稀疏率降低目标。这创建了一个数学上可解释的,类似变压器的架构,称为CRATE(编码率变压器),其中每一层执行交替最小化算法的一个单步,以优化稀疏率降低目标。 第二章是与Kwan Ho Ryan Chan, Chong You, Chaobing Song和Yi Ma【290】的联合工作。第三章是与Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Benjamin D. Haeffele和Yi Ma【289】的联合工作,以及与Tianzhe Chu, Shengbang Tong, Ziyang Wu, Druv Pai, Sam Buchanan和Yi Ma【291】的联合工作。
1.3.2 第二部分:隐私保护的表示学习
在本节中,我们探索了两种缓解表示学习中隐私风险的策略:联邦学习【176】和差分隐私(DP)【65】。联邦学习是一种新兴的机器学习范式,其中多个数据持有者(客户)合作在他们共享的数据集上训练模型。客户只分享从其本地数据集计算出的更新模型和其他统计信息,这确保了他们的原始数据保持本地和私密。差分隐私专注于限制个别训练数据点对训练模型的影响,因此有潜力减少包含敏感信息的单个或少数训练样本的隐私风险。在第四章中,我们研究了使用联邦优化方法学到的表示的有效性,并提出了一种称为Train-Convexify-Train(TCT)的方法,以克服在联邦设置中训练深度、非凸模型时的数据异质性。在第五章中,我们介绍了一种训练基础视觉模型的方法,称为ViP(带差分隐私的视觉变压器),该方法提供DP保证,并展示了高效用差分隐私表示学习的前景。 第四章是与Alexander Wei, Sai Praneeth Karimireddy, Yi Ma和Michael I. Jordan【293】的联合工作。第五章是与Maziar Sanjabi, Yi Ma, Kamalika Chaudhuri和Chuan Guo【292】的联合工作。
1.3.3 理论与实践的联系
这篇论文的一个主要目标是在深度表示学习中桥接理论与实践的差距。理论框架可以提供统一的理解和正式的保证,从而增强深度学习模型的可靠性和可解释性。例如,第二章和第三章中的率降低框架连接了看似不同的方法,如压缩编码/解码,率降低和深度网络架构。另一方面,正如本文所示,将原理化的模型和算法扩展到大规模、真实世界的任务上,可以带来有前景的性能。这是一个将理论与实践相连接并构建可靠和值得信赖的机器学习系统的激动人心的时刻。


