

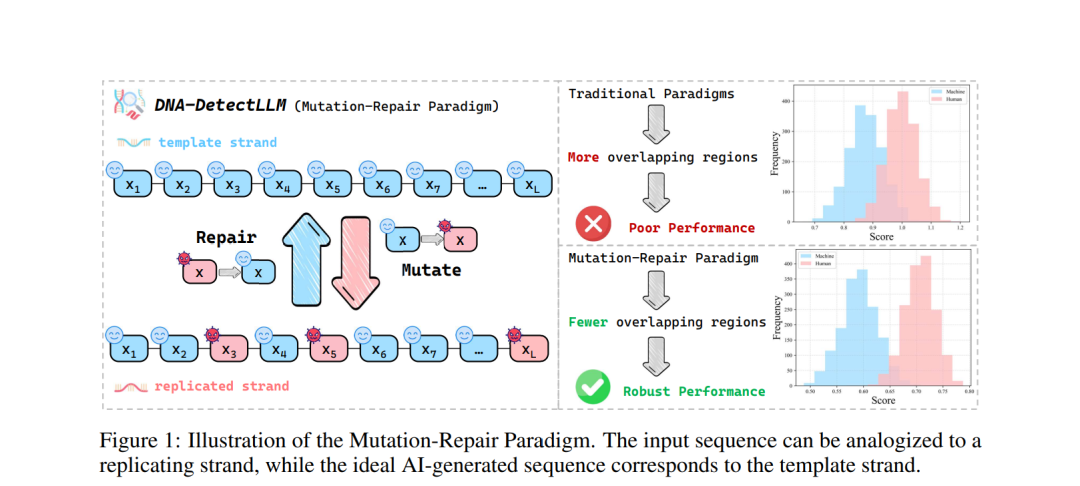
大型语言模型(LLMs)的快速发展模糊了 AI 生成文本与人类撰写文本之间的界限。这一进展带来了社会风险,例如虚假信息、作者身份模糊以及知识产权争议,凸显了开发可靠的 AI 生成文本检测方法的迫切需求。然而,随着生成式语言建模的最新进展,人类撰写文本与 AI 生成文本的特征分布出现显著重叠,从而模糊了分类边界,使得准确检测愈发具有挑战性。为应对上述挑战,我们提出了一种 DNA 启发式视角,通过基于修复的过程直接且可解释地捕捉人类撰写文本与 AI 生成文本的内在差异。在此基础上,我们引入 DNA-DetectLLM,一种零样本检测方法,用于区分 AI 生成与人类撰写的文本。该方法针对每个输入构造一个理想的 AI 生成序列,迭代性地修复非最优 token,并将累计修复开销量化为可解释的检测信号。实验结果表明,该方法在检测性能上达到了最新的水平,并在面对多种对抗攻击与不同输入长度时表现出强鲁棒性。具体而言,DNA-DetectLLM 在多个公共基准数据集上的 AUROC 提升了 5.55%,F1 分数提升了 2.08%。
成为VIP会员查看完整内容
相关内容
相关主题
