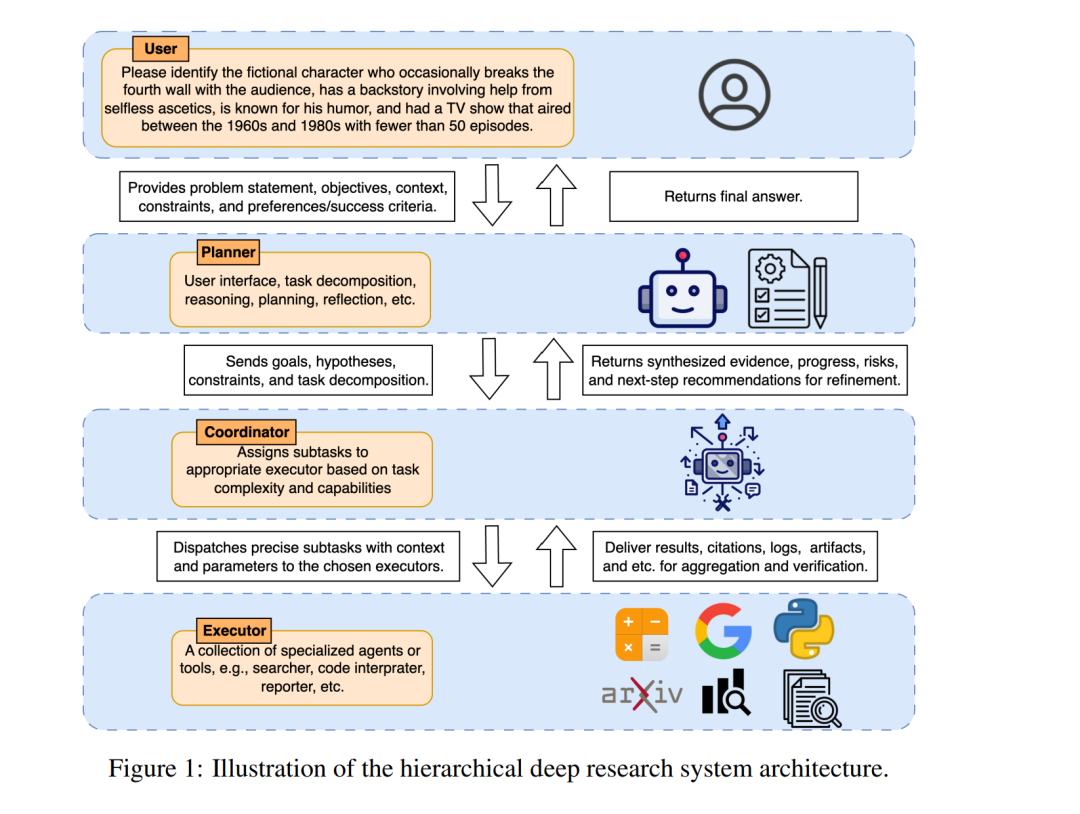
深度研究系统(deep research systems)指能够通过整合推理、开放网络与用户文件的检索、以及工具使用来解决复杂多步任务的智能体型人工智能(agentic AI)。此类系统正逐步演化为分层化的部署架构,包括 规划器(Planner)、协调器(Coordinator) 和 执行器(Executors)。在实践中,将整个堆栈进行端到端训练仍不切实际,因此大多数研究仅针对单一规划器进行训练,并将其连接到核心工具(如搜索、浏览与代码)。 监督微调(SFT)虽然能赋予协议一致性(protocol fidelity),但它存在模仿偏差与暴露偏差,同时未能充分利用环境反馈。基于偏好的对齐方法(如 DPO)则依赖于特定的模式(schema)和代理(proxy),属于离策略(off-policy)范式,在长时程信用分配和多目标权衡上表现不足。SFT 与 DPO 的另一局限在于它们过度依赖人工预定义的决策点与子技能,例如模式设计和标注比较。 相比之下,强化学习(RL)天然契合闭环的、包含工具交互的研究过程。它能够优化轨迹层面的策略,支持探索、恢复行为以及有原则的信用分配,从而减少对人工先验与标注者偏见的依赖。 据我们所知,本综述是首个专门针对深度研究系统中强化学习基础的系统化研究。我们沿三个维度对 DeepSeek-R1 之后的工作进行了梳理与归纳:(i)数据合成与筛选;(ii)面向研究型智能体的强化学习方法,包括稳定性、样本效率、长上下文处理、奖励与信用设计、多目标优化以及多模态集成;(iii)智能体型强化学习的训练系统与框架。我们还讨论了智能体架构与协作机制,以及评测与基准任务,包括最新的问答(QA)、视觉问答(VQA)、长篇综合生成和具备领域约束的工具交互任务。最后,我们总结了反复出现的研究模式,指出了基础设施瓶颈,并提供了实用性建议,以推动利用强化学习训练出健壮且透明的深度研究智能体。 我们整理的相关论文清单可在 GitHub 获取:github.com/wenjunli-0/deepresearch-survey。
监督微调(Supervised Fine-Tuning, SFT;Ouyang et al., 2022;Wei et al., 2022)是初始化深度研究智能体的一种有效方式:它稳定、数据效率高,擅长教授协议一致性(例如工具调用模式、响应格式)以及基本的逐步推理模式。由于 SFT 针对黄金 (x, y) 对进行优化,因此它特别适合于传授局部行为,如查询改写模板、引文风格、论证包装,并能在早期降低方差。然而,正是这些特性限制了其在多轮研究任务中的表现。参考轨迹通常较长、复合且由人工编写;模仿会导致模仿偏差(复制特定的分解方式),而暴露偏差则源自教师强制步骤在推理时掩盖了累积错误。SFT 还未能充分利用环境反馈:它无法直接从工具失败、随机检索或非平稳状态(例如价格、可用性)中学习。简言之,SFT 是获取技能和接口能力的有价值“脚手架”,但不是优化端到端决策质量的有效途径。 基于偏好的方法(如 DPO;Rafailov et al., 2023)可以通过将智能体工作流分解为带标签的步骤(如查询生成、检索选择、综合)并在各阶段学习局部偏好,从而扩展到超越单轮输出。然而,尽管已有若干研究探索通过 DPO 方法训练深度研究智能体(Zhang et al., 2025c;Zhao et al., 2025a;Asai et al., 2023),我们认为这些方法仍存在若干结构性不匹配:首先,DPO 优化的是文本替代而非状态–动作回报:其成对损失作用于基于历史文本的字符串,而未明确绑定到环境状态(工具结果、缓存、预算)或动作语义。这使得信用分配天生短视——只能判断当前步骤哪个片段更优,而无法将下游成败归因于先前的检索或工具使用决策,也无法在部分可观测条件下权衡检索深度与成本/延迟。其次,逐步 DPO 继承了模式和代理依赖:需要人工设计流程分解并生成偏好(通常依赖启发式或另一个 LLM),这引入了标签噪声,并在未见过的任务需要不同分解时表现脆弱。第三,DPO 主要是离策略和离线的:它改进的是固定比较,但无法探索动作与工具结果构成的闭环空间,因此难以学习恢复行为(例如查询返回垃圾结果、站点拒绝访问或价格波动时),也难以适应非平稳环境。最后,多目标需求(准确性、校准、成本、安全)仅通过评估者偏好隐式进入;DPO 并未提供原则性机制来在长时程中聚合向量化奖励。 鉴于 SFT/DPO 的局限性,我们认为强化学习(RL)是训练深度研究智能体实现端到端优化的有前景路径。深度研究本质上要求在闭环、工具丰富的环境中进行轨迹级学习:决定如何分解问题、何时及如何调用工具、哪些证据值得信任、何时终止、以及如何在状态演化过程中权衡准确性、成本与延迟。RL 将系统视为状态–动作上的策略,使其能够利用环境信号进行端到端改进,实现跨多步轨迹的信用分配,并探索替代性策略来优化搜索、工具编排、恢复与综合。 受这一 RL 转向训练深度研究智能体的趋势启发,我们提出据所知首个专门针对深度研究系统中 RL 基础的综述。我们的范围集中在训练:我们分析用于构建深度研究智能体的 RL 方法,而非具体应用任务。我们将相关工作归纳为三条主线: * 数据合成与筛选:生成和整理复杂、高质量训练数据的方法,通常通过合成生成来支持多步推理、检索与工具使用; * 面向研究型智能体的 RL 方法:包括 (i) 扩展基线流程(如 DeepSeek-R1 风格;Guo et al., 2025)以改善稳定性、样本效率、长上下文处理;(ii) 设计奖励与信用分配机制,使得跨多步轨迹的信用能够传播(结果级 vs. 步骤级、复合评审者、回报分解);以及 (iii) 通过多模态大模型(VLMs)集成感知–推理循环; * 智能体型 RL 训练框架:将训练可在长时程内与工具交互的深度研究智能体视为系统问题,综述近期开源基础设施,以揭示瓶颈,总结复现性设计模式,并为可扩展、可复用的训练堆栈提供实用性指导。
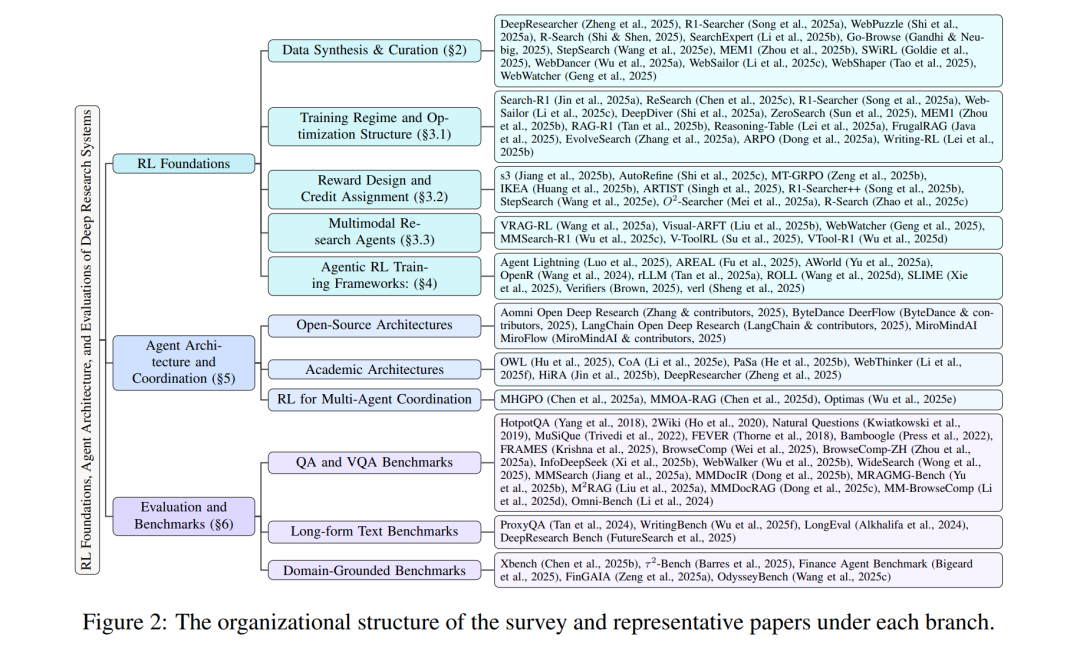
除训练基础外,我们还强调两个跨领域的重要方向: * 智能体架构与协调:层次化、模块化和多智能体设计,增强组合推理与分工; * 评测与基准:用于在整体性、任务丰富、工具交互的情境下评估深度研究系统的框架与数据集。
这些主线共同描绘了一个由 RL 增强的深度研究生态系统的全貌。通过梳理各方向的进展,本综述为新入门的研究者提供概念性路线图,也为有志推动智能体 AI 走向稳健、现实问题解决的学者提供技术参考。图2 展示了我们构建的分类体系与重点论文。 定位与贡献:不同于同时期的其他综述(Huang et al., 2025a;Li et al., 2025a;Xi et al., 2025a;Xu & Peng, 2025;Li et al., 2025g;Zhang et al., 2025d;b),这些工作主要编录系统或泛化性地回顾 RAG 与推理,我们采用了以训练为先、以 RL 为核心的视角:(i) 阐明 SFT/DPO 与闭环、工具交互研究的错配,并论证在规划器端采用端到端 RL 的必要性;(ii) 提出首个专门针对深度研究 RL 基础的分类体系,覆盖数据合成与筛选、研究型 RL 方法(稳定性、样本效率、长上下文处理、奖励/信用设计、多目标权衡、多模态)与训练框架;(iii) 将智能体型 RL 训练视作系统问题,揭示基础设施瓶颈与可复现模式,用于大规模 rollout;(iv) 通过规划器中心的“训练–执行解耦”将训练与部署相联系,并系统化地综述评测与基准。相比其他综述,我们的工作聚焦更窄但深度更足,提供了更系统的数据、算法与基础设施洞见。总体而言,本综述为通过 RL 训练稳健的深度研究智能体提供了一份统一蓝图与可操作性指南。 时间范围与纳入标准:我们回顾了 2025 年 2 月(DeepSeek-R1 之后)至 2025 年 9 月(截稿时间)期间发表的基于 RL 的深度研究系统训练工作,覆盖第 3 节的四大训练支柱以及第 5 节的智能体架构与协调设计,以帮助理解训练好的规划器如何在层次化堆栈中部署。评测与基准亦在范围内:我们引用近年来构建的经典 QA/VQA 和长篇文本(报告式、带引文支撑的综合生成)基准,而领域约束、工具交互的基准则限于 2025 年的成果。我们只纳入在开放网络或类网络工具环境(搜索、浏览、代码执行)中利用 RL 学习策略的研究,不包含仅限 SFT/DPO 的研究。