
论文作者包括来自上海交通大学的朱家琛、芮仁婷、单榕、郑琮珉、西云佳、林江浩、刘卫文、俞勇、张伟楠,以及华为诺亚研究所的朱梦辉、陈渤、唐睿明。 本文第一作者是朱家琛,上海交通大学博士生,主要研究兴趣集中在大模型推理,个性化 Agent。本文通讯作者是张伟楠,上海交通大学教授,研究方向包含强化学习、数据科学、机器人控制、推荐搜索等。 自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。 不同于以往只会对话的 LLM 机器人,AI Agent 能够接入互联网、调用各类 API,还能根据真实环境反馈灵活调整策略。AI Agent 因此具备了感知环境和自主决策的能力,已经突破了传统 “问答模式” 的限制,能够主动执行任务、应对各种复杂场景,真正成为用户身边可靠的智能助手。 在这股 AI Agent 浪潮中,每个人都可以有属于自己的 AI Agent。而如何衡量自己的 AI Agent 是否足够强大呢?海量的 Agent 评测方式层出不穷,你是否挑得眼花缭乱?如何在这千军万马中挑选出最适合你的测评方式呢?作为 AI Agent 的开发者,你是否也在思考该从哪个角度来提升你的 “秘密武器”,在这场激烈的 AI Agent 大战中脱颖而出? 因此,这引出了一个顺理成章的问题: AI Agent 到底和传统聊天机器人有何本质区别?又该如何科学评测 AI Agent?

论文标题:Evolutionary Perspectives on the Evaluation of LLM-Based AI Agents: A Comprehensive Survey * 论文链接:https://arxiv.org/pdf/2506.11102
一、从 LLM Chatbot 到 AI Agent
论文指出,AI Agent 的出现是 AI 发展的新阶段。它们不仅仅回复人类对话,还具备了五个维度的进化:
- 复杂环境:Agent 不再局限于单一对话场景,可以与代码库、网页、操作系统、移动端、科学实验等各类环境交互。
- 多源指令:Agent 不只接收人工输入,还能结合自我反思、智能体协作等多源指令。
- 动态反馈:Agent 运行于连续多样的反馈环境,可基于指标、奖励等动态反馈持续优化自身能力,不再局限于被动对话纠正。
- 多模态:Agent 拥有跨模态处理能力,能理解文本、视觉、听觉等多种数据。
- 高级能力:随着外部环境复杂化,Agent 具备了复杂规划、持久记忆、自主推理等能力,实现从被动响应到自主执行的跃迁。
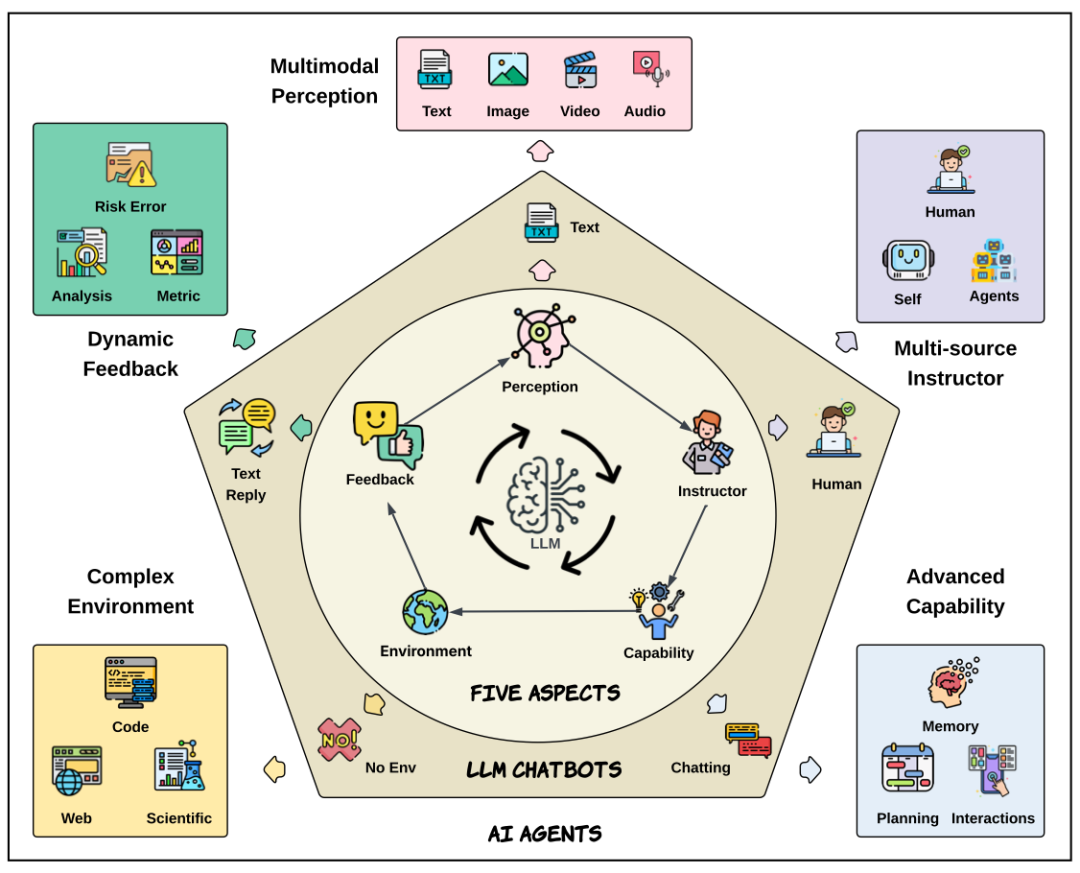
图 1:AI Agent 与 LLM Chatbot 演化的五个维度。
LLM Chatbot 向 AI Agent 的演进,背后主要受两方面推动:一是外部环境的日益复杂,二是内部能力的不断提升。复杂的外部环境促使 Agent 不断成长,而 Agent 能力的提升又推动人们去探索更具挑战性的应用场景。正是这种内外循环、相互促进,成为现代 AI Agent 加速进化的根本动力。因此,论文的总体框架如图 2 所示:我们系统梳理了现有 AI Agent 评测基准,提出 “环境 - 能力” 两方面的分类学。随后进行趋势讨论,对 Agent 评测方法演化趋势的讨论,涉及环境角度,Agent 角度,评估者角度,指标角度,并最终提出基准选择的方法论。
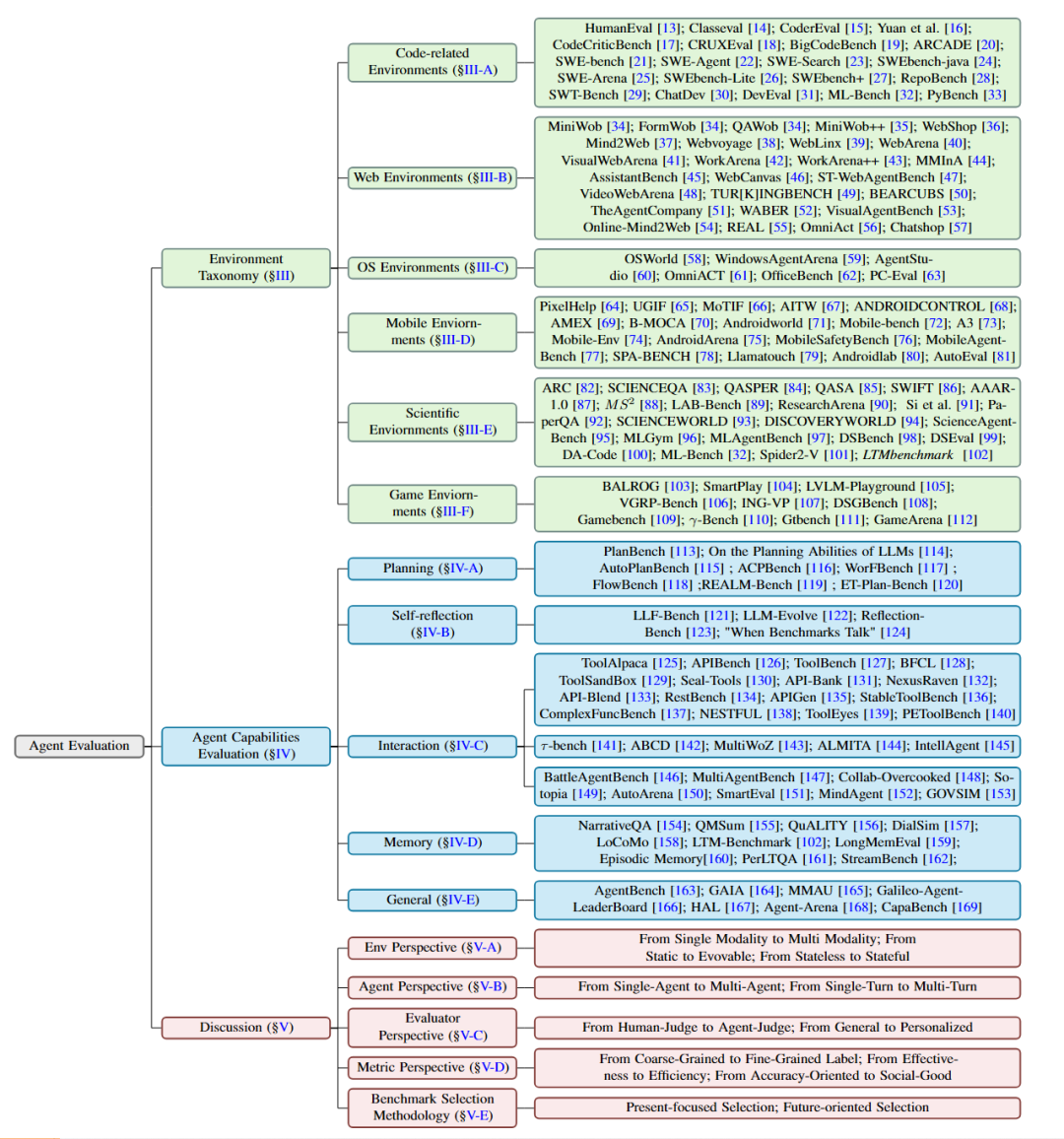
图 2:论文框架总览
二、评测框架与基准盘点 面对 Agent 能力的指数级扩展,原有的聊天机器人评测方法已无法胜任。论文系统梳理了现有 AI Agent 评测基准,提出 “环境 - 能力” 两方面的分类:
- 环境维度:细分为代码、网页、操作系统、移动端、科学、游戏等环境。
- 能力维度:涵盖规划、自我反省、交互、记忆等高级能力。 针对每种环境与能力,论文整理了当前最具代表性的评测基准,并梳理出一套 “实用属性表”,帮助研究者在眼花缭乱的 benchmark 中挑选符合要求的。 以表 1 为例,我们列出了我们认为最重要的属性:真实性,离线 / 在线,评测者,输入模态,主要挑战。并将所有 web 环境的基准归到这些属性中。
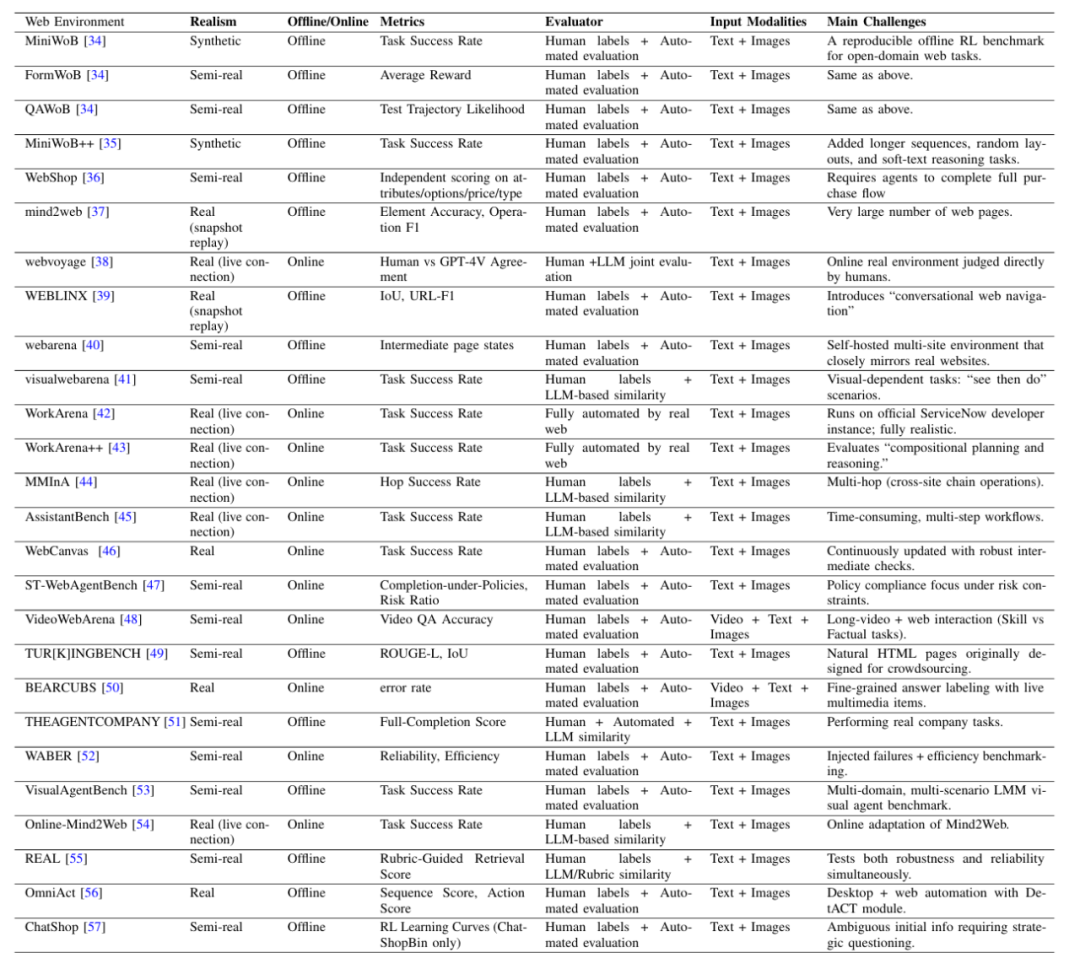
表 1:Web 环境下的 Agent 基准以及其各类属性
三、AI Agent 评测方法的进化趋势
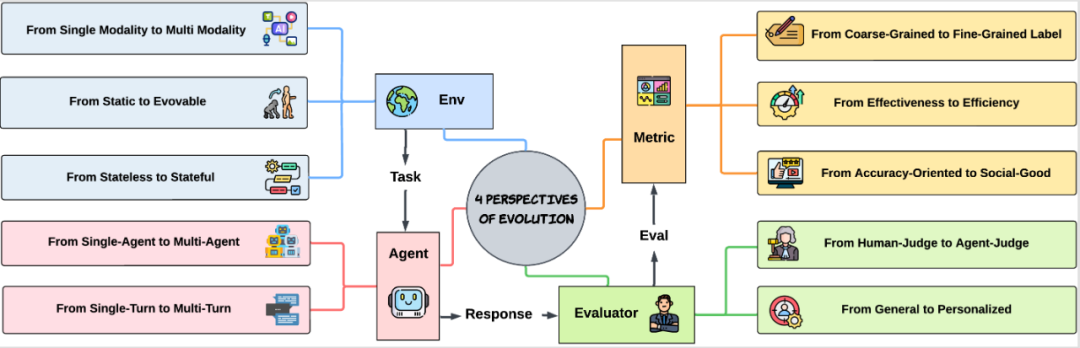
图 3:AI Agent 评测未来演化的四个视角。 论文深刻总结了 AI Agent 评测方法的未来趋势,不再只是 “比谁答得对”,而是从四个关键视角全面升级:
- 环境视角:从单模态到多模态、从静态到动态、从少状态到多状态。 最初,Agent 评测只围绕文本展开,如今则逐渐扩展到图片、音频、视频等多种信息形式。静态的数据集已经不能满足需求,动态、实时更新的真实环境成为新常态。同时,评测方式也在转变,开始关注智能体在连续任务过程中的表现和调整,而不再只看最终结果。
- 智能体视角:从单 Agent 到多 Agent、从单轮到多轮互动。 新一代评测不仅关注单个 Agent 的能力,更重视多个 Agent 间的协作与博弈。与此同时,任务由简单的一问一答,演化为多轮对话、持续推理和复杂任务链,考验 Agent 的全局规划与长期记忆。
- 评测者视角:从人工到 AI 自动评测、从通用到个性化。 AI 不再只是被动接受人类评分,越来越多的 Agent 可以自动评判同行,实现规模化、自主化评测。同时,未来的评测将更加关注个性化,衡量 Agent 是否能针对不同用户给出个性化的服务。
- 指标视角:从粗粒度到细粒度,从关注正确率到关注效率、安全与社会价值。 单一的正确率已无法反映 Agent 真实能力。未来评测更强调任务效率、细粒度决策的质量、安全性和伦理性,比如防止误操作、保障用户利益、促进社会善意等。
四、行动指南: 如何选择合适的 Agent 评测基准 面对 AI Agent 的快速发展,论文围绕 “如何用演化视角系统评估 AI Agent” 这一核心问题,提出了一套二阶段的基准选择方法论: 第一阶段:从当下出发。 根据实际任务环境和 Agent 能力,先锁定对应的环境和能力分类(图 2),从属性表(表 1)中精准匹配最适用的评测基准。例如,开发者 Z 开发了能预订航班和酒店的 Agent,应优先考虑 Web 环境和交互能力,选用如 WebVoyager 和 ComplexFuncBench 等基准进行测试。 第二阶段:为未来考虑。 结合评测进化趋势(图 3),开发者 Z 应持续关注环境变化、多模态挑战和社会价值等新维度。随着产品商业化,适时引入动态环境(如 BFCL)、安全性(如 ST WebAgentBench)和个性化(如 PeToolBench)等多样化评测基准,确保 Agent 持续优化与进化。
结语 AI Agent 正在从 “会对话” 进化为 “会行动”,推动人工智能迈向更智能、更自主、更有价值的下一个时代。而如何科学评测 AI Agent,是驱动这一切的关键。如果读者你也关心如何评测新颖的 AI Agent,我们的综述值得一读。