
【导读】来自东北大学自然语言处理实验室 · 小牛翻译的肖桐 (Tong Xiao) 朱靖波 (Jingbo Zhu)撰写的《机器翻译:统计建模与深度学习方法》,这是一个教程,目的是对机器翻译的统计建模和深度学习方法进行较为系统的介绍。其内容被编纂成书,可以供计算机相关专业高年级本科生及研究生学习之用,亦可作为自然语言处理,特别是机器翻译相关研究人员的参考资料。本书用tex编写,所有源代码均已开放。

作者:肖桐 (Tong Xiao) 朱靖波 (Jingbo Zhu) 单位:东北大学自然语言处理实验室 (NEUNLPLab) / 小牛翻译 (NiuTrans Research) 顾问:姚天顺 (Tianshun Yao) 王宝库 (Baoku Wang) 网站:https://opensource.niutrans.com/mtbook/index.html GitHub:https://github.com/NiuTrans/MTBook
让计算机进行自然语言的翻译是人类长期的梦想,也是人工智能的终极目标之一。自上世纪九十年代起,机器翻译迈入了基于统计建模的时代,发展到今天,深度学习等机器学习方法已经在机器翻译中得到了大量的应用,取得了令人瞩目的进步。
在这个时代背景下,对机器翻译的模型、方法和实现技术进行深入了解是自然语言处理领域研究者和实践者所渴望的。本书全面回顾了近三十年内机器翻译的技术发展历程,并围绕统计建模和深度学习两个主题对机器翻译的技术方法进行了全面介绍。在写作中,笔者力求用朴实的语言和简洁的实例阐述机器翻译的基本模型和方法,同时对相关的技术前沿进行讨论。本书可以供计算机相关专业高年级本科生及研究生学习之用,也可以作为自然语言处理,特别是机器翻译领域相关研究人员的参考资料。
本书共分为七个章节,章节的顺序参考了机器翻译技术发展的时间脉络,同时兼顾了机器翻译知识体系的内在逻辑。各章节的主要内容包括:
- 第一章:机器翻译简介
- 第二章:词法、语法及统计建模基础
- 第三章:基于词的机器翻译模型
- 第四章:基于短语和句法的机器翻译模型
- 第五章:人工神经网络和神经语言建模
- 第六章:神经机器翻译模型
- 第七章:神经机器翻译实战参加一次比赛
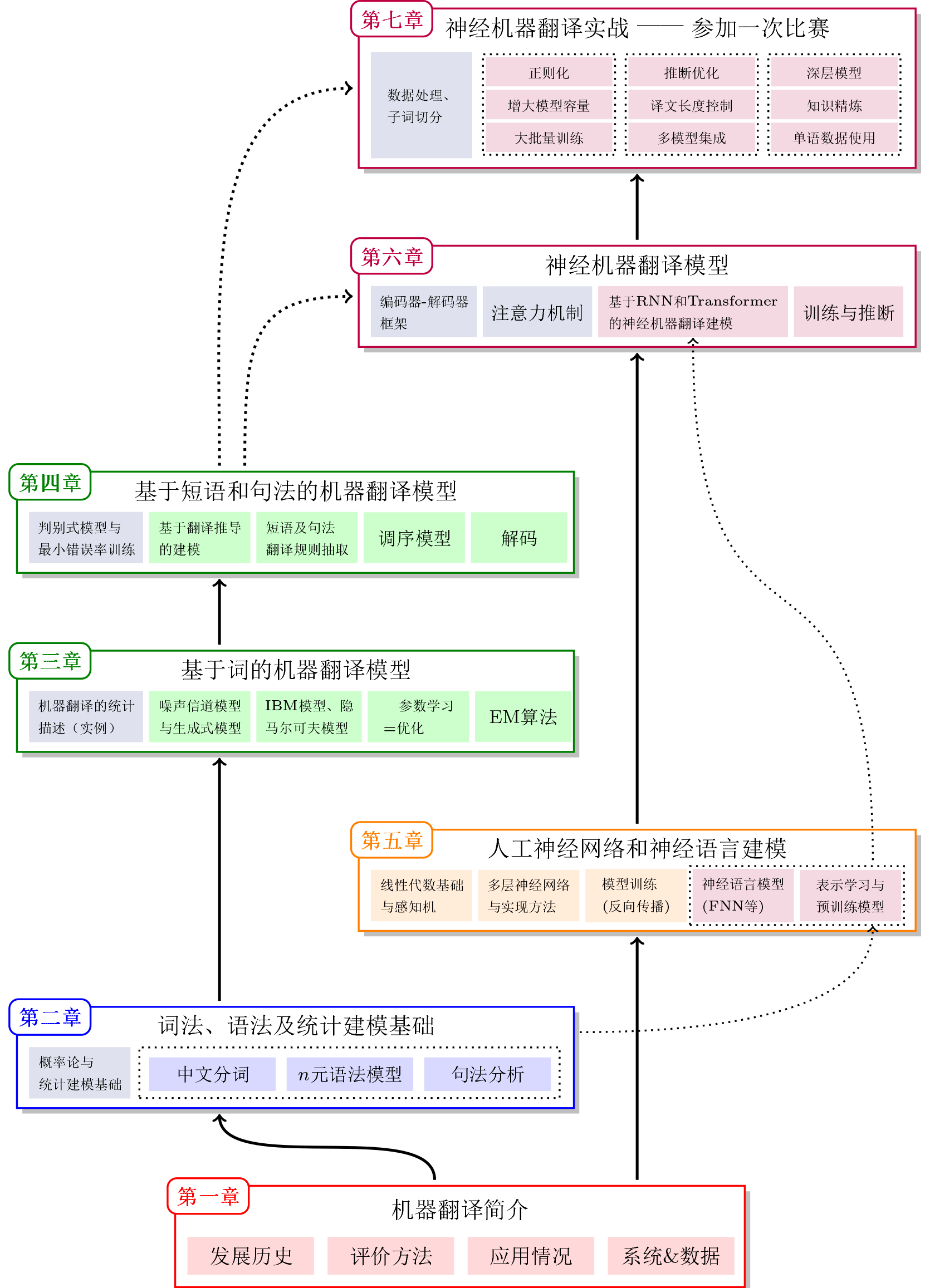
其中,第一章是对机器翻译的整体介绍。第二章和第五章是对统计建模和深度学习方法的介绍,分别建立了两个机器翻译范式的基础知识体系——统计机器翻译和神经机器翻译。统计机器翻译部分(第三、四章)涉及早期的基于单词的翻译模型,以及本世纪初流行的基于短语和句法的翻译模型。神经机器翻译(第六、七章)代表了当今机器翻译的前沿,内容主要涉及了基于端到端表示学习的机器翻译建模方法。特别的,第七章对一些最新的神经机器翻译方法进行了讨论,为相关科学问题的研究和实用系统的开发提供了可落地的思路。图1展示了本书各个章节及核心概念之间的关系。
用最简单的方式阐述机器翻译的基本思想是笔者所期望达到的目标。但是,书中不可避免会使用一些形式化定义和算法的抽象描述,因此,笔者尽所能通过图例进行解释(本书共320张插图)。不过,本书所包含的内容较为广泛,难免会有疏漏,望读者海涵,并指出不当之处。
目录内容:
Part I 机器翻译基础
机器翻译简介 1.1 机器翻译的概念 1.2 机器翻译简史 1.3 机器翻译现状 1.4 机器翻译方法 1.5 翻译质量评价 1.6 机器翻译应用 1.7 开源项目与评测 1.8 推荐学习资源
词法、语法及统计建模基础 2.1 问题概述 2.2 概率论基础 2.3 中文分词 2.4 n-gram 语言模型 2.5 句法分析(短语结构分析) 2.6 小结及深入阅读
Part II 统计机器翻译 基于词的机器翻译模型 3.1 什么是基于词的翻译模型 3.2 构建一个简单的机器翻译系统 3.3 基于词的翻译建模 3.4 IBM 模型 1-2 3.5 IBM 模型 3-5 及隐马尔可夫模型 3.6 问题分析 3.7 小结及深入阅读
基于短语和句法的机器翻译模型 4.1 翻译中的结构信息 4.2 基于短语的翻译模型 4.3 基于层次短语的模型 4.4 基于语言学句法的模型 4.5 小结及深入阅读
Part III 神经机器翻译 人工神经网络和神经语言建模 5.1 深度学习与人工神经网络 5.2 神经网络基础 5.3 神经网络的张量实现 5.4 神经网络的参数训练 5.5 神经语言模型 5.6 小结及深入阅读
神经机器翻译模型
6.1 神经机器翻译的发展简史 6.2 编码器-解码器框架 6.3 基于循环神经网络的翻译模型及注意力机制 6.4 Transformer 6.5 序列到序列问题及应用 6.6 小结及深入阅读
神经机器翻译实战 —— 参加一次比赛 7.1 神经机器翻译并不简单 7.2 数据处理 7.3 建模与训练 7.4 推断 7.5 进阶技术 7.6 小结及深入阅读
Part IV 附录
附录 A:基准数据集和评价工具 附录 B:IBM模型3-5训练方法
参考文献


