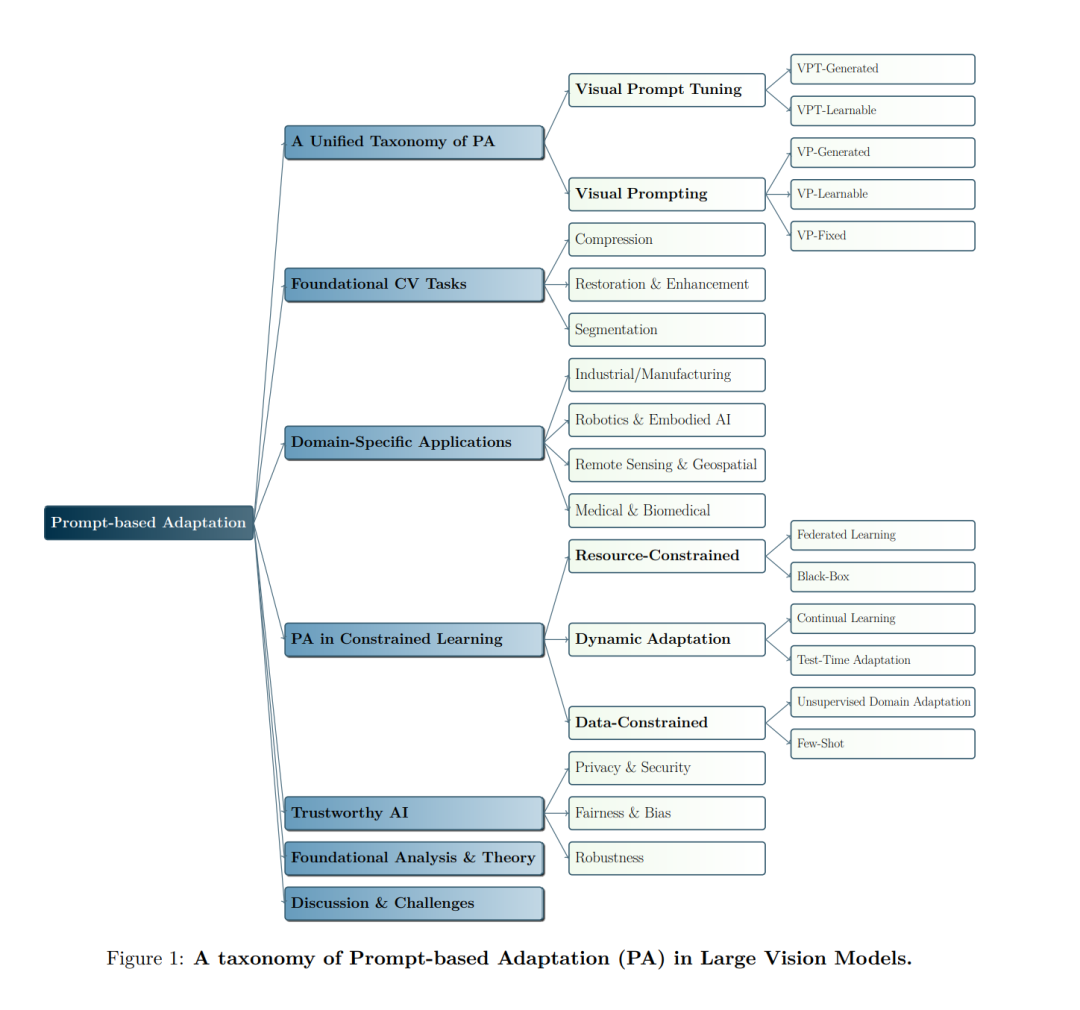
在计算机视觉领域,视觉提示(Visual Prompting, VP)与视觉提示微调(Visual Prompt Tuning, VPT)近年来作为轻量且高效的替代方案,逐渐成为在“预训练—微调(pretrain-then-finetune)”范式下适配大规模视觉模型的重要方法。然而,尽管该方向发展迅速,VP 与 VPT 的概念边界仍然模糊,两者在当前研究中常被交替使用,反映出学界尚缺乏对其方法特征及应用范围的系统区分。 在本综述中,我们从基本原理出发,重新审视 VP 与 VPT 的设计理念,并将其统一纳入一个称为提示式适配(Prompt-based Adaptation, PA)的框架中。我们提出了一套系统的分类方法,将现有研究划分为可学习提示(learnable prompts)、生成式提示(generative prompts)和不可学习提示(non-learnable prompts)三大类,并进一步依据注入粒度(injection granularity)区分为像素级(pixel-level)与标记级(token-level)两种方式。 除核心方法外,我们还系统回顾了 PA 在多个领域的融合与扩展,包括医学影像分析、三维点云处理、视觉-语言任务,以及其在测试时适配(test-time adaptation)与可信 AI(trustworthy AI)中的应用。同时,我们汇总了当前主要的评测基准,并探讨了该方向面临的关键挑战与未来研究趋势。据我们所知,这是首个专门聚焦于 PA 方法与应用的系统性综述,旨在为研究者与从业者提供一条清晰的路线图,以全面理解并探索提示式适配研究的最新进展与未来方向。 有关提示式适配方法的完整汇总,请参阅资源库: 👉 https://github.com/yunbeizhang/Awesome-Visual-Prompt-Tuning
1 引言
以 Vision Transformer(ViT)(Dosovitskiy et al., 2021)和 Swin Transformer(Liu et al., 2021)为代表的大规模视觉模型,已经从根本上改变了计算机视觉的发展格局。这类模型通常在大规模数据集(如 ImageNet-21k(Russakovsky et al., 2015))上进行预训练,以学习可迁移的表征,并在此基础上针对特定下游任务进行微调(Iofinova et al., 2022)(例如 FGVC(Jia et al., 2022)、VTAB-1k(Zhai et al., 2019))。这种策略被称为**“预训练—微调(pretrain-then-finetune)”范式**,能够显著降低对标注数据的依赖(Han et al., 2024)。 然而,随着模型规模的不断扩大(Han et al., 2023),传统的全参数微调(Full Fine-Tuning, FT)方式——即更新全部参数——在计算与存储开销方面愈发昂贵,同时也可能破坏宝贵的预训练知识(Han et al., 2024)。为此,研究者提出了多种参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,其核心思想是在保持大部分参数冻结的情况下,仅调整一小部分可学习参数以实现模型适配。在众多 PEFT 技术中,提示式适配(Prompt-based Adaptation, PA)已经成为一种尤为突出且高效的代表性方法(Jia et al., 2022)。 在本综述中,我们系统性地回顾与分类了近年来 PA 相关算法及其实践应用。与现有综述主要聚焦于多模态或视觉–语言场景不同,我们的工作专注于视觉模型中的提示式适配(PA)。鉴于当前研究社区对 PA 概念定义尚存混乱,本综述的主要贡献在于首次建立起一个结构化且统一的 PA 研究全景图。我们提出了一个系统的分类框架,首先将大量与提示相关的视觉模型研究统一纳入 PA 的总体范畴,然后再依据其算法设计与使用方式的差异进行细致划分。 我们的论文结构如下: 在第 §2 节,我们首先将 PA 定义为“通过在模型不同位置设计输入来调节模型行为的过程”。在该领域内,我们区分出视觉域中的两种核心范式:❶ 视觉提示(Visual Prompting, VP)与 ❷ 视觉提示微调(Visual Prompt Tuning, VPT)。第 §2.2–§2.3 节分别介绍 VP 与 VPT 的算法基础,强调它们在实现参数高效性的不同思想与路径。此区分依据提示的几何嵌入位置——即是修改模型输入还是在层内进行集成。第 §2.4 节讨论 VP 与 VPT 在不同效率层面的优化目标。 在第 §3 节,我们总结 PA 在基础视觉任务中的应用,包括图像分割、恢复与增强、压缩等。在第 §4 节,我们进一步探讨 PA 在高级机器学习任务与多种特定领域(如医学影像、三维点云、机器人等)中的拓展应用。第 §5 节展示 PA 在多种受限场景下的有效性。第 §6 节聚焦 PA 在可信 AI 方向的研究,具体包括鲁棒性(robustness)、公平性与偏差缓解(fairness and bias mitigation)以及隐私与安全(privacy and security)。第 §7 节则深入探讨 PA 的理论基础与行为分析。最后在第 §8 节,我们总结当前亟待解决的挑战与未来发展方向,如安全性考量、训练与推理延迟、稳定性以及实际部署障碍。鉴于 PA 已经在部分真实场景中得到应用,这些讨论对于未来研究具有重要的指导意义。 相关工作(Related Works)
现有与 PA 相关的综述大多关注范围有限,主要集中于多模态或视觉–语言场景。例如,Wu 等(2024d)聚焦于多模态大语言模型(MLLMs)中的视觉提示(VP),围绕视觉指令、提示生成与组合推理进行技术梳理,但未涉及内部像素/标记级注入机制或视觉编码器中的参数高效微调;Gu 等(2023)系统回顾了视觉–语言基础模型(如 CLIP、Flamingo、Stable Diffusion)中的提示工程,重点关注文本端提示与 VL 流程,而非视觉骨干内部的 PA 机制;Lei 等(2024)从 AIGC 视角综述了计算机视觉中的提示学习,基于视觉–语言模型与生成模型展开,但未按注入粒度或受限范式进行统一整理。 此外,《Model Reprogramming: Resource-Efficient Cross-Domain Machine Learning》(Chen, 2022)为 VP 提供了早期理论基础,将像素空间变换视为可学习的输入重编程层,用于跨域迁移学习,启发了后续的参数高效提示方法。最近,Ye 等(2025)将讨论扩展至大规模视觉与多模态模型,追踪了 VP 技术从像素级操控到基础模型级适配的演化过程。 与这些研究不同,我们注意到文本侧与视觉侧提示方法在目标与机制上存在显著差异,因此本综述专注于视觉模型中的提示式适配(PA),并提出一个统一的分类体系,对此前模糊的 PA 定义进行了重新界定与剖析。我们进一步依据生成机制(可学习 / 生成式 / 不可学习)与注入粒度(像素级 / 标记级)进行分类。在方法论之外,我们还系统化整理了多种受限学习范式(包括小样本 / 零样本、测试时适配、持续学习、黑箱学习、前向推理、联邦学习等)、领域应用(医学、遥感、机器人、工业等)以及基础性分析(行为证据、效率与理论),从**部署导向(deployment-oriented)**角度提供了前所未有的系统性综述框架。